《Using Python to Access Web Data》 Week5 Web Services and XML 课堂笔记
Coursera课程《Using Python to Access Web Data》 密歇根大学
Week5 Web Services and XML
13.1 Data on the Web
在网络上我们需要用一种固定的模板进行交流,python将我们的内容serialize成这种模板,然后再de-serialize让另外一种语言读懂。
现在有两种交流模板:XML和JSON。
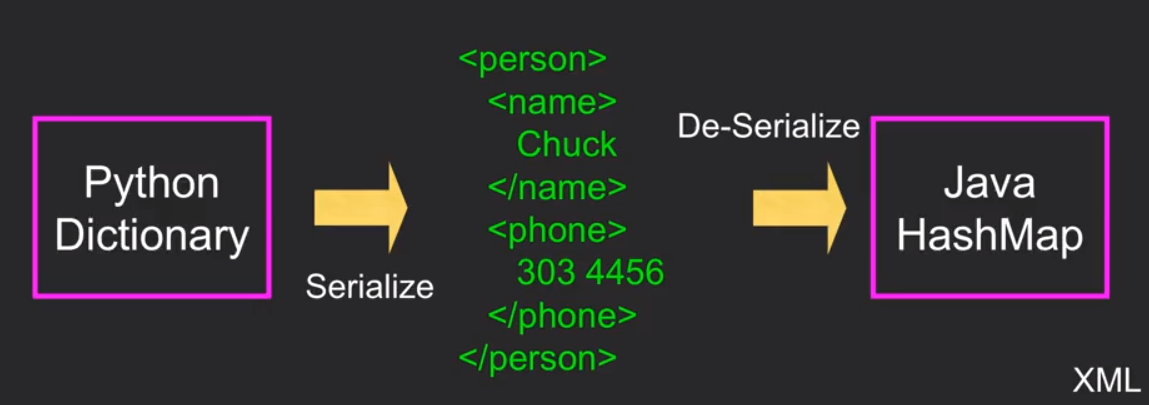

13.2 Extensible Markup Language(XML)
XML也就是可扩展标记语言(Extensible Markup Language),很类似HTML。
<people>
<person>
<name>Chuck</name>
<phone>303 4456</phone>
</person>
<person>
<name>Noah</name>
<phone>622 7421</phone>
</person>
</people>
和HTML一样,它有start tag和end tag。
而<name>Chuck</name>这种叫Simple Element,<person></person>这种叫Complex Element。

而对于XML来说,空格和缩进并不是很有关系。缩进仅仅是为了更好的阅读。
XML的术语
- 标签(Tag)表示元素的起始。
- 属性(Attribute)- 在XML的开放标签中的关键词或值
- Serialize/De-Serialize - 将数据从一种程序转换到一种通用模板中的过程
XML是树形结构的。
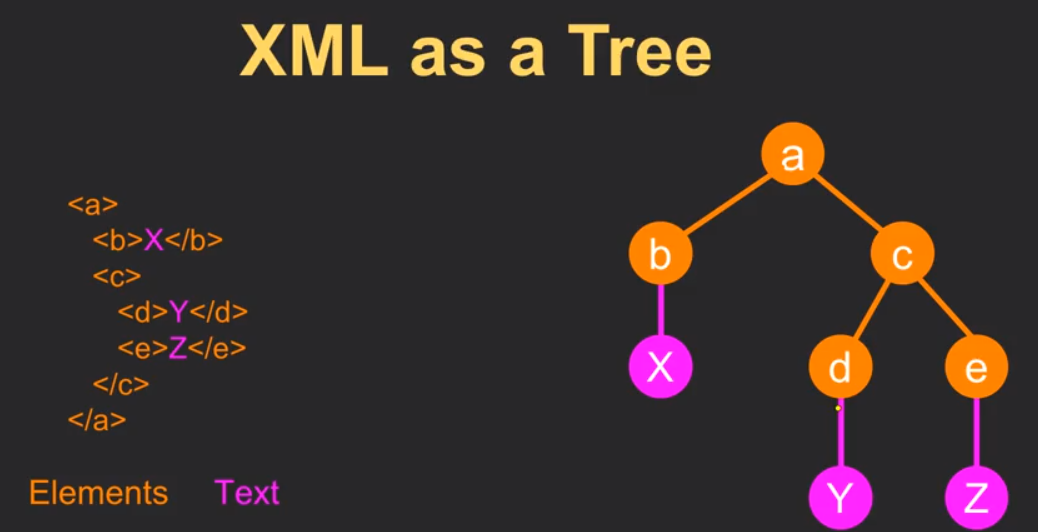
所以我们如果要把XML解析为路径。上图中的结果就是。
/a/b为X,/a/c/d为Y,/a/c/e为Z。
13.3 XML Schema
XML纲要描述了一个合法的XML文档的模板。

目前有很多种XML纲要语言,比如说Document Type Definition(DTD), Standard Generalized Markup Language(ISO 8879:1986 SGML), XML Schema from W3C - (XSD)。
以下就是XSD的结构。

XSD的限制。

比如说上图的蓝色部分,minOccurs="1" maxOccurs="1"意思就是这个tag只能出现一次,而且必须出现一次。而橙色部分minOccurs="0" maxOccurs="10"也就是说,这个tag可以出现大于等于0小于等于10次。
XSD的数据类型有string, date, date Time, decimal, integer五种类型。

