httprunner3源码解读(2)models.py
源码目录结构
我们首先来看下models.py的代码结构
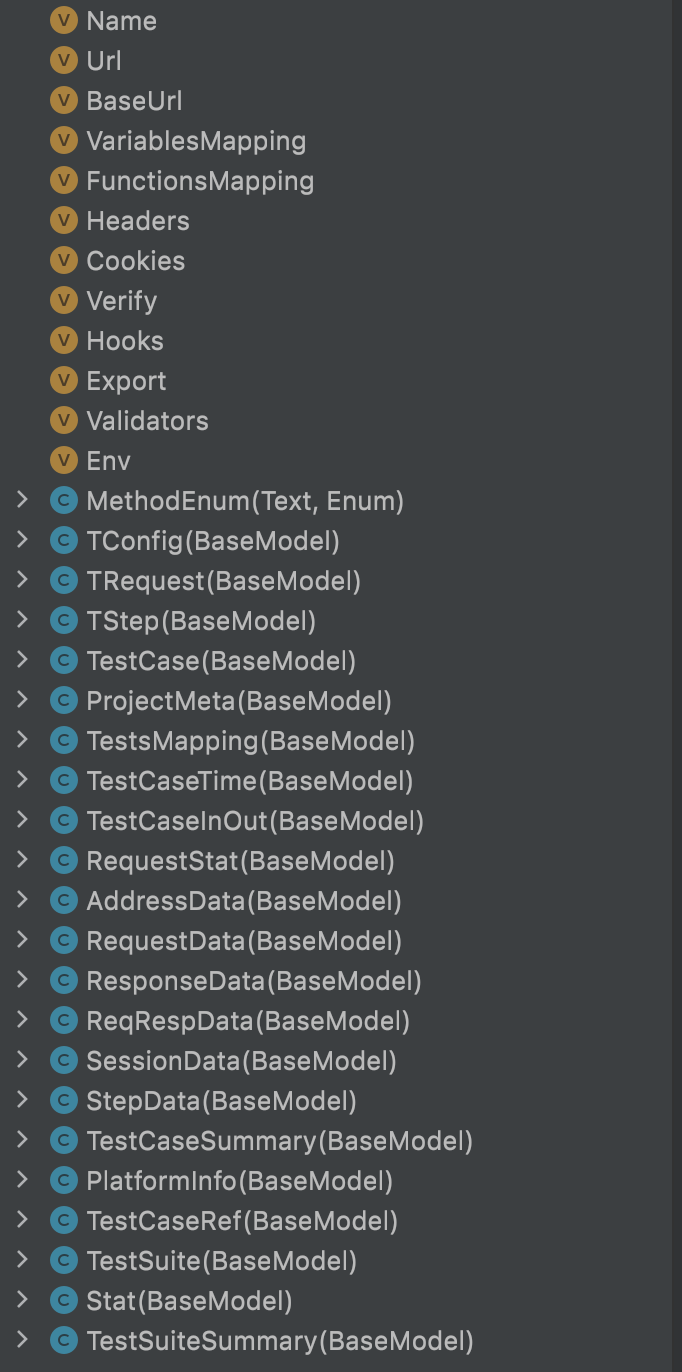
我们可以看到这个模块中定义了12个属性和22个模型类,我们依次来看
属性源码分析
import os
from enum import Enum
from typing import Any
from typing import Dict, Text, Union, Callable
from typing import List
from pydantic import BaseModel, Field
from pydantic import HttpUrl
Name = Text
Url = Text
BaseUrl = Union[HttpUrl, Text]
VariablesMapping = Dict[Text, Any]
FunctionsMapping = Dict[Text, Callable]
Headers = Dict[Text, Text]
Cookies = Dict[Text, Text]
Verify = bool
Hooks = List[Union[Text, Dict[Text, Text]]]
Export = List[Text]
Validators = List[Dict]
Env = Dict[Text, Any]
一句话总结:用到了typing和pydantic模块,目的是告诉读者我这些属性是什么类型的
模型类源码分析
这里以代码注解的方式讲解
MethodEnum
class MethodEnum(Text, Enum):
"""
枚举请求方法,定义了常用的http请求方法
"""
GET = "GET"
POST = "POST"
PUT = "PUT"
DELETE = "DELETE"
HEAD = "HEAD"
OPTIONS = "OPTIONS"
PATCH = "PATCH
TConfig
class TConfig(BaseModel):
"""
定义配置信息,包含如下:
1.name (str)
2.verify (bool)
3.base_url (http/https开头的str类型)
4.variables (dict)
5.parameters(dict)
6.export (list[str])
7.path (str)
8.weight (int)
"""
name: Name # str类型
verify: Verify = False
base_url: BaseUrl = ""
# Text: prepare variables in debugtalk.py, ${gen_variables()}
variables: Union[VariablesMapping, Text] = {}
parameters: Union[VariablesMapping, Text] = {}
# setup_hooks: Hooks = []
# teardown_hooks: Hooks = []
export: Export = []
path: Text = None
weight: int = 1
TRequest
class TRequest(BaseModel):
"""
requests.Request model
1.method (枚举类型)
2.url (str)
3.params (dict)
4.headers (dict)
5.req_json(dict/list/str)
6.data (dict/str)
7.cookie (dict)
8.timeout (float)
9.allow_redirects (bool)
10.verify (bool)
11.upload (dict)
"""
method: MethodEnum
url: Url
params: Dict[Text, Text] = {}
headers: Headers = {}
req_json: Union[Dict, List, Text] = Field(None, alias="json")
data: Union[Text, Dict[Text, Any]] = None
cookies: Cookies = {}
timeout: float = 120
allow_redirects: bool = True
verify: Verify = False
upload: Dict = {} # used for upload files
TStep
class TStep(BaseModel):
"""
测试步骤,里面包含了request请求
1.name (str)
2.request (TRequest)
3.testcase (str/Callable)
4.variables (dict)
5.setup_hooks (list(dict))
6.teardown_hooks (list(dict))
7.extract (dict)
8.export (list)
9.validators (list(dict))
10.validate_script (list[str])
"""
name: Name
request: Union[TRequest, None] = None
testcase: Union[Text, Callable, None] = None
variables: VariablesMapping = {}
setup_hooks: Hooks = []
teardown_hooks: Hooks = []
# used to extract request's response field
extract: VariablesMapping = {}
# used to export session variables from referenced testcase
export: Export = []
validators: Validators = Field([], alias="validate")
