首次公开!单日600PB的计算力--阿里巴巴EB级大数据平台的进击
MaxCompute作为阿里巴巴的主力计算平台,在2018年的双11中,再次不负众望,经受住了双11期间海量数据和高并发量的考验。为集团的各条业务线提供了强劲的计算力,不愧是为阿里巴巴历年双11输送超级计算力的核武器。
本文为大家介绍,MaxCompute基于多集群部署的几万台服务器,如何为集团急剧增长的业务提供护航和保障。

挑战
每年的双11之前,也是MaxCompute各种乾坤大挪移落定的时候,因为双11就是各种大折腾项目的自然deadline。在今年双11之前,一路向北迁移和在离线混部项目,将杭州集群除蚂蚁外整体迁移到张北,涉及了绝大部分的业务project、数据存储和计算任务,为今年双十一大数据计算服务的保障带来了挑战。
体量
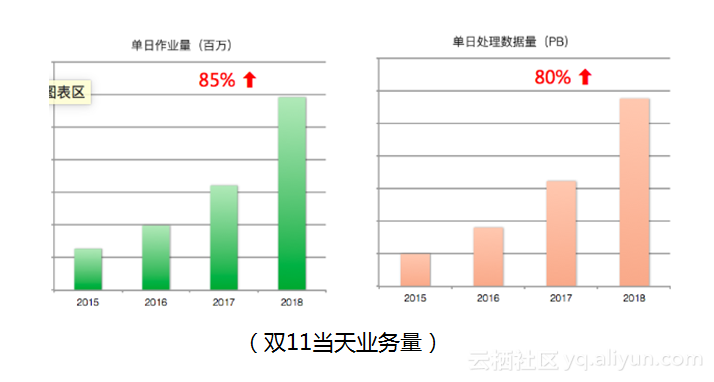
现在MaxCompute包括在离线混部集群在内有几万台服务器,数据总存储量在EB级,日均运行近几百万量级的作业,而每天所有作业处理的数据总量也在几百PB。集群分布三个地理区域,之间由长传链路相连接,由于集团数据业务固有的普遍联系特性,各个集群之间有着切不断的大量数据依赖,以及严重的带宽依赖。
成本
大量的服务器就是大量的成本,降低成本就要充分利用每个集群的计算存储能力,提高资源利用率。同时,不同业务有着不同的特征,有的存储多计算少,有的计算多存储少,有的大规模ETL I/O繁忙,有的机器学习科学计算CPU密集。
怎样充分利用每个集群的能力,提升CPU、内存、IO、存储各方面的利用率,同时均衡各集群负载,兼顾站点之间长传带宽的压力,在超高资源利用率下保障运行稳定,还要支持杭州整体搬迁这样量级的变更,这些挑战对于MaxCompute并不是应对双11大促的一次重大战役,而是MaxCompute每天的日常。
如何应对这些挑战,下面将从各个角度为大家介绍 MaxCompute 所做的一些列工作。
集群迁移
今年,一路向北迁移和在离线混部项目,将杭州集群迁移到张北,同时也涉及了MaxCompute控制集群和计算集群的迁移。 物理资源上的大腾挪,也给MaxCompute的服务保障带来了一些列问题和挑战。
透明的Project集群迁移
可能很多同学以前遇到过所在Project迁移集群时作业失败,出现 AllDenied 报错。之前在把Project迁到另一个集群的时候,会对用户有影响,操作前需要先做通知,对用户对运维同学都很困扰。
今年MaxCompute实现了迁移Project迁移过程中作业运行和提交都正常不受影响,做到了对用户透明。
轻量化迁移
集群之间因为业务的差异,会出现计算和存储配比不均衡的情况,而正常的迁移需要目标集群的存储和计算空间都满足需求才能做,这样就会遇到有的集群存储水位比较高,但计算能力还没用满,却没办法迁移大的Project过去的情况。
今年上线的轻量化迁移机制,可以实现只迁移计算和部分热数据到新的集群,而老数据则留在原集群,能够达到既均衡了计算资源,又不会有太多跨集群读写的效果。
搬走动不了的OTS
MaxCompute 使用OTS存储系统的各种核心元数据,所以一旦OTS异常,MaxCompute的整个服务都会受到影响。更严重的是,MaxCompute服务对OTS的依赖长期没有主备热切换的支持,使得OTS集群变成了MaxCompute唯一动不了的一个点。
今年作为一路向北迁移规划的一部分,我们仔细拟定和验证了OTS热切换方案,梳理了控制服务和OTS集群的依赖,目标不但是要做OTS的主备热切换,而且是从杭州直接切到张北。
尽管经历了一次弹内切换的失败,经过进一步优化和演练,最终我们把切换时间从预定的分钟级别切换缩短到了若干秒级的切换,并在公共云线上环境也成功实施,实际切换过程无异常反馈,做到了用户无感知。
从此MaxCompute服务里最关键的一个点有了无损热切换的能力,大大降低了整体服务的全局性风险。
跨集群调度
多样的全局作业调度机制
集群之间因为作业类型或业务特征等因素,可能会有各种计算资源使用的不充分,比如:业务的全天资源高峰时段及持续时间不同;申请大块资源的任务类型所在集群有空隙可以超卖小作业填充;甚至有些特殊情况会有临时的资源借用需求。