13.4 Parsing XML
import xml.etree.ElementTree as ET
data = '''<person>
<name>Chuck</name>
<phone type="int1">
+1 734 303 4456
</phone>
<email hide="yes"/>
</person>'''
tree = ET.fromstring(data)
print('Name:', tree.find('name').text)
print('Attr:', tree.find('email').get('hide'))
fromstring()这个函数是把XML组织成树状结构,方便后面使用find()查找。
以下是更复杂的一个XML文档情况。
import xml.etree.ElementTree as ET
input = '''<stuff>
<users>
<user x="2">
<id>001</id>
<name>Chuck</name>
</user>
<user x="7">
<id>009</id>
<name>Brent</name>
</user>
</users>
</stuff>'''
stuff = ET.fromstring(input)
lst = stuff.findall('users/user')
print('User count:', len(lst))
for item in lst:
print('Name', item.find('name').text)
print('Id', item.find('id').text)
print('Attribute', item.get("x"))
作业代码
import urllib.request, urllib.parse, urllib.error
import xml.etree.ElementTree as ET
url = input('Enter location: ')
print('Retrieving', url)
uh = urllib.request.urlopen(url)
data = uh.read()
print('Retrieved', len(data), 'characters')
tree = ET.fromstring(data)
results = tree.findall('comments/comment')
sum = 0
count = 0
for item in results:
sum = sum + int(item.find('count').text)
count += 1
print('count:',count)
print('sum:',sum)
《Using Python to Access Web Data》 Week5 Web Services and XML 课堂笔记的更多相关文章
- 《Using Python to Access Web Data》 Week3 Networks and Sockets 课堂笔记
Coursera课程<Using Python to Access Web Data> 密歇根大学 Week3 Networks and Sockets 12.1 Networked Te ...
- 潭州课堂25班:Ph201805201 WEB 之 页面编写 第三课 (课堂笔记)
index.html <!DOCTYPE html> <html lang="en"> <head> <meta charset=&quo ...
- Python Web-第二周-正则表达式(Using Python to Access Web Data)
0.课程地址与说明 1.课程地址:https://www.coursera.org/learn/python-network-data/home/welcome 2.课程全名:Using Python ...
- 【Python学习笔记】Coursera课程《Using Python to Access Web Data》 密歇根大学 Charles Severance——Week6 JSON and the REST Architecture课堂笔记
Coursera课程<Using Python to Access Web Data> 密歇根大学 Week6 JSON and the REST Architecture 13.5 Ja ...
- 【Python学习笔记】Coursera课程《Using Python to Access Web Data 》 密歇根大学 Charles Severance——Week2 Regular Expressions课堂笔记
Coursera课程<Using Python to Access Web Data > 密歇根大学 Charles Severance Week2 Regular Expressions ...
- 《Using Python to Access Web Data》Week4 Programs that Surf the Web 课堂笔记
Coursera课程<Using Python to Access Web Data> 密歇根大学 Week4 Programs that Surf the Web 12.3 Unicod ...
- [Project] Simulate HTTP Post Request to obtain data from Web Page by using Python Scrapy Framework
1. Background Though it's always difficult to give child a perfect name, parent never give up trying ...
- 利用 NGINX 最大化 Python 性能,第一部分:Web 服务和缓存
[编者按]本文主要介绍 nginx 的主要功能以及如何通过 NGINX 优化 Python 应用性能.本文系国内 ITOM 管理平台 OneAPM 编译呈现. Python 的著名之处在于使用简单方便 ...
- python 全栈开发,Day66(web应用,http协议简介,web框架)
一.web应用 web应用程序是一种可以通过Web访问的应用程序,程序的最大好处是用户很容易访问应用程序,用户只需要有浏览器即可,不需要再安装其他软件.应用程序有两种模式C/S.B/S.C/S是客户端 ...
随机推荐
- mapper映射文件配置之select、resultMap(转载)
原文地址:http://www.cnblogs.com/dongying/p/4073259.html 先看select的配置吧: <select <!-- 1. id ( ...
- PHP实现最简单爬虫原型
本人qq群也有许多的技术文档,希望可以为你提供一些帮助(非技术的勿加). QQ群: 281442983 (点击链接加入群:http://jq.qq.com/?_wv=1027&k=29Lo ...
- 跨域 (2) cors
html <!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF- ...
- NJU 操作系统实验三
实验描述: 代码实现: 链接:https://pan.baidu.com/s/1so3-XsvWBY9ZDbINob6qCw 提取码:8hhe
- 浅析为什么用高阶组件代替 Mixins
转载来源 感谢分享 Mixins 引入了无形的依赖 应尽量构建无状态组件,Mixin 则反其道而行之 Mixin 可能会相互依赖,相互耦合,不利于代码维护 不同的 Mixin 中的方法可能会相互冲突 ...
- vue打包多页报错webpackJsonp is not defined
找到build→webpack.prod.conf.js→找到HtmlWebpackPlugin插件,添加如下配置即可 chunks: ['manifest', 'vendor', 'app']
- jquery easyui datagrid 远程加载数据----把主键渲染为值遇到的问题及解决方案
起因:数据库中一些字段存的是代表具体值的数字,需要渲染为具体值 monggodb中的字典 mysql中存放的值为:expertin代表教练擅长的搏击技能 jquery easyui中的相关代码如下:用 ...
- Tomcat网站上的core和deployer的区别
8.5.13 Please see the README file for packaging information. It explains what every distribution(分布) ...
- CPC/CPM/CPA/CPS定义
CPC 每点击次数计费 CPM 每千人次展现计费 CPA 每行动成果计费(比如推广成功一个用户) CPS 淘宝客类型,按照商品佣金,推广成功计费
- JAVA笔记20-容器之四Map接口、自动打包、泛型(重要)
一.Map接口 Map提供的是key到value的映射.key不能重复,每个key只能映射一个value. 注:重复是指equals,但用equals()方法效率低,所以此处用hashCode()方法 ...