### CUDA
CUDA Learning.
#@author: gr
#@date: 2014-04-06
#@email: forgerui@gmail.com
1. Introduction
CPU和GPU的区别。GPU拥有更多的核心数,可以对简单逻辑、大量数据进行并行计算,大大提高了计算能力。
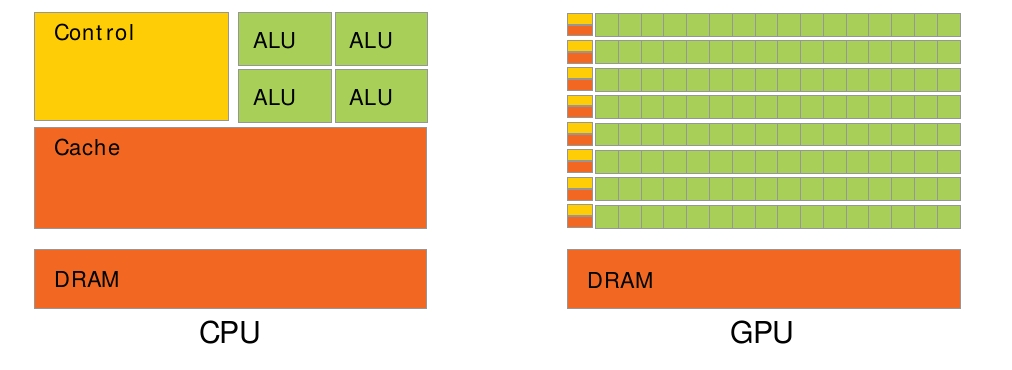
有更多的SM会有更好的性能。
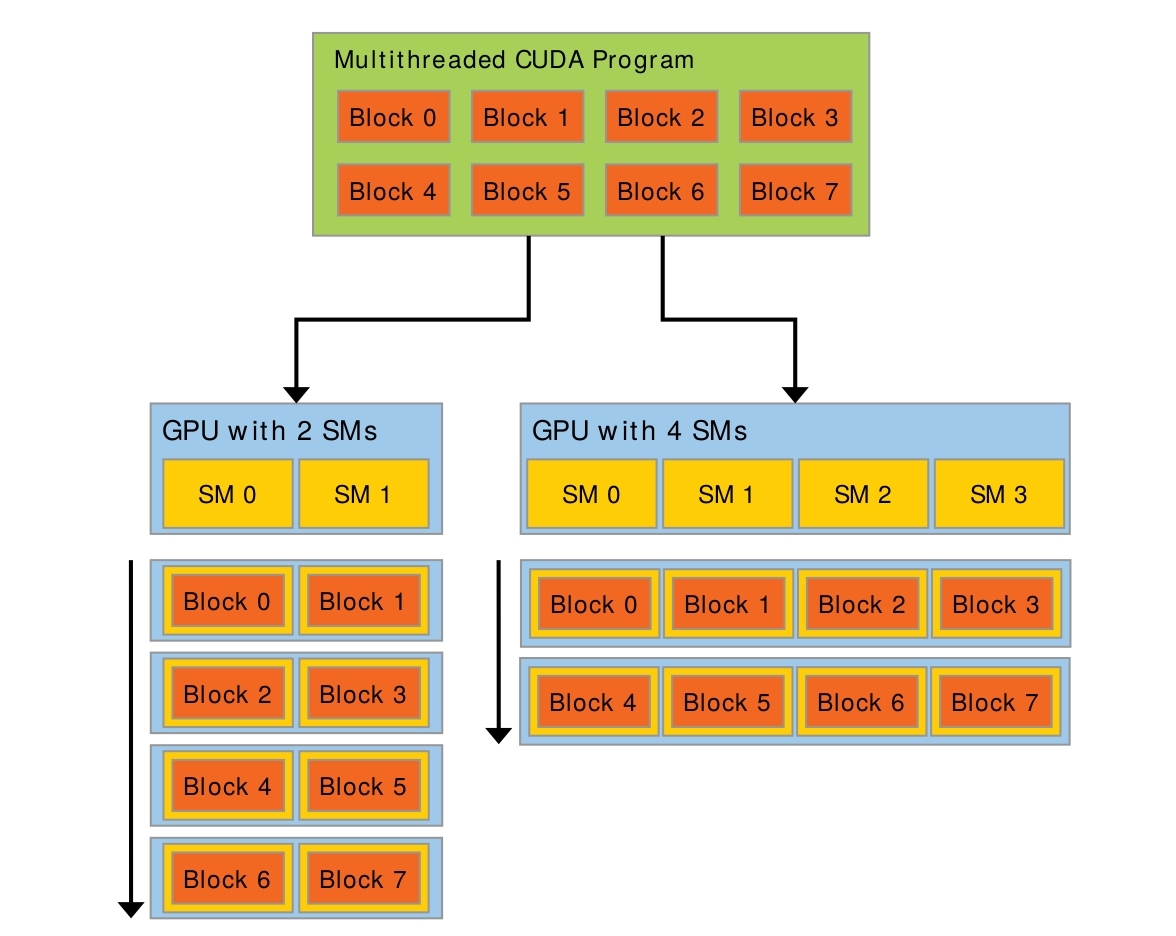
2. General
1.1. kernel
核函数通过__global__声明。通过<<<...>>>指定执行的线程数。
__global__ void VecAdd(float* A, float* B, float* C)
{
int i = threadIdx.x;
C[i] = A[i] + B[i];
}
int main()
{
...
// Kernel invocation with N threads
VecAdd<<<1, N>>>(A, B, C);
...
}
1.2. Thread, Block, Grid
一次任务就可以算是一个Grid。在Grid里,可以分成几块Block。而Block里就是每个要处理的Thread。
核函数的形式是kernel<<<G, B, Ns, S>>>(...)。
G代表grid的尺寸,可以是三维的,也可以是int。
B是线程块block的大小。
Ns是每个block除了静态分配的shared memory之外,最多能动态分配的shared memory大小。
