在矩池云使用ChatGLM-6B & ChatGLM2-6B
ChatGLM-6B 和 ChatGLM2-6B都是基于 General Language Model (GLM) 架构的对话语言模型,是清华大学 KEG 实验室和智谱 AI 公司于 2023 年共同发布的语言模型。模型有 62 亿参数,一经发布便受到了开源社区的欢迎,在中文语义理解和对话生成上有着不凡的表现。
ChatGLM-6B 可以在消费级的显卡上进行本地部署(INT4 量化级别下最低只需 6GB 显存)。ChatGLM-6B 针对中文问答和对话进行了优化,经过约 1T 标识符的中英双语训练,辅以监督微调、反馈自助、人类反馈强化学习等技术的加持,已经能生成相当符合人类偏好的回答。
ChatGLM2-6B 则是开源中英双语对话模型 ChatGLM-6B 的第二代版本,在保留了初代模型对话流畅、部署门槛较低等众多优秀特性的基础之上,ChatGLM2-6B 引入了如下新特性:
更强大的性能:基于 ChatGLM 初代模型的开发经验,全面升级了 ChatGLM2-6B 的基座模型。ChatGLM2-6B 使用了 GLM 的混合目标函数,经过了 1.4T 中英标识符的预训练与人类偏好对齐训练,评测结果显示,相比于初代模型,ChatGLM2-6B 在 MMLU(+23%)、CEval(+33%)、GSM8K(+571%) 、BBH(+60%)等数据集上的性能取得了大幅度的提升,在同尺寸开源模型中具有较强的竞争力。
更长的上下文:基于 FlashAttention 技术,将基座模型的上下文长度(Context Length)由 ChatGLM-6B 的 2K 扩展到了 32K,并在对话阶段使用 8K 的上下文长度训练,允许更多轮次的对话。但当前版本的 ChatGLM2-6B 对单轮超长文档的理解能力有限,会在后续迭代升级中则有望进行优化。
更高效的推理:基于 Multi-Query Attention 技术,ChatGLM2-6B 有更高效的推理速度和更低的显存占用:在官方的模型实现下,推理速度相比初代提升了 42%,INT4 量化下,6G 显存支持的对话长度由 1K 提升到了 8K。
目前 ChatGLM-6B 以及 ChatGLM2-6B 均可通过登记进行商用,为方便大家使用,矩池云已第一时间获取到相关权限并上线了这两个模型的镜像,后续也会根据模型更新而进行镜像迭代,以下是在矩池云上使用 ChatGLM2-6B 的方法,ChatGLM-6B 的使用方法与其一致。

