阿里如何实现秒级百万TPS?搜索离线大数据平台架构解读
★ 淘宝搜索阶段
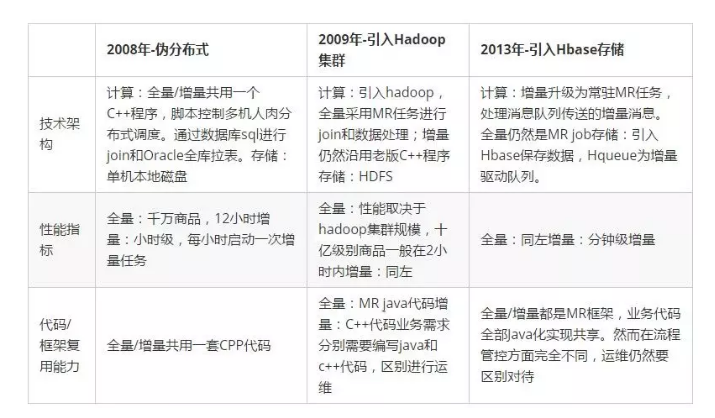
在2008-2012这个阶段,我们重点支持淘宝搜索的业务发展,随着淘宝商品量的不断增加,逐步引入Hadoop、Hbase等开源大数据计算和存储框架,实现了搜索离线系统的分布式化,有力地支持了淘宝搜索业务的发展。但是在这个阶段,我们支持的业务线只有淘系合计不到5个业务线,为此投入了大约10名开发人员,整体效率不高。另一方面相关系统框架代码与淘系业务高度耦合,量身定制了很多特殊代码,不利于架构的推广和其它业务的支持。
★ 组件&平台化阶段
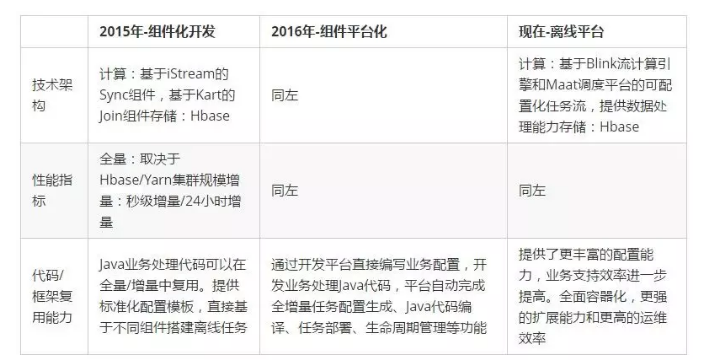
2013年底以来,特别是最近两年,随着集团技术业务线的梳理以及中台化战略的推行,搜索离线系统需要为越来越多的不同业务团队(飞猪、钉钉、1688、AE、Lazada等等)提供支持,技术框架复用、开发效率提升和平台化支持的需求越来越强烈。另一方面随着大数据计算、存储技术的发展,尤其是流计算引擎的飞速发展,离线系统技术架构上的进一步演进也具备了绝佳的土壤。
离线平台技术架构
平台组件和任务流程
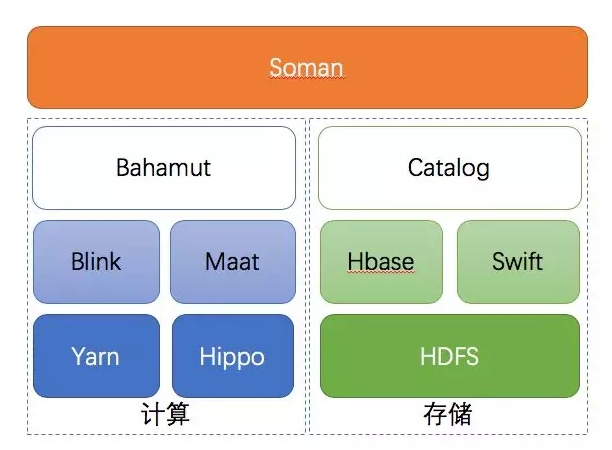
上图描述了离线平台技术组件结构,其中部分组件的简介如下:
Maat:分布式任务调度平台,基于Airflow发展而来,主要改进点是调度性能优化、执行器FaaS化、容器化、API及调度功能扩展等四个部分,在保持对Airflow兼容的基础上,大幅提升性能,提高了稳定性。 一个离线任务的多个Blink job会通过Maat建立依赖关系并进行调度。
Bahamut:执行引擎,是整个离线平台的核心,负责离线任务的创建、调度、管理等各种功能,后文会详细介绍。
Blink:Flink的阿里内部版本,在大规模分布式、SQL、TableAPI、Batch上做了大量的优化和重构。离线平台的所有计算任务都是Blink job,包括stream和batch。
Soman:UI模块,与Bahamut后端对接,提供任务信息展示、状态管理等可视化功能,也是用户创建应用的开发业务逻辑的主要入口。
Catalog: 存储表信息管理,提供各种数据源表的DDL能力,负责离线平台存储资源的申请、释放、变更等各种功能。
Hippo:阿里搜索自研的分布式资源管理和任务调度服务,类似于Yarn,提供Docker管理能力,主要服务于在线系统。
Swift:阿里搜索自研高性能分布式消息队列,支持亿级别消息吞吐能力,存储后端为HDFS,存储计算分离架构。
下图则描述了一个离线任务从数据源到产出引擎服务数据的整个过程,流程图分成三层:
数据同步层:将用户定义的数据源表的全量和增量数据同步到Hbase内部表,相当于源表的镜像。这个镜像中我们包含cf和d两个列族,分别存储数据库的镜像和Daily更新的数据。
数据关联计算层:按照数据源中定义的各种关系,将不同维度的数据关联到一起,把数据送到自定义的UDTF中进行处理,产出引擎所需的全量和增量数据。
数据交互层:提供全量和增量数据的存储信息,与在线服务build模块进行交互。
