(十)selenium实现微博高级搜索信息爬取
1.selenium模拟登陆
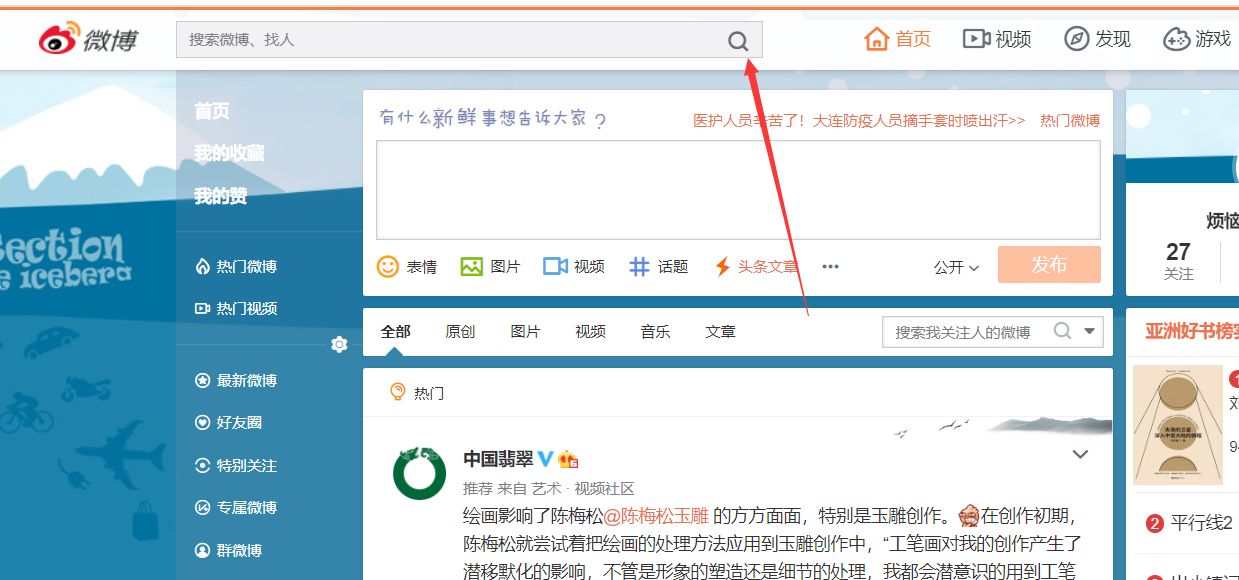
2.定位进入高级搜索页面
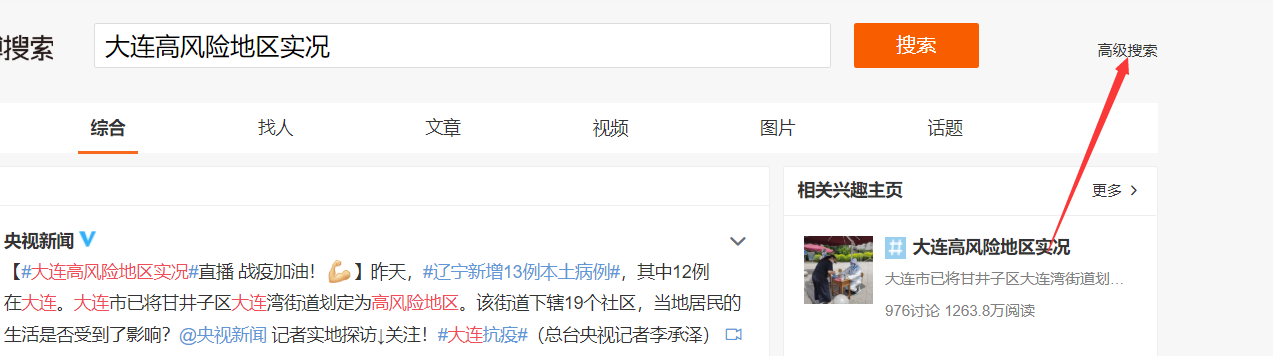
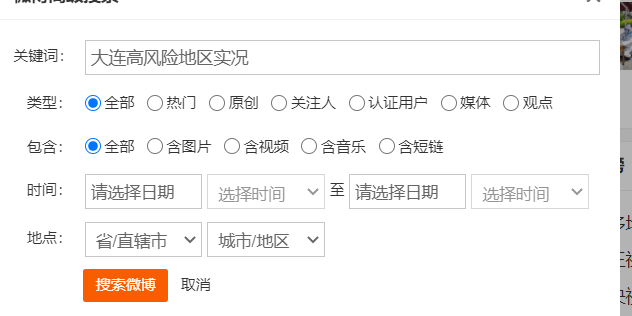
3.对高级搜索进行定位,设置。
4.代码实现
import time
from selenium import webdriver
from lxml import etree
from selenium.webdriver import ChromeOptions
import requests
from PIL import Image
from hashlib import md5
from selenium.webdriver.support.select import Select
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.92 Safari/537.36',
} # 超级鹰
class Chaojiying_Client(object):
"""超级鹰源代码""" def __init__(self, username, password, soft_id):
self.username = username
password = password.encode('utf8')
self.password = md5(password).hexdigest()
self.soft_id = soft_id
self.base_params = {
'user': self.username,
'pass2': self.password,
'softid': self.soft_id,
}
self.headers = {
'Connection': 'Keep-Alive',
'User-Agent': 'Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 5.1; Trident/4.0)',
} def PostPic(self, im, codetype):
"""
im: 图片字节
codetype: 题目类型 参考 http://www.chaojiying.com/price.html
"""
params = {
'codetype': codetype,
}
params.update(self.base_params)
files = {'userfile': ('ccc.jpg', im)}
r = requests.post('http://upload.chaojiying.net/Upload/Processing.php', data=params, files=files,
headers=self.headers)
return r.json() def ReportError(self, im_id):
"""
im_id:报错题目的图片ID
"""
params = {
'id': im_id,
}
params.update(self.base_params)
r = requests.post('http://upload.chaojiying.net/Upload/ReportError.php', data=params, headers=self.headers)
return r.json() # 输入用户名 密码
option = ChromeOptions()
option.add_experimental_option('excludeSwitches', ['enable-automation'])
url = 'https://www.weibo.com/'
bro = webdriver.Chrome(executable_path='./chromedriver.exe',options=option)
bro.maximize_window()
bro.get(url=url)
time.sleep(10) # 视网速而定
bro.find_element_by_id('loginname').send_keys('你的账号')
time.sleep(2)
bro.find_element_by_css_selector(".info_list.password input[node-type='password']").send_keys(
"你的密码")
time.sleep(1) #识别验证码
def recognize(bro):
bro.save_screenshot('weibo.png')
pic = bro.find_element_by_xpath('//div[@class="login_innerwrap"]/div[3]/div[3]/a/img')
location = pic.location
size = pic.size
