Python-使用openpyxl读取excel内容
1. 本篇文章目标
将下面的excel中的寄存器表单读入并构建一个字典

2. openpyxl的各种基本使用方法
2.1 打开工作簿
wb = openpyxl.load_workbook('test_workbook.xlsx')
2.2 获取工作簿中工作表名字并得到工作表
ws = wb[wb.sheetnames[0]]
wb.sheetnames 会返回一个列表,列表中是每个工作表的名称,数据类型为str。执行上述代码后ws就是获取的工作表。
2.3 读取某个单元格的值
d = ws.cell(row=1, column=1).value
print(d)
使用sheet.cell会返回cell对象,再使用cell.value才能返回单元格的值,执行上述代码的结果如下:

2.4 按行读取
按行读取可以用iter_rows()方法。
for row in ws.iter_rows():
print(row)
执行上述代码的输出如下:

由图可知,该方法应当是一个迭代器,返回的是row是一个tuple,里边是各个单元格cell。可以按照如下方法获取每列的值。
import pprint as pp
excel_list = []
for row in ws.iter_rows():
row = list(row)
for i in range(len(row)):
row[i] = row[i].value
excel_list.append(row)
pp.pprint(excel_list)
这里用到了一个模块pprint,用来使打印出的列表、字典等美观易读。print结果如下:
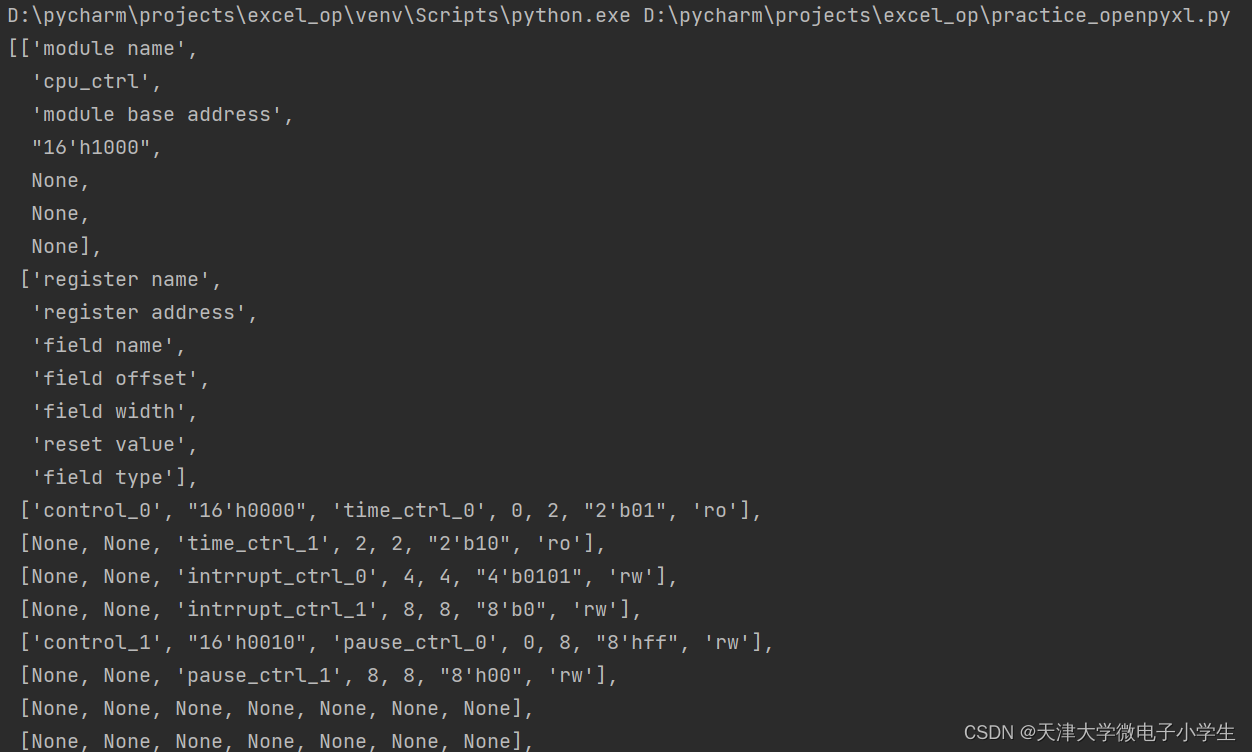
可以看到已经将excel中的内容构建了一个列表,但是下边一些没有内容的行也读了进来,尽管每个单元的值是None,这是因为之前对下边的行做过编辑,然后又删掉,导致这些无内容的单元具有单元格格式,openpyxl会将这些单元格也识别进来,所以要想避免这种情况,使用xlrd库是一种办法,或者采用下面的办法:
excel_list = []
for row in ws.iter_rows():
row = list(row)
if row[3].value != None:
for i in range(len(row)):
row[i] = row[i].value
excel_list.append(row)
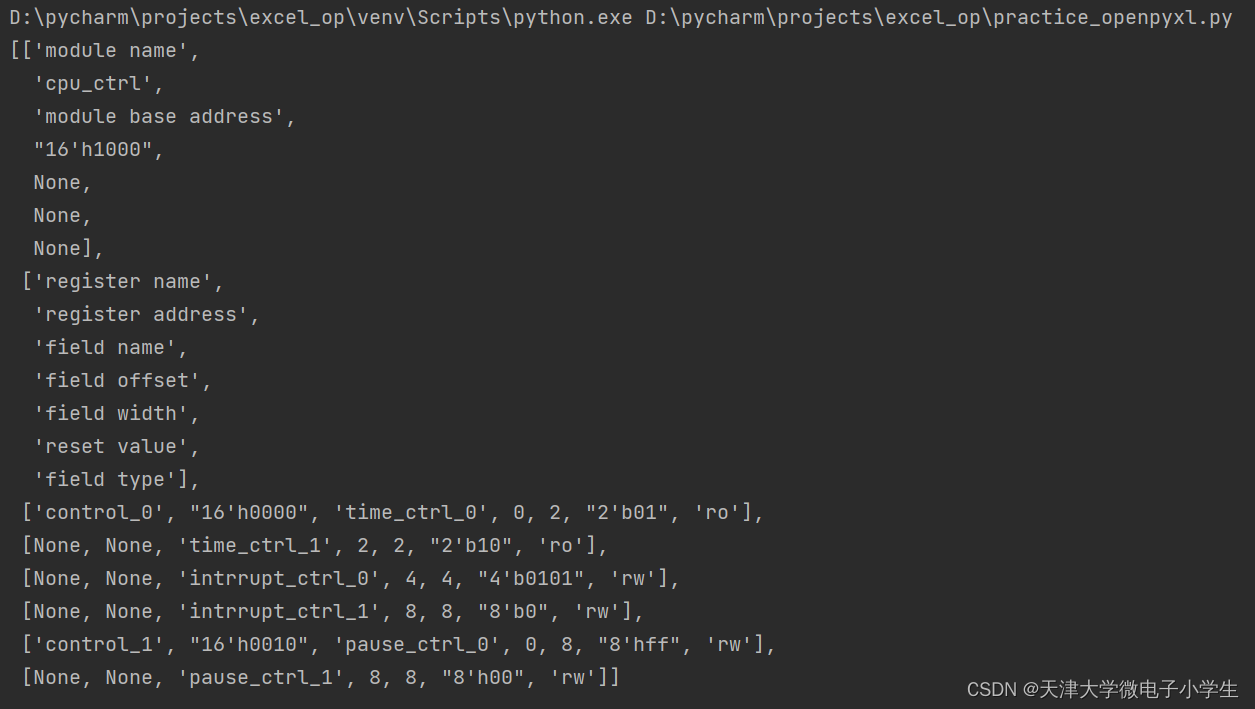
pp.pprint(excel_list)
