使用shuffle sharding增加容错性
使用shuffle sharding增加容错性
最近在看kubernetes的API Priority and Fairness,它使用shuffle sharding来为请求选择处理队列,以此防止高吞吐量流挤占低吞吐量流,进而造成请求延迟的问题。
介绍
首先看下什么是shuffle sharding,下面内容来自aws的Workload isolation using shuffle-sharding。
首先来看如何使用一般分片方式来让系统具备可扩展性和弹性。
假设有一个8 workers节点的水平可扩展的系统或服务,下图红线表示达到这些节点的请求,worker可以是服务,队列或数据库等。
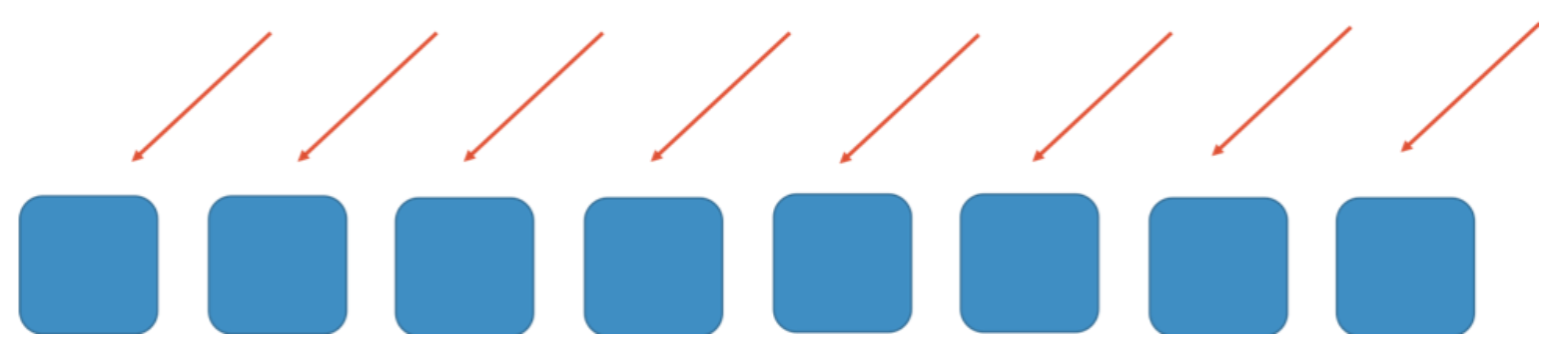
如果没有任何分片,则要求每个worker能够处理所有请求。这种方式高效且具备一定的冗余性。如果一个worker出现故障,则可以将它的任务分配到剩余的7个worker上。此时可能需要增加一定的系统容量。但如果突然出现大量请求,如DDoS攻击,可能会导致级联故障。下面两张图展示了故障是如何升级的。

首先会影响第一台worker,随后会级联到其他workers上,最终导致整个服务不可用。

为了防止故障转移,通常可以使用分片方式,如将workers分为4个分片,以效率换取影响度。下面两张图展示了如何使用分片来限制DDoS攻击。
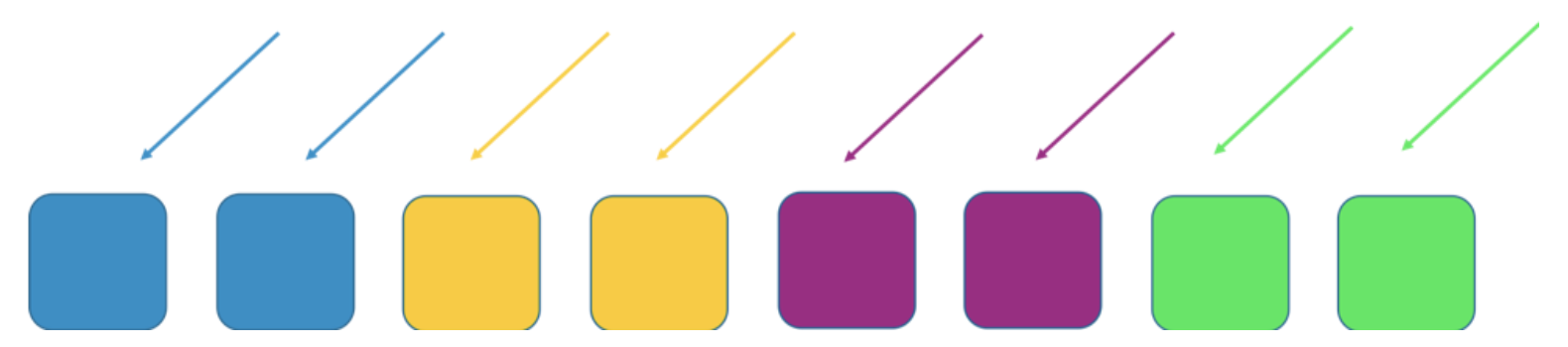
本例中,每个分片包含2个workers,并按照资源(如域名)进行切片。此时的系统仍然具有冗余性,但由于每个分片只有2个workers,因此可能需要增加容量来避免故障。

通过这种方式降低了故障影响范围。这里有4个分片,如果一个分片故障,则只会影响该分片上的服务,其他分片则不受影响。影响范围为25%。使用shuffle sharding可以达到更好的效果。
shuffle sharding用到了虚拟分片(shuffle shard)的概念,这里将不会直接对workers进行分片,而是按照"用户"进行分片,目的是尽量将用户打散分布到不同的worker上。
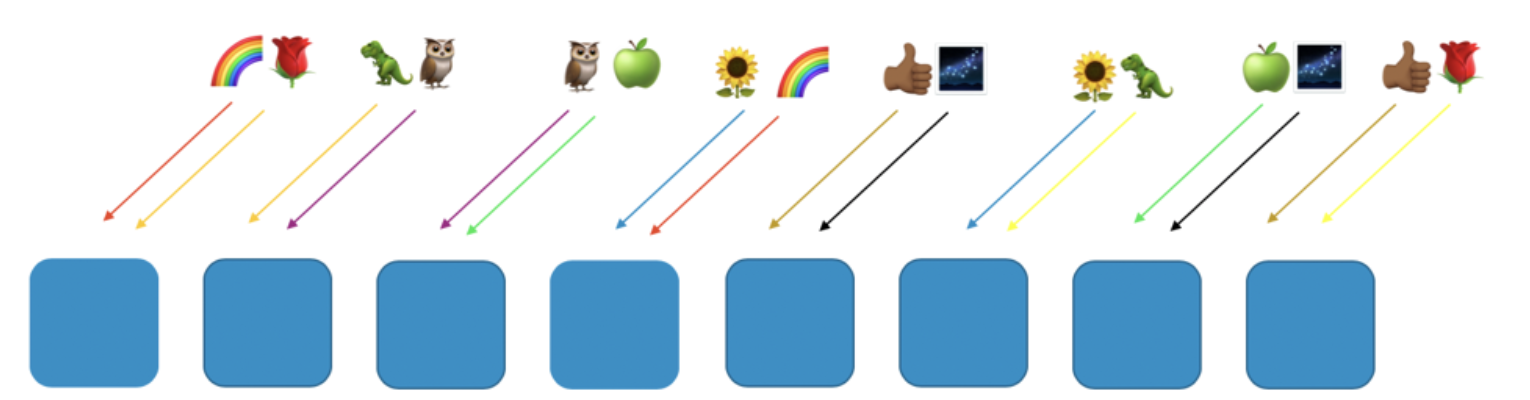
下图展示的shuffle sharding布局中包含8个workers和8个客户,并给每个客户分配了2个workers。以彩虹和玫瑰表示的客户为例。
这里,我们给彩虹客户分配了第1个和第4个worker,这两个workers构成了该客户的shuffle shard,其他客户将使用不同的虚拟分片(含2个workers),如玫瑰客户分配了第1个和最后一个worker。
如果彩虹用户分配的worker 1和worker 4出现了问题(如恶意请求或请求泛红等),则此问题只会影响本虚拟分片,但不会影响到其他shuffle shard。事实上,最多只会有另外一个shuffle shard会受到影响(即另外一个服务都部署到了worker 1和worker 4)。如果请求方具有容错性,则可以继续使用剩余分片继续提供服务。

换句话说,当彩虹客户所在的节点因为出现问题或受到攻击而无法提供服务时,不会影响到其他节点。对于客户而言,虽然玫瑰客户和向日葵客户都和彩虹客户共享了worker,但并没有导致其服务中断,玫瑰客户仍然可以继续使用workers 8提供服务,而向日葵客户可以继续使用worker 6提供服务。