为此MaxCompute提供了一些全局作业调度机制,可以把指定的一批作业调度到指定的集群运行,或者在当前集群资源繁忙的时候,系统自动去看如果其它集群资源有空闲,就调度到空闲集群运行。
除了均衡资源利用率,这些机制也提供了人工调控的灵活性,并且还在进行与数据排布相结合的调度机制开发,以根据集群实时的状态进行调度。
拓扑感知、数据驱动的桥头堡
作业要访问其它集群的表数据有两个选择,一个是从本集群直接读远程集群(直读),一个是先把远程的数据复制一份到本集群(等复制)。这两种方式各有优缺点及其适用的场景。 同时,集群之间的网络拓扑(是异地长传还是同城同核心)也会影响直读和等复制策略的选择。异地长传带宽成本高,容量小,同城的网络带宽则相对容量较大,但在大数据的流量下,高峰期都是一样的可能拥堵,所以需要既利用同城带宽优势,又不能把瓶颈转移到同城,需要全局的策略调配。
因为每天业务都在变化,数据的依赖关系也在变化,我们利用对历史任务的分析数据持续优化和更新复制策略,在每个区域选择桥头堡集群接收长传的复制,然后在区域内实施链式复制或者近距离直读。 通过桥头堡2.0项目,我们实现了将2个地域间的数据复制流量降低了30%+。
新机型的新问题
一朝天子一朝臣,一代机型一代瓶颈。
现在MaxCompute的集群规模仍然是万台标准,但今天的万台已经不是几年前的万台,单机的CPU核数从曾经的24核、32核,再到新集群的96核,一台顶过去3台。但不管单机多少核,在MaxCompute的集群里,每天CPU总是能持续几个小时满负荷运行,总体日均CPU利用率达到65%。
不变的除了CPU利用率,还有磁盘数,我们的数据IO能力仍然是由不变的单机机械硬盘提供。虽然硬盘充起了氦气,单盘容量是以前的3倍,但单盘的IOPS能力却相差无几,DiskUtil就变成了非常大的瓶颈。
经过一系列的优化措施,今年大量96核集群的上线没有了去年面对64核时的狼狈不堪,把DiskUtil维持在了比较可控的水平。
透明的文件合并
跑作业时遇到报错FILE_NOT_FOUND重跑又能过,或者扫描长时间分区范围的作业反复重跑也没法跑过,这个情况相信很多人都遇到过。
为了缓解集群文件数的压力,平台的后台自动文件合并停一两天都有触顶的危险,但长期以来这个动作为了保证数据一致性和效率,都没法避免打断正在读的作业,只能选择只合并比较冷的分区,但一方面文件数的压力迫使把冷的判定阈值从一个月压缩到两周到更短,另一方面总会有不少作业仍然会去读早些时间的分区而被合并操作打断。
今年平台实现了新的合并机制,会给已经在运行的作业留一定的时间仍能读合并之前的文件,从而不再受影响,可以很大程度上解决这个顽固问题。
目前新的机制在公共云取得了很好的效果,集团内也在灰度试运行中。
平台性能提升
作为一个计算平台,MaxCompute以计算力为核心指标,通过不断的提升计算力,支撑起集团飞速的业务增长。 对比2017双十一,今年双十一当天MaxCompute作业数几乎有了成倍的增长。 过去一年中,MaxCompute通过在NewSQL+富结构化+联合计算平台+AliORC多个方向上发力,持续构建高可用、高性能、高自适性的大数据平台,提升平台计算力。 9月云栖大会发布中,TPC-BB的测评结果在10TB规模上超越开源系统3倍以上;100TB规模评分从去年的7800+提升到18000+,世界领先。

总结
MaxCompute 在2018双十一又一次平滑通过了大促的考验,同时我们也看到, 平台需要不断提升分布式计算下多集群的综合能力,不断提升计算力,保障大规模计算下的稳定性,来支撑起持续高速增长的业务。 通过持续的引擎能力优化、开发框架建设、智能数仓建设等维度,MaxCompute 向智能化的、开放的、生态平台发展,来支撑起下一个100%业务增长。
阅读原文
更多技术干货 请关注阿里云云栖社区微信号 :yunqiinsight
首次公开!单日600PB的计算力--阿里巴巴EB级大数据平台的进击的更多相关文章
- 揭秘阿里云EB级大数据计算引擎MaxCompute
日前,全球权威咨询与服务机构Forrester发布了<The Forrester WaveTM: Cloud Data Warehouse, Q4 2018>报告.这是Forrester ...
