spark 中怎么像 pandas 里面对时间数据做 resample
1. 笨办法
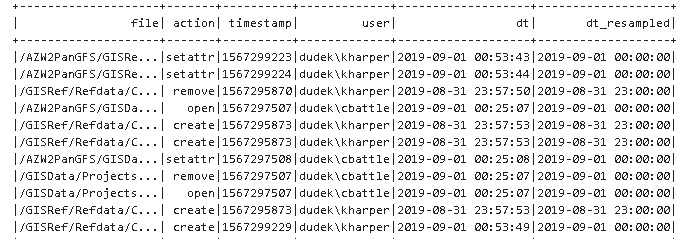
pandas Dataframe 可以很容易做时序数据的 resample,按照一定的frequency 聚合数据. 但是spark 中因为没有顺序的概念就不太好做,下面是怎么在spark中做resample 的例子.
def resample(column, agg_interval=900, time_format='yyyy-MM-dd HH:mm:ss'):
if type(column)==str:
column = F.col(column) # Convert the timestamp to unix timestamp format.
# Unix timestamp = number of seconds since 00:00:00 UTC, 1 January 1970.
col_ut = F.unix_timestamp(column, format=time_format) # Divide the time into dicrete intervals, by rounding.
col_ut_agg = F.floor(col_ut / agg_interval) * agg_interval # Convert to and return a human readable timestamp
return F.from_unixtime(col_ut_agg) df = df.withColumn('dt_resampled', resample(df.dt, agg_interval=3600)) # 1h resample
df.show()
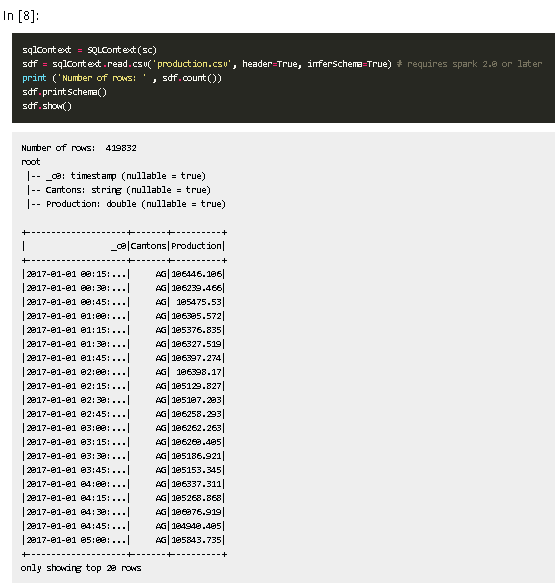
2. 新办法
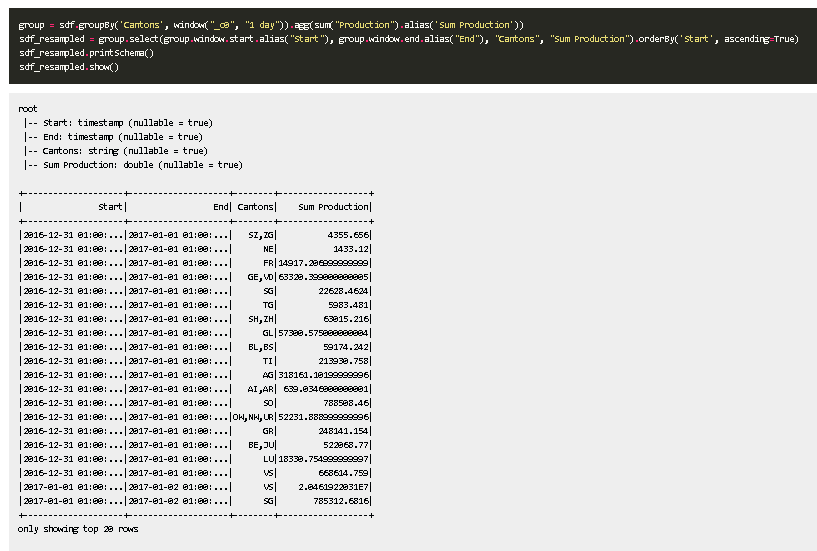
使用 groupby + window
Ref:
https://mihevc.org/2016/09/28/spark-resampling.html 笨办法但是容易理解
https://rsandstroem.github.io/sparkdataframes.html#Resampling-time-series-with-Spark 新办法
spark 中怎么像 pandas 里面对时间数据做 resample的更多相关文章
- pandas将字段中的字符类型转化为时间类型,并设置为索引
假设目前已经引入了 pandas,同时也拥有 pandas 的 DataFrame 类型数据. import pandas as pd 数据集如下 df.head(3) date open close ...