硬件要求
矩池云已经配置好了 ChatGLM-6B 和 ChatGLM2-6B 环境,显存需要大于13G。可以选择 A4000、P100、3090 或更高配置的显卡。
租用机器
在矩池云主机市场:https://matpool.com/host-market/gpu,选择显存大于13G的机器,比如 A4000 显卡,然后点击租用按钮(选择其他满足显存要求的显卡也可以)。
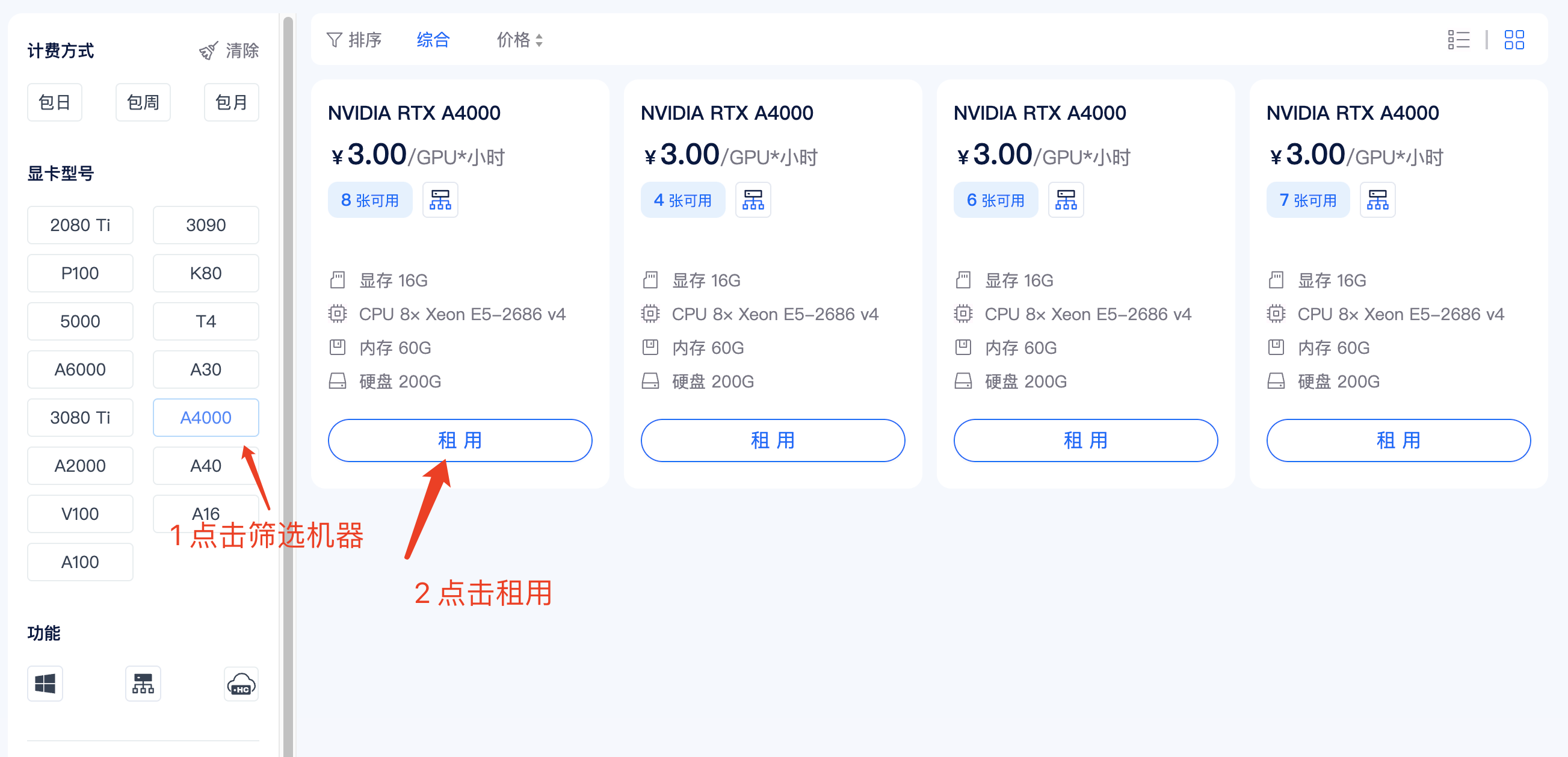
租用页面,搜索 ChatGLM2-6B,选择这个镜像,再点击租用即可。
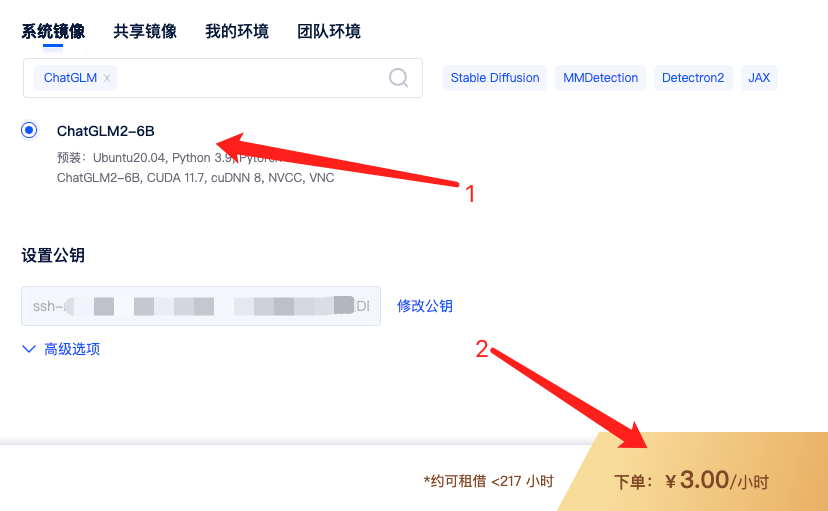
机器租用成功后,你会看到 8000 端口对应链接,这是 ChatGLM2-6B 默认的 api 接口,镜像已经设置了开机自启,也就是说现在可以直接调用这个接口使用 ChatGLM2-6B 了。

使用 ChatGLM2-6B api
调用 ChatGLM2-6B api 需要发送 POST 请求。前面租用机器我们自定义了 8000 端口,在租用页面可以获得对应的公网链接,比如:https://hz.xxxx.com:xxxx/?token=xxxxx
需要注意,实际我们请求不需要 token,所以直接用:https://hz.xxxx.com:xxxx 这段即可。
curl请求:
curl -X POST "https://hz.xxxx.com:xxxx" \
-H 'Content-Type: application/json' \
-d '{"prompt": "你好", "history": []}'
Python请求:
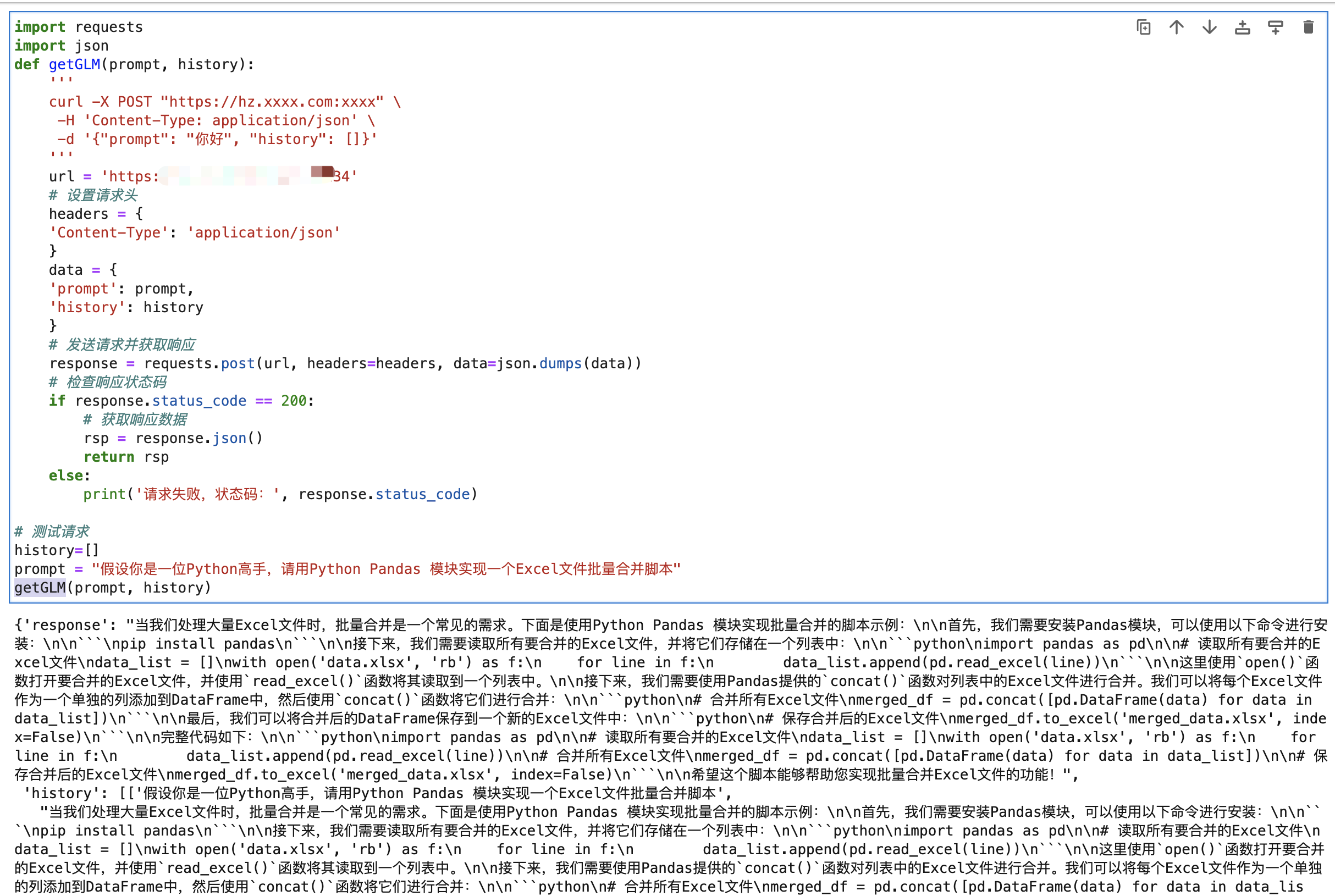
import requests
import json
def getGLM(prompt, history):
'''
curl -X POST "https://hz.xxxx.com:xxxx" \
-H 'Content-Type: application/json' \
-d '{"prompt": "你好", "history": []}'