S是一个cudaStream_t类型的可选参数,默认值为0, 表示核函数处于哪个流中。
目前的GPU,block中线程的大小最大为1024, 一般取256,而\(G = N / B\),\(N\) 是线程总数,但我们需要对\(G\)的计算结果取上整,我们这里不是使用ceil函数,而是使用下面的式子\(G = (N + B - 1) / B\)来达到取上整的目的。
取上整会导致启动的线程总数大于需要的整数,我们可以利用条件进行检查。
if (tid < N)
c[tid] = a[tid] + b[tid]
上面实现的一个问题是,G同样也是有限制大小的,如果(N+B-1)/B大于65535时,核函数调用kernel<<<G, B>>>就会出错。为了确保不会启动过多的线程块,可以将线程块固定为某个确定的值。如下,取<<<256, 256>>>,让每个线程多做几个任务:
__global__ void add (int *a, int *b, int *c){
int tid = threadIdx.x + blockIdx.x * blockDim.x;
while (tid < N){
c[tid] = a[tid] + b[tid];
// blockDim.x * gridDim.x表示的是启动的总共线程数量
tid += blockDim.x * gridDim.x;
}
}
add<<<256, 256>>>(d_a, d_b, d_c);
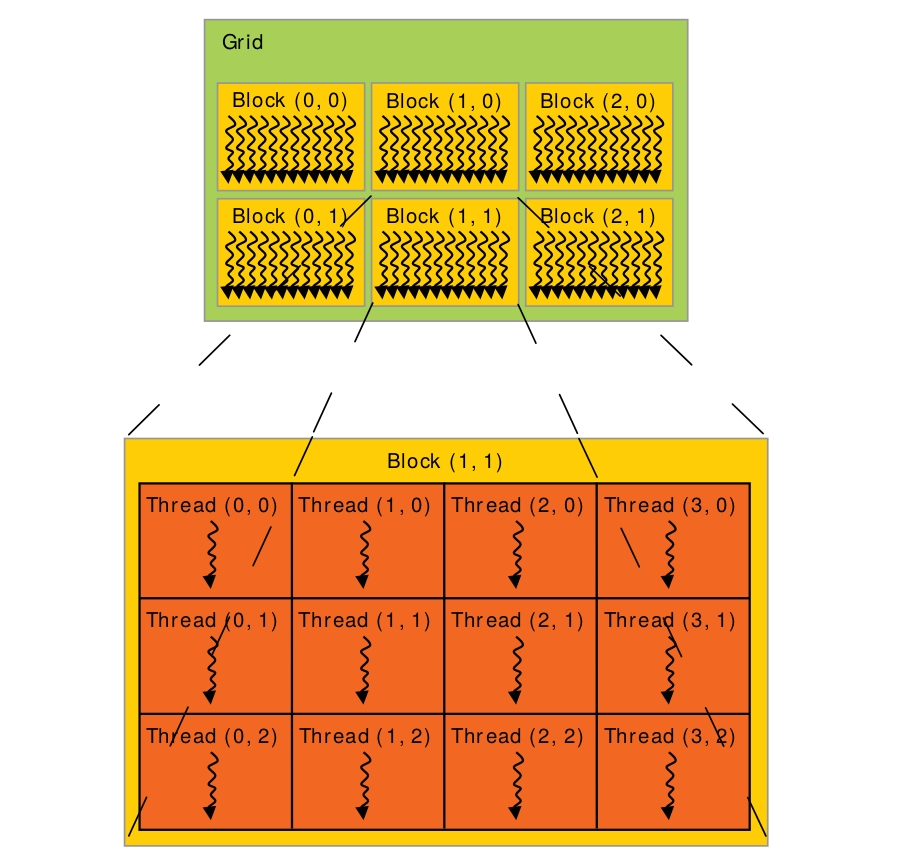
核函数中的一些内置变量:
gridDim: 线程格的尺寸。上图中,gridDim = (3, 2, 1)
blockIdx: 线程块的索引值。上图中,Block(1, 1)的索引值blockIdx = (1, 1, 1)
blockDim: 线程块的尺寸。上图中,blockDim = (4, 3, 1)
threadIdx: 线程索引值。上图中,Thread(1, 1)的索引值threadIdx = (1, 1, 1)
代码如下:
void main(){
int a;
}
__global__ void MatAdd(float** A, float** B, float** C, int N)
{
int i = blockIdx.x * blockDim.x + threadIdx.x;
int j = blockIdx.y * blockDim.y + threadIdx.y;
if (i < N && j < N)
C[i][j] = A[i][j] + B[i][j];
}
int main()
{
...
// Kernel invocation
dim3 threadsPerBlock(16, 16);
dim3 numBlocks(N / threadsPerBlock.x, N / threadsPerBlock.y);
MatAdd<<<numBlocks, threadsPerBlock>>>(A, B, C, N);
...
}
流的并行处理:
cudaStream_t stream[5];
for(int i = 0; i<5; i++)
{
cudaStreamCreate(&stream[i]); //创建流
}
// Launch a kernel on the GPU with one thread for each element.
