手绘流程图讲解spark是如何实现集群的高可用
摘要:本文讲述spark是怎么针对master、worker、executor的异常情况做处理的。
本文分享自华为云社区《图解spark是如何实现集群的高可用》,作者:breakDawn。
我们看下spark是怎么针对master、worker、executor的异常情况做处理的。
容错机制-exeuctor退出
首先可以假设worker中的executor执行任务时,发送了莫名其妙的异常或者错误,然后对应线程消失了。
我们看这个时候会做什么事情
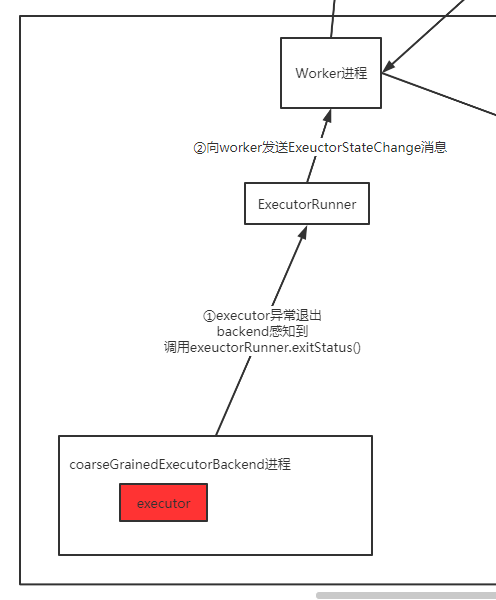
上图总结下来就是:
executor由backend进程包着,如果抛异常,他会感知到,并调用executorRunner.exitStatus(), 通知worker
看下通知worker之后发生了什么:
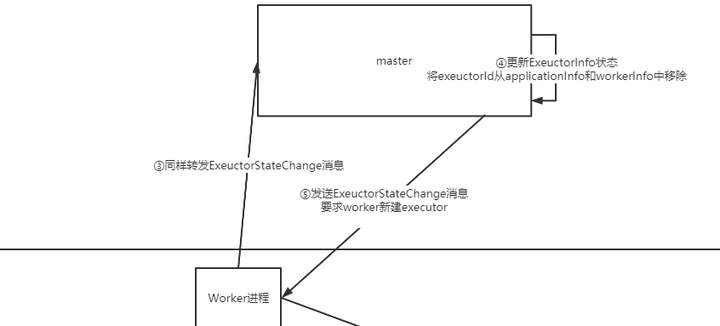