rangle = (location['x'] * 1.25, location['y'] * 1.25, (location['x'] + size['width']) * 1.25,
(location['y'] + size['height']) * 1.25)
i = Image.open('./weibo.png')
code_img_name = 'code.png' # 裁剪文件的文件名称
frame = i.crop(rangle) # 根据指定区域进行裁剪
frame.save(code_img_name)
chaojiying = Chaojiying_Client('超级鹰账号', '密码', ' 905993')
im = open('./code.png', 'rb').read()
result = chaojiying.PostPic(im, 3005)['pic_str']
return result # 输入验证码
# 微博第一次点击登陆可能不成功 确保成功登陆
for i in range(5):
try:
bro.find_element_by_xpath('//div[@class="login_innerwrap"]/div[3]/div[3]/div/input').send_keys(recognize(bro))
bro.find_element_by_xpath('//div[@class="login_innerwrap"]/div[3]/div[6]/a').click()
except Exception:
continue time.sleep(5)
# 进入高级搜索页面
bro.find_element_by_xpath('//div[@class="gn_header clearfix"]/div[2]/a').click()
bro.find_element_by_xpath('//div[@class="m-search"]/div[3]/a').click()
# 填入关键词
key_word = bro.find_element_by_xpath('//div[@class="m-layer"]/div[2]/div/div[1]/dl//input')
key_word.clear()
key_word.send_keys('雾霾') # 填入地点
province = bro.find_element_by_xpath('//div[@class="m-adv-search"]/div/dl[5]//select[1]')
city = bro.find_element_by_xpath('//div[@class="m-adv-search"]/div/dl[5]//select[2]')
Select(province).select_by_visible_text('陕西')
Select(city).select_by_visible_text('西安') # 填入时间
# 起始
bro.find_element_by_xpath('//div[@class="m-adv-search"]/div[1]/dl[4]//input[1]').click() # 点击input输入框
sec_1 = bro.find_element_by_xpath('//div[@class="m-caldr"]/div/select[1]')
Select(sec_1).select_by_visible_text('一月')
sec_2 = bro.find_element_by_xpath('//div[@class="m-caldr"]/div/select[2]')
Select(sec_2).select_by_visible_text('2019')
bro.find_element_by_xpath('//div[@class="m-caldr"]/ul[2]/li[3]').click() # 起始日期 # 终止
bro.find_element_by_xpath('//div[@class="m-adv-search"]/div[1]/dl[4]//input[2]').click() # 点击input输入框
sec_1 = bro.find_element_by_xpath('//div[@class="m-caldr"]/div/select[1]')
Select(sec_1).select_by_visible_text('一月') #月份
sec_2 = bro.find_element_by_xpath('//div[@class="m-caldr"]/div/select[2]')
Select(sec_2).select_by_visible_text('2019') # 年份
bro.find_element_by_xpath('//div[@class="m-caldr"]/ul[2]/li[6]').click() # 日期 sec_3 = bro.find_element_by_xpath('//div[@class="m-adv-search"]/div[1]/dl[4]//select[2]') # 点击input输入框