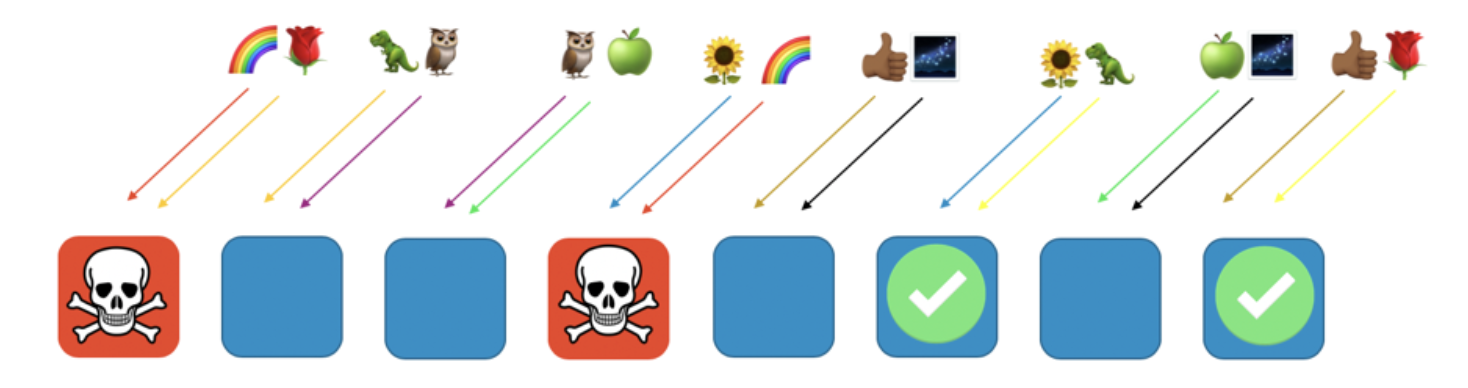
当出现上述问题时,虽然失去了四分之一的worker节点,但使用shuffle sharding可以大大降低影响范围。上述场景下,一共有28种两两worker的组合方式,即28种shuffle shards。当有上百甚至更多的客户时,我们可以给每个客户分配一个shuffle shards,以此可以将影响范围缩小到1/28,效果是一般分片方式的7倍。
kubernetes中的shuffle sharding
使用shuffle sharding为流分片队列
kubernetes的流控功能中使用了shuffle sharding,其代码实现如下:
func NewDealer(deckSize, handSize int) (*Dealer, error) {
if deckSize <= 0 || handSize <= 0 {
return nil, fmt.Errorf("deckSize %d or handSize %d is not positive", deckSize, handSize)
}
if handSize > deckSize {
return nil, fmt.Errorf("handSize %d is greater than deckSize %d", handSize, deckSize)
}
if deckSize > 1<<26 {
return nil, fmt.Errorf("deckSize %d is impractically large", deckSize)
}
if RequiredEntropyBits(deckSize, handSize) > MaxHashBits {
return nil, fmt.Errorf("required entropy bits of deckSize %d and handSize %d is greater than %d", deckSize, handSize, MaxHashBits)
}
return &Dealer{
deckSize: deckSize,
handSize: handSize,
}, nil
}
func (d *Dealer) Deal(hashValue uint64, pick func(int)) {
// 15 is the largest possible value of handSize
var remainders [15]int
//这个for循环用于生成[0,deckSize)范围内的随机数。
for i := 0; i < d.handSize; i++ {
hashValueNext := hashValue / uint64(d.deckSize-i)
remainders[i] = int(hashValue - uint64(d.deckSize-i)*hashValueNext)
hashValue = hashValueNext
}
for i := 0; i < d.handSize; i++ {
card := remainders[i]
for j := i; j > 0; j-- {
if card >= remainders[j-1] {