- worker会通知master,master会将exectorInfo清除,然后调度worker让他重新创建
- 这里可以看到worker创建executor的指令仍然是让master来调度和管理的,不是自己想创建就创建。
接下来就是重建executor,然后重新开始执行这个地方的任务了(因此数据也会重新拉,之前发送端缓存的数据就能够派上用场了)
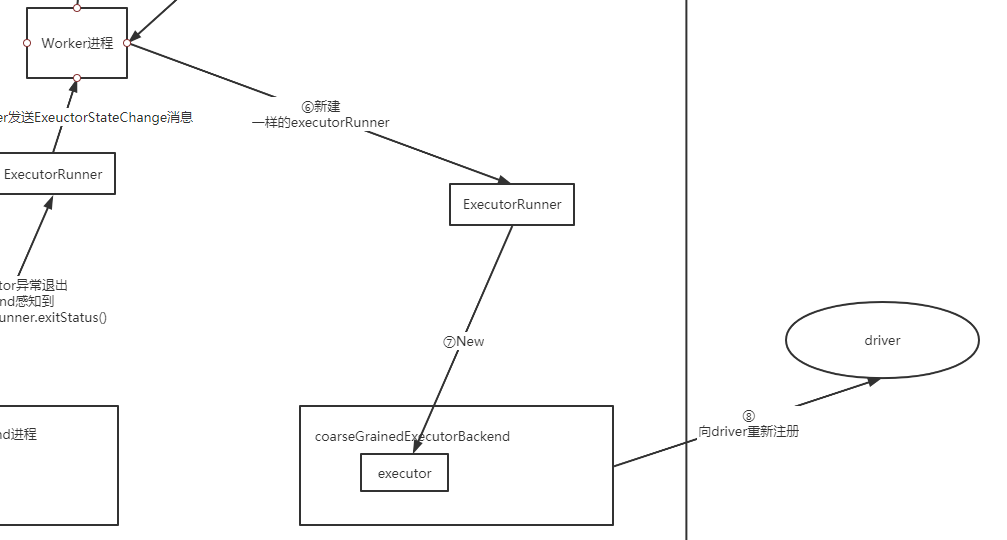
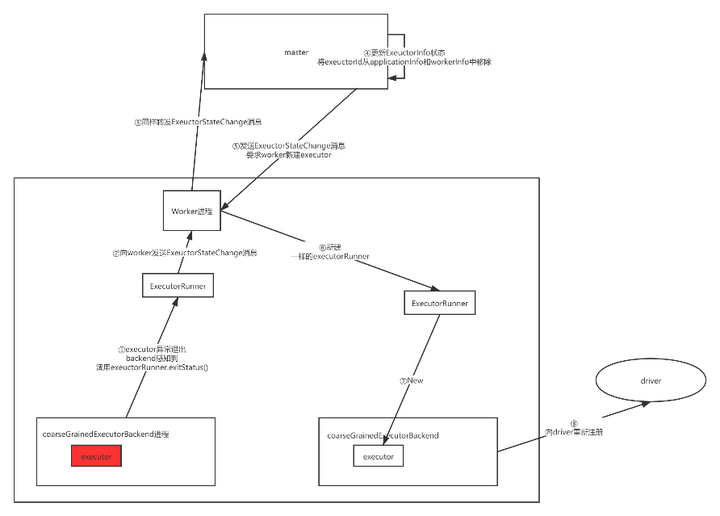
完整流程图如下:
worker异常退出
假设此时是worker挂掉了, 那么正在执行任务的exeuctor和master会怎么做呢?如下:
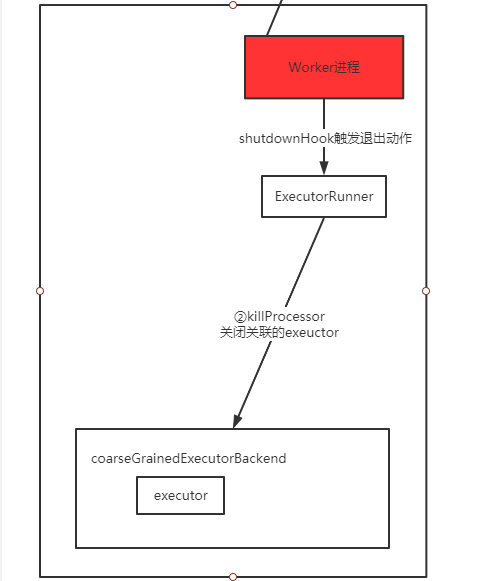
可以看到worker有一个shutdownHook,会帮忙关闭正在执行的executor。
但是此时worker挂了,因此没法往master发送消息了,怎么办?