for(int i = 0; i<5; i++)
{
addKernel<<<1, 1, 0, stream[i]>>>(dev_c+i, dev_a+i, dev_b+i); //执行流
}
cudaDeviceSynchronize();
for(int i = 0;i<5;i++)
{
cudaStreamDestroy(stream[i]); //销毁流
}
进行规约(Reduction)的代码:
int i = blockDim.x / 2;
cacheIndex = threadIdx.x;
while (i != 0){
if (cacheIndex < i)
cache[cacheIndex] += cache[cacheIndex + i];
__syncthreads();
i /= 2;
}
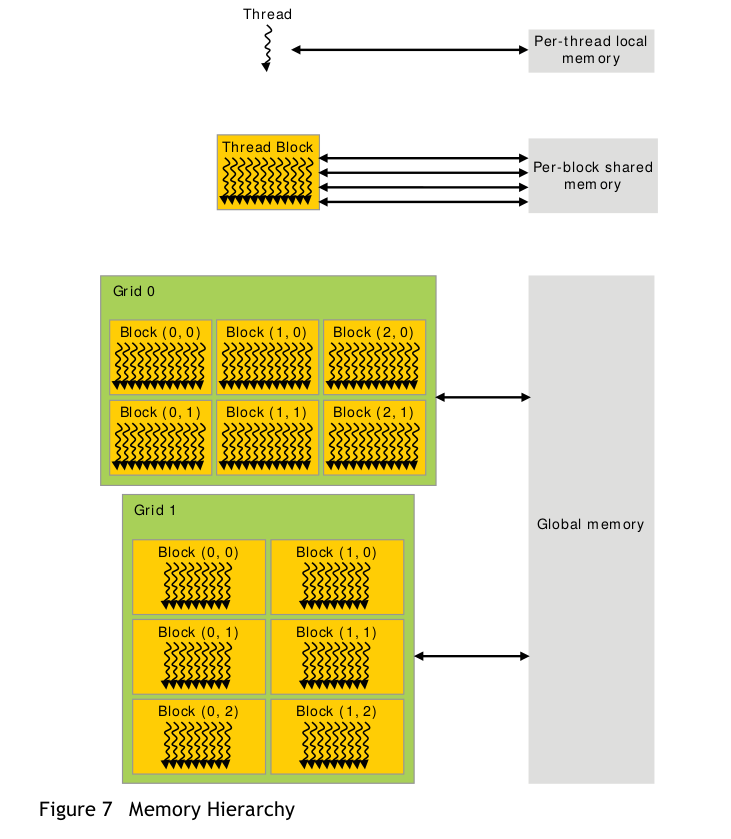
3. Memory
**register: ** 线程私有,有缓存,比较快。
**local memory: ** 线程私有,无缓存。
**shared memory: ** block内线程共享,速度较快。
**global memory: ** 线程共享,较慢。
**constant memory: ** 只读,常量存储,线程共享,有缓存。
**texture memory: ** 只读,具有纹理缓存。
4. cuda-gdb
编译时需要加上调试选项:
nvcc -g -G test.cu -o test
cuda-gdb的使用和gdb很多是一样的,列出一些cuda特有的命令:
thread: 列出当前的主机线程
cuda thread: 显示当前活跃的GPU线程
Note
- 如果核函数访问内存出现问题,因为GPU有着完善的内存管理机制,会强行结束所有违反内存访问规则的进程,后面的代码也就不会执行。
### CUDA的更多相关文章
- CUDA[2] Hello,World
Section 0:Hello,World 这次我们亲自尝试一下如何用粗(CU)大(DA)写程序 CUDA最新版本是7.5,然而即使是最新版本也不兼容VS2015 ...推荐使用VS2012 进入VS ...
- CUDA[1] Introductory
Section 0 :Induction of CUDA CUDA是啥?CUDA®: A General-Purpose Parallel Computing Platform and Program ...
- Couldn't open CUDA library cublas64_80.dll etc. tensorflow-gpu on windows
I c:\tf_jenkins\home\workspace\release-win\device\gpu\os\windows\tensorflow\stream_executor\dso_load ...
- ubuntu 16.04 + N驱动安装 +CUDA+Qt5 + opencv
Nvidia driver installation(after download XX.run installation file) 1. ctrl+Alt+F1 //go to virtual ...
- 手把手教你搭建深度学习平台——避坑安装theano+CUDA
python有多混乱我就不多说了.这个混论不仅是指整个python市场混乱,更混乱的还有python的各种附加依赖包.为了一劳永逸解决python的各种依赖包对深度学习造成的影响,本文中采用pytho ...