- Impala简介PB级大数据实时查询分析引擎
1.Impala简介 • Cloudera公司推出,提供对HDFS.Hbase数据的高性能.低延迟的交互式SQL查询功能. • 基于Hive使用内存计算,兼顾数据仓库.具有实时.批处理.多并发等优点 ...
- [NewLife.XCode]分表分库(百亿级大数据存储)
NewLife.XCode是一个有15年历史的开源数据中间件,支持netcore/net45/net40,由新生命团队(2002~2019)开发完成并维护至今,以下简称XCode. 整个系列教程会大量 ...
- 阿里巴巴年薪800k大数据全栈工程师成长记
大数据全栈工程师一词,最早出现于Facebook工程师Calos Bueno的一篇文章 - Full Stack (需fanqiang).他把全栈工程师定义为对性能影响有着深入理解的技术通才.自那以后 ...
- 《阿里如何实现秒级百万TPS?搜索离线大数据平台大数据平台架构解读》读后感
在使用淘宝时发现搜索框很神奇,它可以将将我们想要的商品全部查询出来,但是我们并感觉不到数据库查询的过程,速度很快.通过阅读这篇文章让我知道了搜索框背后包含着很多技术,对我以后的学习可能很有借鉴. 平时 ...
- SQL Server百万级大数据量删除
删除一个表中的部分数据,数据量百万级. 一般delete from 表 delete from 表名 where 条件: 此操作可能导致,删除操作执行的时间长:日志文件急速增长: 针对此情况处理 de ...
- 《阿里如何实现秒级百万TPS?搜索离线大数据平台架构解读》--阅读
离线?在阿里搜索工程体系中我们把搜索引擎.在线算分.SearchPlanner等ms级响应用户请求的服务称之为“在线”服务:与之相对应的,将各种来源数据转换处理后送入搜索引擎等“在线”服务的系统统称为 ...
- 提高mysql千万级大数据SQL查询优化30条经验(Mysql索引优化注意)
转自http://blog.163.com/zhangjie_0303/blog/static/9908270620146951355834/ 1.对查询进行优化,应尽量避免全表扫描,首先应考虑在 w ...
- (转)提高mysql千万级大数据SQL查询优化30条经验(Mysql索引优化注意)
1.对查询进行优化,应尽量避免全表扫描,首先应考虑在 where 及 order by 涉及的列上建立索引. 2.应尽量避免在 where 子句中对字段进行 null 值判断,否则将导致引擎放弃使用索 ...
随机推荐
- atexit函数学习
函数名: atexit 头文件:#include<stdlib.h> 功 能: 注册终止函数(即main执行结束后调用的函数) 用 法: void atexit(void (*func)( ...
- centos7.5部署ELk
第1章 环境规划 1.1 ELK介绍 ELK是ElasticSerach.Logstash.Kibana三款产品名称的首字母集合,用于日志的搜集和搜索. Elasticsearc ...
- shell正则匹配IP地址
IP分成5大类: A类地址 ⑴ 第1字节为网络地址,其它3个字节为主机地址. ⑵ 范围:1.0.0.1—126.155.255.254 ⑶ 私有地址和保留地址: ① 10.X.X.X是私有地址(只能在 ...
- linux基础知识-目录结构
linux的目录结构/bin:是Binary的缩写,这个目录存放着系统必备执行命令 /boot:这里存放的是启动Linux时使用的一些核心文件,包括一些连接文件以及镜像文 件,自己的安装别放这里 /d ...
- CF446D DZY Loves Games
CF446D DZY Loves Games 高斯消元好题 如果暴力地,令f[i][k]表示到i,有k条命的概率,就没法做了. 转化题意 生命取决于经过陷阱的个数 把这个看成一步 所以考虑从一个陷阱到 ...
- ASP.NET MVC 随手记
ViewBag: 本质上市一个字典,提供了一种View可以访问的动态数据存储.这里用到了.NET 4.0的动态语言特性.可以给ViewBag添加任意属性,并且这个属性是动态创建的,不需要修改类的定义就 ...
- 7-4 IP思考
内网ip和公网Ip 什么是内网IP: 一些小型企业或者学校,通常都是申请一个固定的IP地址,然后通过IP共享(IP Sharing),使用整个公司或学校的机器都能够访问互联网.而这些企业或学校的机器 ...
- gradle打成jar包报错 "错误: 找不到或无法加载主类 App"(已经配置过主类)
文章目录 将gradle打成jar包(包括依赖) 运行jar包 报错 原因(src自己手动创建的) 解决(添加src目录) 将gradle打成jar包(包括依赖) jar { manifest { a ...
- %matplotlib inline 被注释掉后,pycharm不能生成图
目录 问题描述 解决方案 @ 问题描述 在 jupyter 编译器中 程序的开头,有这么一行 %matplotlib inline import numpy as np import matplotl ...
- upc组队赛6 Bumped!【最短路】
Bumped! 题目描述 Peter returned from the recently held ACM ICPC World finals only to find that his retur ...