Select(sec_3).select_by_visible_text('8时') # 小时
bro.find_element_by_xpath('//div[@class="btn-box"]/a[1]').click() # 爬取用户ID 发帖内容 时间 客户端 评论数 转发量 点赞数 并持久化存储
page_num = 1
with open('2019.txt','a',encoding='utf-8') as f:
while page_num<=50:
page_text = bro.page_source
tree = etree.HTML(page_text)
div_list = tree.xpath('//div[@id="pl_feedlist_index"]/div[2]/div')
for div in div_list:
try:
user_id = div.xpath('./div/div[1]/div[2]/div[1]/div[2]/a[1]/text()')[0] # 用户id
flag = div.xpath('./div/div[1]/div[2]/p[3]')
if not flag:
content = div.xpath('./div/div[1]/div[2]/p[1]')[0].xpath('string(.)') # 内容
time = div.xpath('./div/div[1]/div[2]/p[2]/a/text()')[0] # 发布时间
client = div.xpath('./div/div[1]/div[2]/p[2]/a[2]/text()')[0]
else:
content = div.xpath('./div/div[1]/div[2]/p[2]')[0].xpath('string(.)') # 内容
time = div.xpath('./div/div[1]/div[2]/p[3]/a/text()')[0] # 发布时间
client = div.xpath('./div/div[1]/div[2]/p[3]/a[2]/text()')[0] #客户端
up=div.xpath('./div/div[2]/ul/li[4]/a')[0].xpath('string(.)') #点赞数
transfer = div.xpath('./div/div[2]/ul/li[2]/a/text()')[0] # 转发量
comment = div.xpath('./div/div[2]/ul/li[3]/a/text()')[0] # 评论数
f.write('\n'+user_id+'\n'+content+'\n'+time+client+' '+transfer+' '+comment+' '+'赞'+up+'\n'+'\n')
except IndexError:
continue
if page_num ==1: # 第一页 元素位置不同 进行判断
bro.find_element_by_xpath('//div[@class="m-page"]/div/a').click()
else:
bro.find_element_by_xpath('//div[@class="m-page"]/div/a[@class="next"]').click()
page_num+=1
(十)selenium实现微博高级搜索信息爬取的更多相关文章
- selenium跳过webdriver检测并爬取淘宝我已购买的宝贝数据
简介 上一个博文已经讲述了如何使用selenium跳过webdriver检测并爬取天猫商品数据,所以在此不再详细讲,有需要思路的可以查看另外一篇博文. 源代码 # -*- coding: utf-8 ...
- Javascript动态生成的页面信息爬取和openpyxl包FAQ小记
最近,笔者在使用Requests模拟浏览器发送Post请求时,发现程序返回的html与浏览器F12观察到的略有不同,经过观察返回的response.text,cookies确认有效,因为我们可以看到返 ...
- selenium实现淘宝的商品爬取
一.问题 本次利用selenium自动化测试,完成对淘宝的爬取,这样可以避免一些反爬的措施,也是一种爬虫常用的手段.本次实战的难点: 1.如何利用selenium绕过淘宝的登录界面 2.获取淘宝的页面 ...
- 安居客scrapy房产信息爬取到数据可视化(下)-可视化代码
接上篇:安居客scrapy房产信息爬取到数据可视化(下)-可视化代码,可视化的实现~ 先看看保存的数据吧~ 本人之前都是习惯把爬到的数据保存到本地json文件, 这次保存到数据库后发现使用mongod ...
- 豆瓣电影信息爬取(json)
豆瓣电影信息爬取(json) # a = "hello world" # 字符串数据类型# b = {"name":"python"} # ...