card++
}
}
pick(card)
}
}
func (d *Dealer) DealIntoHand(hashValue uint64, hand []int) []int {
h := hand[:0]
d.Deal(hashValue, func(card int) { h = append(h, card) })
return h
}
首先使用
func NewDealer(deckSize, handSize int)初始化一个实例,以kubernetes的APF功能为例,deckSize为队列数,handSize表示为一条流分配的队列数量使用
func (d *Dealer) DealIntoHand(hashValue uint64, hand []int)可以返回为流选择的队列ID,hashValue可以看做是流的唯一标识,hand为存放结果的数组。hashValue的计算方式如下,fsName为flowschemas的名称,fDistinguisher可以是用户名或namespace名称:func hashFlowID(fsName, fDistinguisher string) uint64 {
hash := sha256.New()
var sep = [1]byte{0}
hash.Write([]byte(fsName))
hash.Write(sep[:])
hash.Write([]byte(fDistinguisher))
var sum [32]byte
hash.Sum(sum[:0])
return binary.LittleEndian.Uint64(sum[:8])
}
用法如下:
var backHand [8]int
deal, _ := NewDealer(128, 9)
fmt.Println(deal.DealIntoHand(8238791057607451177, backHand[:]))
//输出:[41 119 0 49 67]
为请求分片队列
上面为流分配了队列,实现了流之间的队列均衡。此时可能为单条流分配了多个队列,下一步就是将单条流的请求均衡到分配到的各个队列中。核心代码如下:
func (qs *queueSet) shuffleShardLocked(hashValue uint64, descr1, descr2 interface{}) int {
var backHand [8]int
// Deal into a data structure, so that the order of visit below is not necessarily the order of the deal.
// This removes bias in the case of flows with overlapping hands.
//获取本条流的队列列表
hand := qs.dealer.DealIntoHand(hashValue, backHand[:])
handSize := len(hand)
//qs.enqueues表示队列中的请求总数,这里第一次哈希取模算出队列的起始偏移量
offset := qs.enqueues % handSize
qs.enqueues++
bestQueueIdx := -1