'''
url = 'https://hz.xxxx.com:xxxx'
# 设置请求头
headers = {
'Content-Type': 'application/json'
}
data = {
'prompt': prompt,
'history': history
}
# 发送请求并获取响应
response = requests.post(url, headers=headers, data=json.dumps(data))
# 检查响应状态码
if response.status_code == 200:
# 获取响应数据
rsp = response.json()
return rsp
else:
print('请求失败,状态码:', response.status_code)
# 测试请求
history=[]
prompt = "假设你是一位Python高手,请用Python Pandas 模块实现一个Excel文件批量合并脚本"
getGLM(prompt, history)
A4000 回复复杂点的问题(回复字数1.5k左右),耗时 20-40s 左右。
ChatGLM2-6B 也有 web demo,大家也可以运行测试,具体的使用方法如下文。
运行 ChatGLM2-6B web demo
首先我们需要 kill 掉系统开启自启的 ChatGLM2-6B API 服务,Jupyterlab 里新建一个 Terminal,然后输入下面指令查看api服务器进程id。
ps aux | grep api.py

kill 掉相关进程,从上面运行结果可以看出,api.py 进程id是5869,执行下面指令即可 kill 相关进程:
# 注意 5869 换成你自己租用服务器里查出来的 api.py 程序的进程id
# 注意 5869 换成你自己租用服务器里查出来的 api.py 程序的进程id
# 注意 5869 换成你自己租用服务器里查出来的 api.py 程序的进程id
kill 5869
运行 ChatGLM2-6B 版本 运行
# 进入项目目录
cd /ChatGLM2-6B
# 安装依赖
pip install streamlit streamlit_chat
# 启动脚本
streamlit run web_demo2.py --server.port 8000 --server.address 0.0.0.0