上一节有讲到master和worker之间存在心跳,因此就会有如下处理:
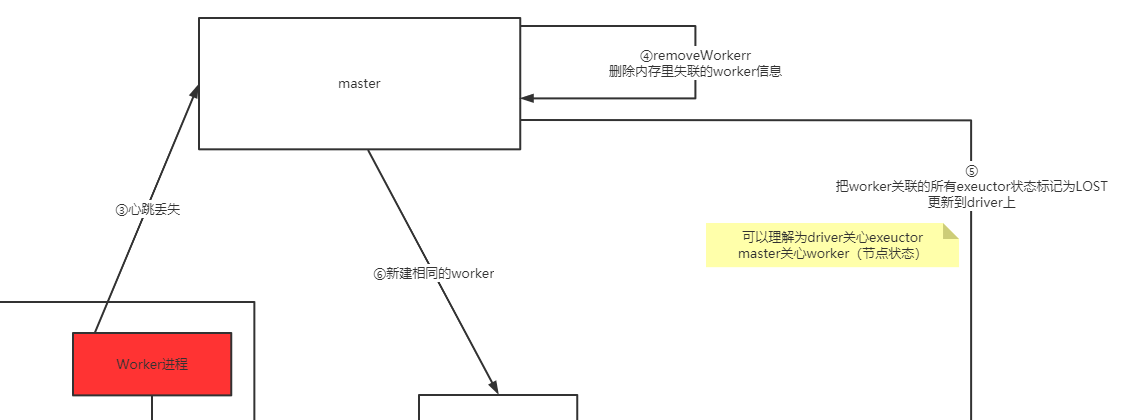
可以看到当master发现worker的心跳丢失时,会进行:
- 删除执行列表里的worker信息
- 重新下发创建worker的操作给对应spark节点
- 通知driver这个worker里面的exector都已经lost了
看下此时worker重建和driver分别做了什么:
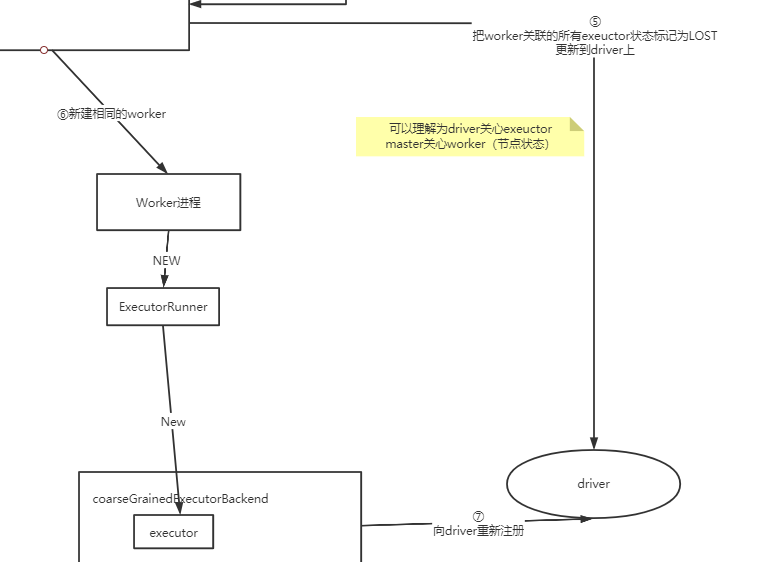
这里还可以看到1个很重要的概念:
- master关心worker状态
- driver会关心executor进展
- exeuctor重建后需要注册到driver上
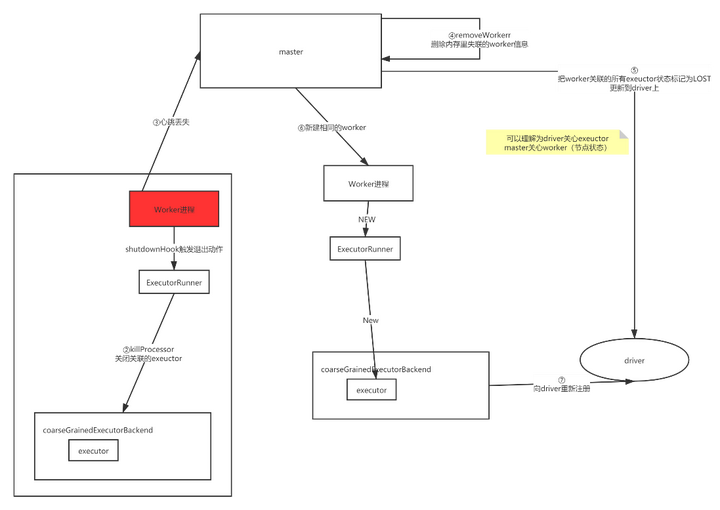
完整流程图如下:
master异常
由于master不参与任务的计算,只是对worker做管理,因此对于master的异常,分两种情况:
1、任务正常运行时master异常退出
则流程如下:
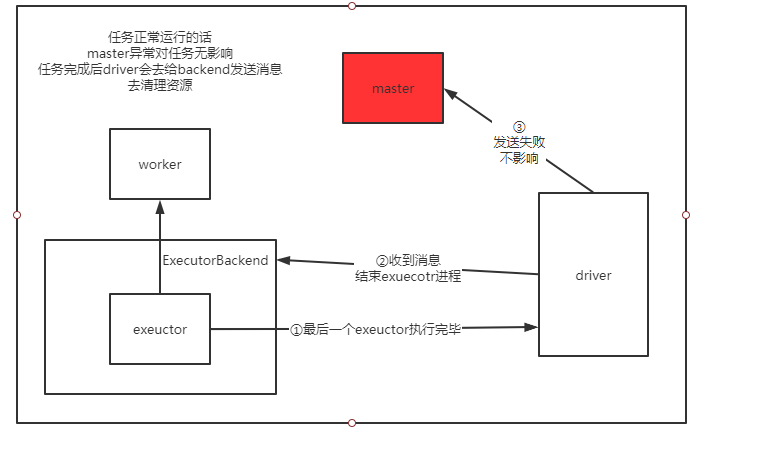
从这里可以看到当任务正常运行时,只会在结束时,由driver去触发master的清理资源操作,但是master进程已经挂掉了,所以也没关系。
2、当任务执行过程中,master挂掉后,worker和executor也异常了
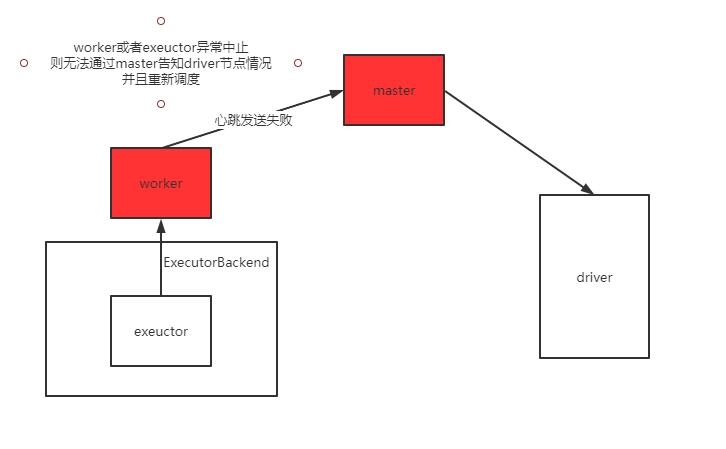
可以看到这时候时没办法重启exeuctor的
此时driver那边就会看起来任务一直没进展了。
为了避免这种情况,master可以做成无状态化,然后做主备容灾。当然master节点做的时候比较少,一般不容易崩溃,除非认为kill或者部署节点故障。
手绘流程图讲解spark是如何实现集群的高可用的更多相关文章