- [CUDA] CUDA to DL
又是一枚祖国的骚年,阅览做做笔记:http://www.cnblogs.com/neopenx/p/4643705.html 这里只是一些基础知识.帮助理解DL tool的实现. “这也是深度学习带来 ...
- 基于Ubuntu14.04系统的nvidia tesla K40驱动和cuda 7.5安装笔记
基于Ubuntu14.04系统的nvidia tesla K40驱动和cuda 7.5安装笔记 飞翔的蜘蛛人 注1:本人新手,文章中不准确的地方,欢迎批评指正 注2:知识储备应达到Linux入门级水平 ...
- CUDA程序设计(一)
为什么需要GPU 几年前我启动并主导了一个项目,当时还在谷歌,这个项目叫谷歌大脑.该项目利用谷歌的计算基础设施来构建神经网络. 规模大概比之前的神经网络扩大了一百倍,我们的方法是用约一千台电脑.这确实 ...
- 使用 CUDA范例精解通用GPU编程 配套程序的方法
用vs新建一个cuda的项目,然后将系统自动生成的那个.cu里头的内容,除了头文件引用外,全部替代成先有代码的内容. 然后程序就能跑了. 因为新建的是cuda的项目,所以所有的头文件和库的引用系统都会 ...
- CUDA代码移植
如果CUDA的代码移植,一个是要 include文件夹对不对,这个是.h文件能否找到的关键,另一个就是lib,这个是.lib文件能否找到的关键.具体检查地方,见下头. include: lib:
随机推荐
- [iOS基础控件 - bugs]
1.不能呼出iOS模拟器键盘 Can't find keyplane that supports type 4 for keyboard iPhone-Portrait-NumberPad 解决:Ha ...
- [OC Foundation框架 - 4] NSString的导出
void exportString() { NSString *str = @"Hello, 坑爹"; NSString *path = @"/Users/hello ...
- Android模拟器访问本地的apache tomcat服务
1. 在官网http://tomcat.apache.org/上下载tomcat,根据自己的电脑下载相应的文件 2.将apache-tomcat-6.0.37-windows-x64.zip包解压到本 ...
- 锋利的jquery第二版学习笔记
jquery系统学习笔记 一.初识:jquery的优势:1.轻量级(压缩后不到30KB)2.强大的选择器(支持css1.css2选择器的全部 css3的大部分 以及一些独创的 加入插件的话还可支持XP ...
- 在C#中实现软件自动升级
在C#中实现软件自动升级 winform程序相对web程序而言,功能更强大,编程更方便,但软件更新却相当麻烦,要到客户端一台一台地升级,本文结合实际情况,通过软件实现自动升级,弥补了这一缺陷,有较好的 ...
- 解决SenTestingKit/SenTestingKit.h: No such file or directory
在一个iOS项目中引入了单元测试,感觉项目间的依赖关系有些乱,就建了一个新的Project,再把原来的.h和.m加进去,编译时竟然出现“SenTestingKit/SenTestingKit.h: N ...
- zabbix邮件报警脚本(Python)
#!/usr/bin/python #coding:utf-8 import smtplib from email.mime.text import MIMEText import sys mail_ ...
- 利用UIBezierPath实现一个带圆角的视图
- (void)drawRect:(CGRect)rect { // draw a box with rounded corners to fill the view - UIBezierPath * ...
- JBoss7快速入门
国内私募机构九鼎控股打造APP,来就送 20元现金领取地址:http://jdb.jiudingcapital.com/phone.html内部邀请码:C8E245J (不写邀请码,没有现金送)国内私 ...
- Codeforces Round #200 (Div. 1)D. Water Tree dfs序
D. Water Tree Time Limit: 1 Sec Memory Limit: 256 MB 题目连接 http://codeforces.com/contest/343/problem/ ...