运行后服务会启动到 8000端口,host 设置成0.0.0.0,这样我们访问租用页面 8000 端口链接即可访问到对应服务了。
前面租用机器我们自定义了 8000 端口,在租用页面可以获得对应的公网链接:
比如:https://hz.xxxx.com:xxxx/?token=xxxxx
需要注意的是,实际上我们在请求时候不需要 token,所以使用的地址直接用:https://hz.xxxx.com:xxxx 这段即可。

浅尝试一下生成的效果还不错,这个问题的回答有点出乎意料,给了一个用 pygame 写的猜数游戏,其他的一些模型一般回复的内容都是 cmd 版本的。

在矩池云使用ChatGLM-6B & ChatGLM2-6B的更多相关文章
- 矩池云上使用nvidia-smi命令教程
简介 nvidia-smi全称是NVIDIA System Management Interface ,它是一个基于NVIDIA Management Library(NVML)构建的命令行实用工具, ...
- 矩池云里查看cuda版本
可以用下面的命令查看 cat /usr/local/cuda/version.txt 如果想用nvcc来查看可以用下面的命令 nvcc -V 如果环境内没有nvcc可以安装一下,教程是矩池云上如何安装 ...
- 在矩池云上复现 CVPR 2018 LearningToCompare_FSL 环境
这是 CVPR 2018 的一篇少样本学习论文:Learning to Compare: Relation Network for Few-Shot Learning 源码地址:https://git ...
- 矩池云上安装yolov4 darknet教程
这里我是用PyTorch 1.8.1来安装的 拉取仓库 官方仓库 git clone https://github.com/AlexeyAB/darknet 镜像仓库 git clone https: ...
- 用端口映射的办法使用矩池云隐藏的vnc功能
矩池云隐藏了很多高级功能待用户去挖掘. 租用机器 进入jupyterlab 设置vnc密码 VNC_PASSWD="userpasswd" ./root/vnc_startup.s ...