- Spark Streaming揭秘 Day31 集群模式下SparkStreaming日志分析(续)
Spark Streaming揭秘 Day31 集群模式下SparkStreaming日志分析(续) 今天延续昨天的内容,主要对为什么一个处理会分解成多个Job执行进行解析. 让我们跟踪下Job调用过 ...
- Spark Streaming揭秘 Day30 集群模式下SparkStreaming日志分析
Spark Streaming揭秘 Day30 集群模式下SparkStreaming日志分析 今天通过集群运行模式观察.研究和透彻的刨析SparkStreaming的日志和web监控台. Day28 ...
- Spark学习之在集群上运行Spark
一.简介 Spark 的一大好处就是可以通过增加机器数量并使用集群模式运行,来扩展程序的计算能力.好在编写用于在集群上并行执行的 Spark 应用所使用的 API 跟本地单机模式下的完全一样.也就是说 ...
- 【原创 Hadoop&Spark 动手实践 5】Spark 基础入门,集群搭建以及Spark Shell
Spark 基础入门,集群搭建以及Spark Shell 主要借助Spark基础的PPT,再加上实际的动手操作来加强概念的理解和实践. Spark 安装部署 理论已经了解的差不多了,接下来是实际动手实 ...
- Spark学习之在集群上运行Spark(6)
Spark学习之在集群上运行Spark(6) 1. Spark的一个优点在于可以通过增加机器数量并使用集群模式运行,来扩展程序的计算能力. 2. Spark既能适用于专用集群,也可以适用于共享的云计算 ...
- 在local模式下的spark程序打包到集群上运行
一.前期准备 前期的环境准备,在Linux系统下要有Hadoop系统,spark伪分布式或者分布式,具体的教程可以查阅我的这两篇博客: Hadoop2.0伪分布式平台环境搭建 Spark2.4.0伪分 ...