- SPARK 中 DriverMemory和ExecutorMemory
spark中,不论spark-shell还是spark-submit,都可以设置memory大小,但是有的同学会发现有两个memory可以设置.分别是driver memory 和executor m ...
- 【原】Spark中Master源码分析(二)
继续上一篇的内容.上一篇的内容为: Spark中Master源码分析(一) http://www.cnblogs.com/yourarebest/p/5312965.html 4.receive方法, ...
- Spark中的Scheduler
Spark中的Scheduler scheduler分成两个类型.一个是TaskScheduler与事实上现,一个是DAGScheduler. TaskScheduler:主要负责各stage中传入的 ...
- Spark中的键值对操作-scala
1.PairRDD介绍 Spark为包含键值对类型的RDD提供了一些专有的操作.这些RDD被称为PairRDD.PairRDD提供了并行操作各个键或跨节点重新进行数据分组的操作接口.例如,Pa ...
- Spark中的键值对操作
1.PairRDD介绍 Spark为包含键值对类型的RDD提供了一些专有的操作.这些RDD被称为PairRDD.PairRDD提供了并行操作各个键或跨节点重新进行数据分组的操作接口.例如,Pa ...
- spark 中的RDD编程 -以下基于Java api
1.RDD介绍: RDD,弹性分布式数据集,即分布式的元素集合.在spark中,对所有数据的操作不外乎是创建RDD.转化已有的RDD以及调用RDD操作进行求值.在这一切的背后,Spark会自动 ...
- 【Spark篇】---Spark中控制算子
一.前述 Spark中控制算子也是懒执行的,需要Action算子触发才能执行,主要是为了对数据进行缓存. 控制算子有三种,cache,persist,checkpoint,以上算子都可以将RDD持久化 ...
- 【原创】大叔问题定位分享(11)Spark中对大表子查询加limit为什么会报Broadcast超时错误
当两个表需要join时,如果一个是大表,一个是小表,正常的map-reduce流程需要shuffle,这会导致大表数据在节点间网络传输,常见的优化方式是将小表读到内存中并广播到大表处理,避免shuff ...
- Hanlp分词1.7版本在Spark中分布式使用记录
新发布1.7.0版本的hanlp自然语言处理工具包差不多已经有半年时间了,最近也是一直在整理这个新版本hanlp分词工具的相关内容.不过按照当前的整理进度,还需要一段时间再给大家详细分享整理的内容.昨 ...
随机推荐
- 大语言模型的应用探索—AI Agent初探!
前言 大语言模型的应用之一是与大语言模型进行聊天也就是一个ChatBot,这个应用已经很广泛了. 接下来的一个应用就是AI Agent. AI Agent是人工智能代理(Artificial Inte ...
- C# 线程与进程
一.前台线程与后台线程对象 为什么要用多线程? 1.让计算机"同时"做多件事情,节约时间. 2.多线程可以让一个程序"同时"处理多个事情. 3.后台运行程序,提 ...
- linux环境搭建mysql5.7总结
以下安装方式,在阿里云与腾讯云服务器上都测试可用. 一.进入到opt目录下,执行: [root@master opt]# wget https://dev.mysql.com/get/Download ...
- nginx负载均衡session共享解决方案
解决方案: 1.使用客户端的cookie作为存放登录信息的媒介 cookie是将用户登录信息存储在用户终端的数据载体,与session的最大区别就是,session是存储在服务器端的:所以这就很容易解 ...
- 洛谷P10693
洛谷P10693 好奇怪的题目编号 思路提取 input 11 2 13 4 5 3 7 9 9 11 11 12 output 9 以人造数据为例. 首先我们让\(i\)\(\to\)\(a_i\) ...
- Cython与C函数的结合
技术背景 在前面一篇博客中,我们介绍了使用Cython加速谐振势计算的方法.有了Cython对于计算过程更加灵活的配置(本质上是时间占用和空间占用的一种均衡),及其接近于C的性能,并且还最大程度上的保 ...
- mysql 主从复制 + thinkphp 读写分离
好处:加快查询速度.数据库热备份等 注意:要跨服务器,先准备一个虚拟机或者docker,同一个服务器意义不大,而且风险大. 注意:本文档学习原理使用,线上可使用阿里云rds自带的读写分离 主从复制: ...
- 【MySQL】Windows-5.7.30 解压版 下载安装
1.Download 下载 mysql官网: https://dev.mysql.com/ 找到download点击进入下载页面: https://dev.mysql.com/downloads/ 找 ...
- nvidia 机器人仿真环境Isaac Sim
- 【转载】 t-SNE是什么? —— 使用指南
原文地址: https://www.cnblogs.com/LuckBelongsToStrugglingMan/p/14161405.html 转者前言: 该文相当于一个 t-SNE 使用指南, ...