执行结果如下,可以看到全为None的行被过滤掉了。
按列读取方法类似,使用iter_cols()。
2.5切片读取
有时候我们并不想读取表格里的全部内容,只想读取一部分,这时候可以用iter_rows()和iter_cols()的切片功能。
excel_list = []
for row in ws.iter_rows(min_row=2, min_col=2, max_row=3, max_col=3):
row = list(row)
if row[1].value != None:
for i in range(len(row)):
row[i] = row[i].value
excel_list.append(row)
pp.pprint(excel_list)
执行结果如下,可以看到只获取了表格二行二列至三行三列的内容。

2.6 利用表格行列坐标直接获取单元格、单元格的值、切片
除了上述使用sheet.cell(row, col)来获取单元格值,以及iter_rows/cols获取行、列、切片外,还可以直接用excel的行列坐标表示来获取上述内容。
pp.pprint(ws['B3']) #获取B3单元格的cell对象
pp.pprint(ws['B3'].value) #获取B3单元格cell对象的值
pp.pprint(ws['A1':'B2']) # 获取A1:B2这个切片的cell们
pp.pprint(ws['A:B']) # 获取A列到B列的所有cell对象
pp.pprint(ws[1:2]) # 获取行1到行2两行的所有cell对象
这里要注意使用这种切片、获取行列对象值的时候不能直接用.value方法,.value只是单独cell即一个单元格的cell时才能直接用,所以要想用这种方法获取切片、行列的值时要配合遍历、列表等方法构建。
2.7快速获得工作表的行们和列们
使用sheet.rows 和sheet.cols。
pp.pprint(list(ws.rows))
执行结果如下:
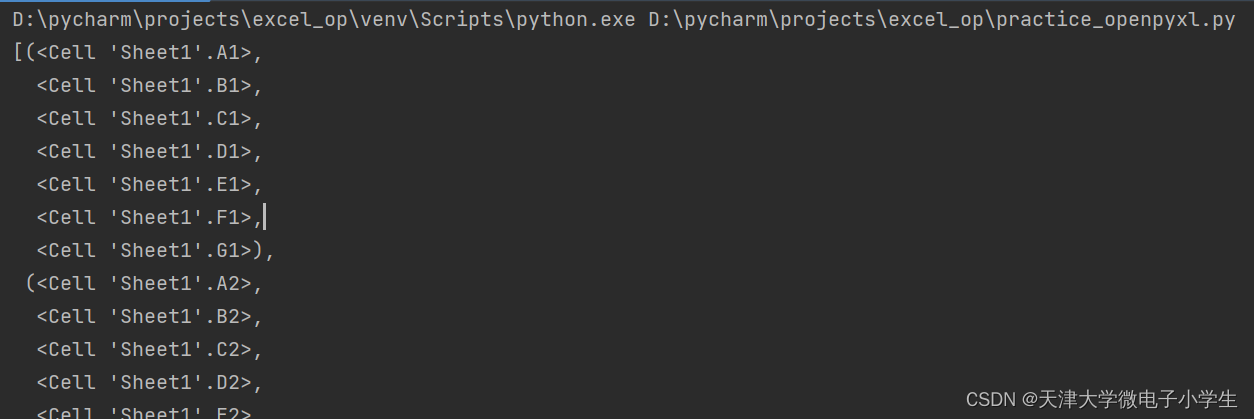
3.构建本任务所需字典
代码如下:
class ReadRegListExcel:
def __init__(self, this_ws):
self.reg_dic = {}
self.ws = this_ws
def excel_max_rows(self):
max_rows = 0
for row in ws.rows:
if row[3].value != None:
max_rows += 1
return max_rows