- selenium跳过webdriver检测并爬取天猫商品数据
目录 简介 编写思路 使用教程 演示图片 源代码 @(文章目录) 简介 现在爬取淘宝,天猫商品数据都是需要首先进行登录的.上一节我们已经完成了模拟登录淘宝的步骤,所以在此不详细讲如何模拟登录淘宝.把关 ...
- Python 招聘信息爬取及可视化
自学python的大四狗发现校招招python的屈指可数,全是C++.Java.PHP,但看了下社招岗位还是有的.于是为了更加确定有多少可能找到工作,就用python写了个爬虫爬取招聘信息,数据处理, ...
- 基于selenium+phantomJS的动态网站全站爬取
由于需要在公司的内网进行神经网络建模试验(https://www.cnblogs.com/NosenLiu/articles/9463886.html),为了更方便的在内网环境下快速的查阅资料,构建深 ...
- Scrapy项目 - 实现豆瓣 Top250 电影信息爬取的爬虫设计
通过使Scrapy框架,掌握如何使用Twisted异步网络框架来处理网络通讯的问题,进行数据挖掘和对web站点页面提取结构化数据,可以加快我们的下载速度,也可深入接触各种中间件接口,灵活的完成各种需求 ...
- Scrapy项目 - 实现斗鱼直播网站信息爬取的爬虫设计
要求编写的程序可爬取斗鱼直播网站上的直播信息,如:房间数,直播类别和人气等.熟悉掌握基本的网页和url分析,同时能灵活使用Xmind工具对Python爬虫程序(网络爬虫)流程图进行分析. 一.项目 ...
随机推荐
- Fluid 助力阿里云 Serverless 容器极致提速
简介: 本文展示了一个在 ASK 环境中运行 Fluid 的完整数据访问示例,希望能够帮助大家了解 Fluid 的使用体验.运行效果以及 Serverless 和数据密集型应用结合的更多可行性. 作者 ...
- Serverless 架构下的 AI 应用开发:入门、实战与性能优化
简介: 本章通过对 Serverless 架构概念的探索,对 Serverless 架构的优势与价值.挑战与困境进行分析,以及 Serverless 架构应用场景的分享,为读者介绍 Serverles ...
- java应用提速(速度与激情)
简介: 本文将阐述通过基础设施与工具的改进,实现从构建到启动全方面大幅提速的实践和理论. 作者 | 阿里巴巴CTO技术来源 | 阿里开发者公众号 联合作者:道延 微波 沈陵 梁希 大熊 断岭 北纬 未 ...
- iLogtail使用入门-K8S环境日志采集到SLS
简介:iLogtail是阿里云中简单日志服务又名"SLS"的采集部分. 它用于收集遥测数据,例如日志.跟踪和指标,目前已经正式开源(https://github.com/alib ...
- 10个Bug环环相扣,你能解开几个?
简介:由阿里云云效主办的2021年第3届83行代码挑战赛已经收官.超2万人围观,近4000人参赛,85个团队组团来战.大赛采用游戏闯关玩儿法,融合元宇宙科幻和剧本杀元素,让一众开发者玩得不亦乐乎. ...
- [Mobi] 什么是手机 Root 和 Magisk、Magisk App
手机进行 Root 操作就是让我们能够拥有超级权限,包括被手机厂商所禁止的一些操作. 传统 Root 手段会修改系统文件,因而一些安全性要求较高的 App 会禁止自己在 Root 过的手机上运行. M ...
- dotnet OpenXML 读取 PPT 主序列进入退出强调动画
本文告诉大家如何读取 PPT 文件里面,放在主动画序列 MainSequence 的进入和退出和强调的动画,和在 OpenXML 里面的存放方式 如以下的课件内容,给一个元素添加了进入强调退出的动画, ...
- 2019-8-31-dotnet-动态代理魔法书
title author date CreateTime categories dotnet 动态代理魔法书 lindexi 2019-08-31 16:55:58 +0800 2019-06-02 ...
- EFK+logstash构建日志收集平台
一.环境 k8s集群: 控制节点:192.168.199.131 主机名:master 配置:4核6G 工作节点:192.168.199.128 主机名:monitor 配置:4核4G 1.1 ...
- LabView中使用VISA设备清零时,会发送00
最近有为小伙伴跟我说他使用串口的时候通信遇到了问题,我看到他的在程序循环中使用了VISA设备清零控件,出于好奇我就复现了一下,发现每次调用VISA设备清零控件的时候,会主动向串口中发送00数据 一.测 ...