validate_script: List[Text] = []
TestCase
class TestCase(BaseModel):
"""
测试用例,包含了测试步骤和配置信息
"""
config: TConfig
teststeps: List[TStep]
ProjectMeta
class ProjectMeta(BaseModel):
"""
项目结构
1.debugtalk_py (str) debugtakl文件内容
2.debugtalk_path (str) debugtalk文件路径
3.dot_env_path (str) env文件路径
4.functions (dict(Callable/str)) 在debugtalk中定义的函数
5.env (dict) 环境
6.RootDir (str) 根路径(绝对路径),debugtalk位于的路径
"""
debugtalk_py: Text = "" # debugtalk.py file content
debugtalk_path: Text = "" # debugtalk.py file path
dot_env_path: Text = "" # .env file path
functions: FunctionsMapping = {} # functions defined in debugtalk.py
env: Env = {}
RootDir: Text = os.getcwd() # project root directory (ensure absolute), the path debugtalk.py located
TestsMapping
class TestsMapping(BaseModel):
"""
测试映射
1.project_meta
2.testcases 测试用例集,list下有多个用例
"""
project_meta: ProjectMeta
testcases: List[TestCase]
TestCaseTime
class TestCaseTime(BaseModel):
"""
测试用例时间
1.start_at:开始时间默认为0
2.start_at_iso_format:以iso格式启动
3.duration:持续时间
"""
start_at: float = 0
start_at_iso_format: Text = ""
duration: float = 0
TestCaseInOut
class TestCaseInOut(BaseModel):
"""
测试用例的输入输出:
config_vars:配置变量
export_vars:导出变量
"""
config_vars: VariablesMapping = {}
export_vars: Dict = {}
RequestStat
class RequestStat(BaseModel):
"""
请求指标:
content_size:内容大小
response_time_ms:响应时间(ms)
elapsed_ms:逝去的时间(ms)
"""
content_size: float = 0
response_time_ms: float = 0
elapsed_ms: float = 0
AddressData
class AddressData(BaseModel):
"""
客户端与服务器地址数据
client_ip:客户端ip地址
client_port:客户端端口号
server_ip:服务器ip地址
server_port:服务器端口号
"""
client_ip: Text = "N/A"
client_port: int = 0
server_ip: Text = "N/A"
server_port: int = 0
RequestData
class RequestData(BaseModel):
"""
请求数据
method:请求方法,默认为GET
url:url地址
headers:请求头
cookies:cookie信息
body:请求体
"""
method: MethodEnum = MethodEnum.GET
url: Url
headers: Headers = {}
cookies: Cookies = {}
body: Union[Text, bytes, List, Dict, None] = {}
ResponseData
class ResponseData(BaseModel):
"""
响应数据
status_code:状态码
headers:响应头
cookies:cookie信息
encoding:编码格式
content_type:内容类型
body:响应体
"""
status_code: int
headers: Dict
cookies: Cookies
encoding: Union[Text, None] = None
content_type: Text
body: Union[Text, bytes, List, Dict]
ReqRespData
class ReqRespData(BaseModel):
"""
请求响应数据
request:RequestData
response:ResponseData
"""
request: RequestData
response: ResponseData
SessionData
class SessionData(BaseModel):
"""
request session data, including request, response, validators and stat data
"""
success: bool = False
# in most cases, req_resps only contains one request & response
# while when 30X redirect occurs, req_resps will contain multiple request & response
req_resps: List[ReqRespData] = []