def construct_dic(self):
max_rows = self.excel_max_rows()
self.reg_dic['module name'] = self.ws.cell(row=1, column=2).value
self.reg_dic['module base address'] = self.ws.cell(row=1, column=4).value
self.reg_dic['registers'] = []
row = 3
all_rows = list(self.ws.rows)
print(all_rows)
while row <= max_rows:
if all_rows[row-1][0].value != None:
self.reg_dic['registers'].append({})
self.reg_dic['registers'][-1]['register name'] = all_rows[row-1][0].value
self.reg_dic['registers'][-1]['register address'] = all_rows[row-1][1].value
self.reg_dic['registers'][-1]['fields'] = [[value.value for value in all_rows[row-1][2:7]]]
else:
self.reg_dic['registers'][-1]['fields'].append([value.value for value in all_rows[row-1][2:7]])
row += 1
return self.reg_dic
if __name__ == "__main__":
reg_dic_obj = ReadRegListExcel(ws)
reg_dic = reg_dic_obj.construct_dic()
pp.pprint(reg_dic)
最后得到的寄存器字典如下:
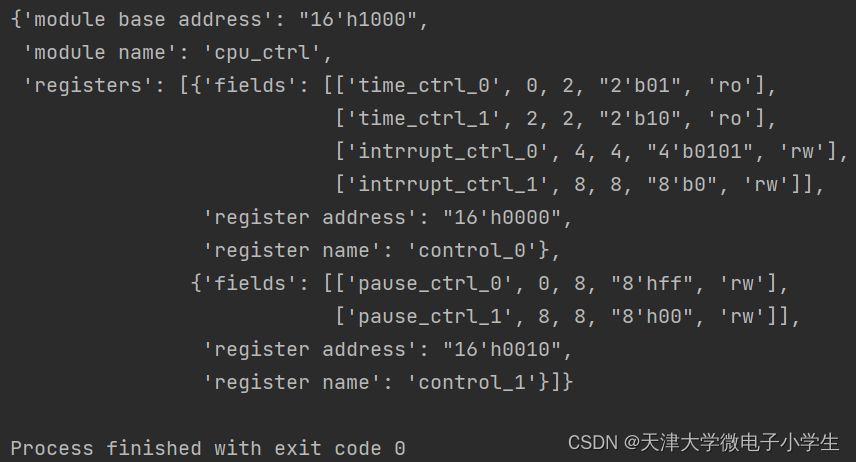
至此读入寄存器列表文件并构建出结构化的寄存器字典任务完成。
Python-使用openpyxl读取excel内容的更多相关文章
- 【转发】Python使用openpyxl读写excel文件
Python使用openpyxl读写excel文件 这是一个第三方库,可以处理xlsx格式的Excel文件.pip install openpyxl安装.如果使用Aanconda,应该自带了. 读取E ...