minQueueSeatSeconds := fqrequest.MaxSeatSeconds
//这里用到了上面的偏移量,并考虑到了队列处理延迟,找到延迟最小的那个队列作为目标队列
for i := 0; i < handSize; i++ {
queueIdx := hand[(offset+i)%handSize]
queue := qs.queues[queueIdx]
queueSum := queue.requests.QueueSum()
// this is the total amount of work in seat-seconds for requests
// waiting in this queue, we will select the queue with the minimum.
thisQueueSeatSeconds := queueSum.TotalWorkSum
klog.V(7).Infof("QS(%s): For request %#+v %#+v considering queue %d with sum: %#v and %d seats in use, nextDispatchR=%v", qs.qCfg.Name, descr1, descr2, queueIdx, queueSum, queue.seatsInUse, queue.nextDispatchR)
if thisQueueSeatSeconds < minQueueSeatSeconds {
minQueueSeatSeconds = thisQueueSeatSeconds
bestQueueIdx = queueIdx
}
}
...
return bestQueueIdx
}
使用shuffle sharding增加容错性的更多相关文章
- Hadoop笔记HDFS(1)
环境:Hadoop2.7.3 1.Benchmarking HDFS 1.1测试集群的写入 运行基准测试是检测HDFS集群是否正确安装以及表现是否符合预期的好方法.DFSIO是Hadoop自带的一个基 ...
- SharePoint咨询师之路:设计之前的那些事四:负载均衡 - web服务器
提示:本系列只是一个学习笔记系列,大部分内容都可以从微软官方网站找到,本人只是按照自己的学习路径来学习和呈现这些知识.有些内容是自己的经验和积累,如果有不当之处,请指正. 容量管理 规模 体系结构 ...
- 【转载】Apache Spark Jobs 性能调优(一)
当你开始编写 Apache Spark 代码或者浏览公开的 API 的时候,你会遇到各种各样术语,比如 transformation,action,RDD 等等. 了解到这些是编写 Spark 代码的 ...
- Apache Spark Jobs 性能调优
当你开始编写 Apache Spark 代码或者浏览公开的 API 的时候,你会遇到各种各样术语,比如transformation,action,RDD(resilient distributed d ...
- 消息队列中间件(三)Kafka 入门指南
Kafka 来源 Kafka的前身是由LinkedIn开源的一款产品,2011年初开始开源,加入了 Apache 基金会,2012年从 Apache Incubator 毕业变成了 Apache 顶级 ...