- Idea里面远程提交spark任务到yarn集群
Idea里面远程提交spark任务到yarn集群 1.本地idea远程提交到yarn集群 2.运行过程中可能会遇到的问题 2.1首先需要把yarn-site.xml,core-site.xml,hdf ...
- 大数据学习系列之七 ----- Hadoop+Spark+Zookeeper+HBase+Hive集群搭建 图文详解
引言 在之前的大数据学习系列中,搭建了Hadoop+Spark+HBase+Hive 环境以及一些测试.其实要说的话,我开始学习大数据的时候,搭建的就是集群,并不是单机模式和伪分布式.至于为什么先写单 ...
- HADOOP+SPARK+ZOOKEEPER+HBASE+HIVE集群搭建(转)
原文地址:https://www.cnblogs.com/hanzhi/articles/8794984.html 目录 引言 目录 一环境选择 1集群机器安装图 2配置说明 3下载地址 二集群的相关 ...
- hadoop+tachyon+spark的zybo cluster集群综合配置
1.zybo cluster 架构简述: 1.1 zybo cluster 包含5块zybo 开发板组成一个集群,zybo的boot文件为digilent zybo reference design提 ...
随机推荐
- Python 利用pandas和matplotlib绘制饼图
这段代码使用了Pandas和Matplotlib库来绘制店铺销售数量占比的饼图.通过读取Excel文件中的数据,对店铺名称进行聚合并按销售数量降序排列,然后使用Matplotlib绘制饼图展示销售数量 ...
- VM虚拟机在添加虚拟硬盘后无法boot的解决方案
今天本想自己配一个mini Linux系统,但是在给系统增加一块硬盘的时候,发现出现以下问题 CentOS打不开(其实经过很久也能进去,但是指令全部失效) 由于不知道原因最后就重装了系统,奇怪的是,重 ...
- Hibench对大数据平台CDH/HDP基准性能测试
一.部署方式 1.1.源码/包:https://github.com/Intel-bigdata/HiBench 部署方法: https://github.com/Intel-bigdata/HiBe ...
- Python 潮流周刊#27:应该如何处理程序的错误?
你好,我是猫哥.这里每周分享优质的 Python.AI 及通用技术内容,大部分为英文.本周刊开源,欢迎投稿.另有电报频道作为副刊,补充发布更加丰富的资讯. 产品推荐 Walles.AI 是一款适用于所 ...
- Java Stream中的API你都用过了吗?
公众号「架构成长指南」,专注于生产实践.云原生.分布式系统.大数据技术分享. 在本教程中,您将通过大量示例来学习 Java 8 Stream API. Java 在 Java 8 中提供了一个新的附加 ...
- 手动部署Kraft模式Kafka集群
手动部署Kraft模式kafka集群 基本信息 IP地址 Hostname Release Kafka-Version 172.29.145.157 iamdemo1 Centos7.9 kafka_ ...
- 编程技巧 --- VS如何调试.Net源码
引言 如题,在VS中如何调试 .Net 源码呢? 一般来说,VS2022,都是默认启用 F12 转到定义能够看到源码,如果大家发现自己无法使用 F12 查看源码,可以在 "工具" ...
- windows查看GPU信息(nvidia-smi)
一般在使用windows系统的电脑时,想要了解GPU的使用情况时,我们通常会打开任务管理器去查看.但是这种方式一般只能看到简单的情况.那么我们想要了解更多的情况的话,该怎么办呢.可以在cmd中输入nv ...
- 数字孪生与GIS结合趋势背后,是市场需求的变化
随着数字化时代的来临,数字孪生和地理信息系统(GIS)作为两个独立的技术领域,正日益融合并发挥着协同作用.这一趋势的背后,是市场需求的变化和对更智能.更精准.更实用的解决方案的追求. 数字孪生与GIS ...
- 关于RichEdit的那些坑
项目开发中用到了richedit,但是并没有用到图文的功能,只是说使用他的各种属性,集成了一个自己的超文本编辑器. 开发遇到了各种坑,在这里跟大家分享下: 1: 跳转编辑界面,无法获取焦点. 通过Ri ...