全增量统一的计算模型
那么如何实现对用户屏蔽离线平台内部的这些技术细节,让用户只需要关注业务实现呢?回顾第一节介绍的离线任务概念,离线任务包含全量和增量,它们业务逻辑相同,但是执行模式上有区别。为了让用户能够专注业务逻辑的开发,屏蔽离线平台技术细节实现全增量统一的计算逻辑,我们引入了Business Table(业务表)的概念。
Business Table(业务表):Business Table是一个抽象表,由一个全量数据表和/或一个增量流表组成,全量/增量表的Schema相同,业务含义相同。
基于业务表和数据处理组件,用户可以开发出一个描述离线处理流程的业务逻辑图,我们称之为Business Graph。下图就是一个Business Graph的样例,其中上侧红框标识的就是只包含ODPS全量数据源的Business Table,最下方红框中标识的是包含Hdfs+Swift的Business Table,除此之外我们还支持Mysql+DRC/ODPS+Swift等多种业务表的组合。图中还可以看到Join、UDTF等常用的数据处理组件,业务表与处理组件结合在一起就能够描述常见的离线业务处理逻辑。
参考博客:https://mp.weixin.qq.com/s?__biz=MzIzOTU0NTQ0MA==&mid=2247488245&idx=1&sn=1c70a32f11da7916cb402933fb65dd9f&chksm=e9292ffade5ea6ec7c6233f09d3786c75d02b91a91328b251d8689e8dd8162d55632a3ea61a1&scene=21#wechat_redirect
阿里如何实现秒级百万TPS?搜索离线大数据平台架构解读的更多相关文章
- 《阿里如何实现秒级百万TPS?搜索离线大数据平台大数据平台架构解读》读后感
在使用淘宝时发现搜索框很神奇,它可以将将我们想要的商品全部查询出来,但是我们并感觉不到数据库查询的过程,速度很快.通过阅读这篇文章让我知道了搜索框背后包含着很多技术,对我以后的学习可能很有借鉴. 平时 ...
- 《阿里如何实现秒级百万TPS?搜索离线大数据平台架构解读》--阅读
离线?在阿里搜索工程体系中我们把搜索引擎.在线算分.SearchPlanner等ms级响应用户请求的服务称之为“在线”服务:与之相对应的,将各种来源数据转换处理后送入搜索引擎等“在线”服务的系统统称为 ...
- QQ音乐PB级ClickHouse实时数据平台架构演进之路
导语 | OLAP(On-Line Analytical Processing),是数据仓库系统的主要应用形式,帮助分析人员多角度分析数据,挖掘数据价值.本文基于QQ音乐海量大数据实时分析场景,通过Q ...
- 第四章 电商云化,4.1 17.5W秒级交易峰值下的混合云弹性架构之路(作者:唐三 乐竹 锐晟 潇谦)
4.1 17.5W秒级交易峰值下的混合云弹性架构之路 前言 每年的双11都是一个全球狂欢的节日,随着每年交易逐年创造奇迹的背后,按照传统的方式,我们的成本也在逐年上升.双11当天的秒级交易峰值平时的近 ...