- 矩池云上安装ikatago及远程链接教程
https://github.com/kinfkong/ikatago-resources/tree/master/dockerfiles 从作者的库中可以看到,该程序支持cuda9.2.cuda10 ...
- 矩池云上编译安装dlib库
方法一(简单) 矩池云上的k80因为内存问题,请用其他版本的GPU去进行编译,保存环境后再在k80上用. 准备工作 下载dlib的源文件 进入python的官网,点击PyPi选项,搜索dilb,再点击 ...
- 如何在矩池云上运行FinRL-Libray股票交易策略框架
FinRL-Libray 项目:https://github.com/AI4Finance-LLC/FinRL-Library 选择FinRL镜像 在矩池云-主机市场选择合适的机器,并选择FinRL- ...
- 使用 MobaXterm 连接矩池云 GPU服务器
Host Name(主机名):hz.matpool.com 或 hz-t2.matpool.com,请以您 SSH 中给定的域名为准. Port(端口号):矩池云租用记录里 SSH 链接里冒号后的几位 ...
- 矩池云上TensorBoard/TensorBoardX配置说明
Tensorflow用户使用TensorBoard 矩池云现在为带有Tensorflow的镜像默认开启了6006端口,那么只需要在租用后使用命令启动即可 tensorboard --logdir lo ...
随机推荐
- JVM内存学习 2.0
先说一下结果 1. Linux的内存分配是惰性分配的. APP申明了 kernel并不会立即进行初始化和使用. 2. JVM的内存主要分为, 堆区, 非堆区, 以及jvm使用的其他内存. 比如直接内存 ...
- 重新学习一下new Date()
new Date()你知道多少 很多小伙伴可能都知道, Date是js中的一个内置对象,用于处理日期和时间. 当你调用 new Date() 时,它会创建一个新的日期(Date) 对象. 表示当前本地 ...
- 使用css 与 js 两种方式实现导航栏吸顶效果
场景描述 简单的说一下场景描述:这个页面有三个部分组成的. 顶部的头部信息--导航栏--内容 当页面滚动的时候.导航栏始终是固定在最顶部的. 我们使用的第一种方案就是使用css的粘性定位 positi ...
- vue新一轮的面试题
参考的连接: https://juejin.cn/post/6844903876231954446 1. 在vue中watch和created哪个先执行?为什么? 在wacth监控数据时,设置imme ...
- CLion搭建Qt开发环境,并解决目录重构问题(最新版)
序言 Qt版本不断更新,QtCreator也不断更新.在Qt4和Qt5时代,我一直认为开发Qt最好的IDE就是自带的QtCreator,可是时至今日,到了Qt6时代,QtCreator已经都12.0. ...
- RC4加密技术探究:优缺点与实战应用
引言 在网络安全领域,加密技术一直是保障数据安全的重要手段.Rivest Cipher 4(简称RC4)作为一种对称加密算法,自20世纪80年代以来广泛应用于各种网络安全协议中.本文将详细分析RC4加 ...
- Dubbo3应用开发—Dubbo注册中心引言
Dubbo注册中心引言 什么是Dubbo注册中心 Dubbo的注册中心,是Dubbo服务治理的⼀个重要的概念,他主要用于 RPC服务集群实例的管理. 注册中心的运行流程 使用注册中心的好处 可以有效的 ...
- 不同版本的Unity要求的NDK版本和两者对应关系表(Unity NDK Version Match)
IL2CPP需要NDK Unity使用IL2CPP模式出安卓包时,需要用到NDK,如果没有安装则无法导出Android Studio工程或直接生成APK,本篇记录一下我下载NDK不同版本的填坑过程. ...
- vim 从嫌弃到依赖(12)——打开及保存文件
在前几篇文章中,我们从vim各种模式的使用着手介绍了vim如何进行文本本身的编辑.也通过缓冲区列表的介绍了解到了vim是如何进行打开文件的管理.这篇我们将会着眼于文件的打开和保存的基本操作.通过这篇的 ...
- Keepalive-Haproxy高可用介绍
假设我们现在开发了一个应用应用的端口号为 8080,这个应用我们想让它去实现一个负载均衡的访问,就是说我们有两台服务器都部署了我们的 8080 应用,我们想让它一会访问 ip 为: 192.168.0 ...