- Python使用openpyxl读写excel文件
Python使用openpyxl读写excel文件 这是一个第三方库,可以处理xlsx格式的Excel文件.pip install openpyxl安装.如果使用Aanconda,应该自带了. 读取E ...
- python使用xlrd读取excel数据时,整数变小数的解决办法
python使用xlrd读取excel数据时,整数变小数: 解决方法: 1.有个比较简单的就是在数字和日期的单元格内容前加上一个英文的逗号即可.如果数据比较多,也可以批量加英文逗号的前缀(网上都有方法 ...
- POI读取Excel内容格式化
在用POI读取Excel内容时,经常会遇到数据格式化的问题. 比如:数字12365会变为12365.0;字符串数字123也会变为123.0,甚至会被变为科学计数法.另外日期格式化也是一个头疼的问题.其 ...
- C# 读取Excel内容
一.方法 1.OleD方法实现该功能. 2.本次随笔内容只包含读取Excel内容,并另存为. 二.代码 (1)找到文档代码 OpenFileDialog openFile = new OpenFile ...
- Unity用Excel.dll简单读取Excel内容
Unity用Excel.dll简单读取Excel内容 需要Excel.dll 需要如下三个命名空间 using System.IO; using Excel; using System.Data; 1 ...
- 【python-excel】Selenium+python自动化之读取Excel数据(xlrd)
Selenium2+python自动化之读取Excel数据(xlrd) 转载地址:http://www.cnblogs.com/lingzeng86/p/6793398.html ·········· ...
- Python+selenium之读取配置文件内容
Python+selenium之读取配置文件内容 Python支持很多配置文件的读写,此例子中介绍一种配置文件的读取数据,叫ini文件,python中有一个类ConfigParser支持读ini文件. ...
- EasyExcel 轻松灵活读取Excel内容
写在前面 Java 后端程序员应该会遇到读取 Excel 信息到 DB 等相关需求,脑海中可能突然间想起 Apache POI 这个技术解决方案,但是当 Excel 的数据量非常大的时候,你也许发现, ...
- java poi 读取excel内容
import org.apache.poi.hssf.usermodel.HSSFWorkbook; import org.apache.poi.ss.usermodel.Row; import or ...
随机推荐
- SqlSugar分组查询
一.分组查询和使用 1.1 语法 只有在聚合对象需要筛选的时候才会用到Having,一般分组查询用不到可以去掉 var list = db.Queryable<Student>() ...
- 在K8S中,节点故障驱逐pod过程时间怎么定义?
在Kubernetes中,节点故障驱逐Pod的过程涉及多个参数和组件的相互作用.以下是该过程的简要概述: 默认设置:在默认配置下,节点故障时,工作负载的调度周期约为6分钟. 关键参数: node-mo ...
- SpringBoot 多模块开发 笔记(一)
多模块开发 简易版 dao 层 也可以说是 Mapper 层 web 层 将 controller 放在这一层 还有 统一返回类型 和 自定义异常 也在放在这里 启动类也放在这里 model 层 也就 ...
- Hello,World! 6.28
代码 public class Hello{ public static void main(String[] args){ System.out.print("Hello,World!&q ...
- NC213912 芭芭拉冲鸭~(续)
题目链接 题目 题目描述 芭芭拉这次来到了一棵字母树,这同样是一棵无根树,每个节点上面有一个小写字母. 芭芭拉想知道,自己从x冲刺到y,从x走到y收集所有字母,选择其中一部分字母组成一个回文串,这个回 ...
- 多层PCB线路板制作流程
PCB制作第一步是整理并检查pcb多层线路板布局(Layout).电路板制作工厂收到PCB设计公司的CAD文件,由于每个CAD软件都有自己独特的文件格式,所以深圳PCB板厂会转化为一个统一的格式Ger ...
- Java 21 虚拟线程如何限流控制吞吐量
虚拟线程(Virtual Threads)是 Java 21 所有新特性中最为吸引人的内容,它可以大大来简化和增强Java应用的并发性.但是,随着这些变化而来的是如何最好地管理此吞吐量的问题.本文,就 ...
- ORACLE FORALL介绍
ORACLE 10G OFFICIAL DOCUMNET ---------------------------------------------------------------------- ...
- 树莓派/Linux ubuntu 开机自动改网络mac地址(主要适用于拷贝内存卡的情况/不同树莓派mac地址不同)
树莓派/Linux ubuntu 开机自动改网络mac地址(主要适用于拷贝内存卡的情况/不同树莓派mac地址不同) yaml文件名根据自己原卡中名字更改 address=$(cat /sys/clas ...
- 如何编写一个 PowerShell 脚本
PowerShell 脚本的后缀是 .ps1 前提: ps1 脚本可以帮忙我们快速修改文件内容,还不需要调用文件的底层 api,方便快捷 在编写 CMakeLists 时发现,项目不能够很好的使用 v ...