- AI加持的阿里云飞天大数据平台技术揭秘
摘要:2019云栖大会大数据&AI专场,阿里云智能计算平台事业部研究员关涛.资深专家徐晟来为我们分享<AI加持的阿里云飞天大数据平台技术揭秘>.本文主要讲了三大部分,一是原创技术优 ...
- 首次公开!单日600PB的计算力--阿里巴巴EB级大数据平台的进击
MaxCompute作为阿里巴巴的主力计算平台,在2018年的双11中,再次不负众望,经受住了双11期间海量数据和高并发量的考验.为集团的各条业务线提供了强劲的计算力,不愧是为阿里巴巴历年双11输送超 ...
- 阿里云HBase全新发布X-Pack 赋能轻量级大数据平台
一.八年双十一,造就国内最大最专业HBase技术团队 阿里巴巴集团早在2010开始研究并把HBase投入生产环境使用,从最初的淘宝历史交易记录,到蚂蚁安全风控数据存储.持续8年的投入,历经8年双十一锻 ...
- 大数据平台Hive数据迁移至阿里云ODPS平台流程与问题记录
一.背景介绍 最近几天,接到公司的一个将当前大数据平台数据全部迁移到阿里云ODPS平台上的任务.而申请的这个ODPS平台是属于政务内网的,因考虑到安全问题当前的大数据平台与阿里云ODPS的网络是不通的 ...
- 基于Flink秒级计算时CPU监控图表数据中断问题
基于Flink进行秒级计算时,发现监控图表中CPU有数据中断现象,通过一段时间的跟踪定位,该问题目前已得到有效解决,以下是解决思路: 一.问题现象 以SQL02为例,发现本来10秒一 ...
- 阿里云HBase携X-Pack再进化,重新赋能轻量级大数据平台
一.八年双十一,造就国内最大最专业HBase技术团队 阿里巴巴集团早在2010开始研究并把HBase投入生产环境使用,从最初的淘宝历史交易记录,到蚂蚁安全风控数据存储.持续8年的投入,历经8年双十一锻 ...
随机推荐
- react 兄弟组件传值(发布订阅,使用于任何组件传值,包括vue)
react中兄弟组件传值常规操作一般是,A组件传给父组件,父组件再传给B组件 非常规操作 利用 pubsub-js 在Home组件内调用 PubSub.publish("第一个参数是事件名 ...
- vue本地开发配置及项目部署
一, 二,本地模拟配置代理,请求qq音乐的接口数据 三,axios请求头封装 参考http://www.axios-js.com/zh-cn/docs/#%E4%BB% ...
- 【Dotnet 工具箱】JIEJIE.NET - 强大的 .NET 代码混淆工具
你好,这里是 Dotnet 工具箱,定期分享 Dotnet 有趣,实用的工具和组件,希望对您有用! JIEJIE.NET - 强大的 .NET 代码混淆工具 JIEJIE.NET JIEJIE.NET ...
- 从案例中详解go-errgroup-源码
一.背景 某次会议上发表了error group包,一个g失败,其他的g会同时失败的错误言论(看了一下源码中的一句话The first call to return a non-nil error c ...
- 16.ReentrantLock全解读
大家好,我是王有志,欢迎和我聊技术,聊漂泊在外的生活.快来加入我们的Java提桶跑路群:共同富裕的Java人. 经历了AQS的前世和今生后,我们已经知道AQS是Java中提供同步状态原子管理,线程阻塞 ...
- cefsharp学习笔记
环境:VS2015+cefsharp 57.0 全部代码如下: 1.要初始化,否则不能刷新 using System; using CefSharp; using System.Collections ...
- 猿人学内部js练习平台习题记录
猿人学内部js练习平台习题记录 根据课程更新 当前先完成第7题和第10题 第7题 骚操作 请求规律检测1 - post 1)通过fiddler抓包,看看请求头和请求体有什么骚操作的地方,如果没有反爬就 ...
- Django4全栈进阶之路5 Model模型
在 Django 中,模型(Model)是用于定义数据结构的组件,其作用如下: 定义数据结构:模型用于定义数据库中的表格和表格中的字段(列),其中每个模型类对应一个表格,模型中的每个字段对应表格中的一 ...
- import MySQLdb as Database ModuleNotFoundError: No module named ‘MySQLdb‘
import MySQLdb as Database ModuleNotFoundError: No module named 'MySQLdb' import MySQLdb as Database ...
- 【CF】873B Balanced Substring(前缀和+map)
Balanced Substring 刚讲过差分与前缀和专题,一直以为这两个名词很高大上,其实也就那回事.哈哈. 题源:https://codeforces.com/contest/873/probl ...