- Kafka 基本概念学习笔记
一. 什么是Kafka 面向数据流的生产,转换,存储,消费的整体流处理平台 二.Kafka三大特性 1.发布和订阅数据的流,类似于消息队列,消息系统 2..数据流存储平台 3.当数据产生的时候,对数据 ...
- Kafka流处理平台
1. Kafka简介 Kafka是最初由Linkedin公司开发,是一个分布式.支持分区的(partition).多副本的(replica),基于zookeeper协调的分布式消息系统,它的最大的特性 ...
- Android注入完全剖析
0 前沿 本文主要分析了一份实现Android注入的代码的技术细节,但是并不涉及ptrace相关的知识,所以读者如果不了解ptrace的话,最好先学习下ptrace原理再来阅读本文.首先,感谢源代码的 ...
- USB 3.0规范中译本 第7章 链路层
本文为CoryXie原创译文,转载及有任何问题请联系cory.xie#gmail.com. 链路层具有维持链路连接性的责任,从而确保在两个链路伙伴之间的成功数据传输.基于包(packets)和链路命令 ...
- ~~番外:说说Python 面向对象编程~~
进击のpython Python 是支持面向对象的 很多情况下使用面向对象编程会使得代码更加容易扩展,并且可维护性更高 但是如果你写的多了或者某一对象非常复杂了,其中的一些写法会相当相当繁琐 而且我们 ...
随机推荐
- 拥抱jsx,开启vue3用法的另一种选择🔥🔥
背景 公司高级表单组件ProForm高阶组件都建立在jsx的运用配置上,项目在实践落地过程中积累了丰富的经验,也充分感受到了jsx语法的灵活便捷和可维护性强大,享受到了用其开发的乐趣,独乐乐不如众乐乐 ...
- 2023 华北分区赛 normal_snake
国赛终于解出Java题了,顺利拿下一血,思路之前也学过.继续加油 normal_snake 题目解读 @RequestMapping({"/read"}) public Strin ...
- 【webpack系列】从核心概念到上手配置
前言 作为前端开发者,相信大家或多或少都接触过webpack,现如今webpack已经渗透在了前端的各个方面,所以我们有必要来了解并学习webpack,webpack 是一种用于构建 JavaScri ...
- sql server注入rce实践
背景:在漏洞挖掘中,合理的利用sql注入,可以把注入转换成rce,使一个高危漏洞变成严重漏洞.在红蓝对抗中,利用注入rce,实现内网横向移动.笔者基于漏洞挖掘和红蓝对抗上遇到的sql server注入 ...
- React后台管理系统06 路由
在src目录下新建2views文件夹,用来存放组件,这里我们新建2个路由组件Home About,如下所示: 创建好这两个路由组件之后,在src目录里面我们新建一个router路由文件夹,然后命名一个 ...
- Linux系统运维之MYSQL数据库集群部署(主从复制)
一.介绍 Mysql主从复制,前段时间生产环境部署了一套主从复制的架构,当时现找了很多资料,现在记录下 二.拓扑图 三.环境以及软件版本 主机名 IP 操作系统 角色 软件版本 MysqlDB_Mas ...
- Ubuntu虚拟机教程
1.下载ubuntu镜像 可以去中科大镜像站下载(本次下载20.04版本,不同版本操作会有差异,建议保持一致) https://mirrors.ustc.edu.cn/ 点击如图所示的按钮下载 2.v ...
- Java protected 关键字详解
很多介绍Java语言的书籍(包括<Java编程思想>)都对protected介绍的比较的简单,基本都是一句话,就是: 被 protected 修饰的成员对于本包和其子类可见.这种说法有点太 ...
- Asp.Net MVC中Action跳转小结(转载)
来源: https://www.cnblogs.com/surfing/p/3542826.html 首先我觉得action的跳转大致可以这样归一下类,跳转到同一控制器内的action和不同控制器内的 ...
- PostgreSQL 10 文档: SQL 语法
SQL 命令 这部分包含PostgreSQL支持的SQL命令的参考信息.每条命令的标准符合和兼容的信息可以在相关的参考页中找到. 目录 ABORT - 中止当前事务 ALTER AGGREGATE ...