stat: RequestStat = RequestStat()
address: AddressData = AddressData()
validators: Dict = {}
StepData
class StepData(BaseModel):
"""
teststep data, each step maybe corresponding to one request or one testcase
测试步骤数据,每个步骤可能对应一个请求或一个测试用例
"""
success: bool = False
name: Text = "" # teststep name
data: Union[SessionData, List['StepData']] = None
export_vars: VariablesMapping = {}
TestCaseSummary
class TestCaseSummary(BaseModel):
"""
测试用例结果
name:测试用例名字
success:测试用例成功的状态
case_id:测试用例的id
time:测试用例的时间
in_out:测试用例的导入导出数据
log:测试用例的日志
step_datas:测试步骤的数据
"""
name: Text
success: bool
case_id: Text
time: TestCaseTime
in_out: TestCaseInOut = {}
log: Text = ""
step_datas: List[StepData] = []
PlatformInfo
class PlatformInfo(BaseModel):
"""
平台信息
httprunner_version:httprunner版本号
python_version:python版本
platform:平台
"""
httprunner_version: Text
python_version: Text
platform: Text
TestCaseRef
class TestCaseRef(BaseModel):
"""
包含testcase
"""
name: Text
base_url: Text = ""
testcase: Text
variables: VariablesMapping = {}
TestSuite
class TestSuite(BaseModel):
"""
测试套件
TestSuite包含TestCaseRef
TestCaseRef包含testcase
"""
config: TConfig
testcases: List[TestCaseRef]
Stat
class Stat(BaseModel):
"""
统计信息
total:总数
success:成功的用例数
fail:失败的用例数
"""
total: int = 0
success: int = 0
fail: int = 0
TestSuiteSummary
class TestSuiteSummary(BaseModel):
"""
测试套件结果
success:成功的状态
stat:统计信息
time:测试用例花费的时间
platform:平台信息
testcases:测试用例集
"""
success: bool = False
stat: Stat = Stat()
time: TestCaseTime = TestCaseTime()
platform: PlatformInfo
testcases: List[TestCaseSummary]
httprunner3源码解读(2)models.py的更多相关文章
- httprunner3源码解读(4)parser.py
源码结构目录 可以看到此模块定义了4个属性和12个函数,我们依次来讲解 属性源码分析 # 匹配http://或https:// absolute_http_url_regexp = re.compil ...
- httprunner3源码解读(3)client.py
源码目录结构 ApiResponse 这个类没啥好说的 class ApiResponse(Response): """ 继承了requests模块中的Response类 ...
- httprunner3源码解读(1)简单介绍源码模块内容
前言 最近想着搭建一个API测试平台,基础的注册登录功能已经完成,就差测试框架的选型,最后还是选择了httprunner,github上已经有很多开源的httprunner测试平台,但是看了下都是基于 ...
- pyspider源码解读--调度器scheduler.py
pyspider源码解读--调度器scheduler.py scheduler.py首先从pyspider的根目录下找到/pyspider/scheduler/scheduler.py其中定义了四个类 ...
- DRF(1) - REST、DRF(View源码解读、APIView源码解读)
一.REST 1.什么是编程? 数据结构和算法的结合. 2.什么是REST? 首先回顾我们曾经做过的图书管理系统,我们是这样设计url的,如下: /books/ /get_all_books/ 访问所 ...
- REST、DRF(View源码解读、APIView源码解读)
一 . REST 前言 1 . 编程 : 数据结构和算法的结合 .小程序如简单的计算器,我们输入初始数据,经过计算,得到最终的数据,这个过程中,初始数据和结果数据都是数据,而计算 ...
- Restful 1 -- REST、DRF(View源码解读、APIView源码解读)及框架实现
一.REST 1.什么是编程? 数据结构和算法的结合 2.什么是REST? - url用来唯一定位资源,http请求方式来区分用户行为 首先回顾我们曾经做过的图书管理系统,我们是这样设计url的,如下 ...
- Bert系列(三)——源码解读之Pre-train
https://www.jianshu.com/p/22e462f01d8c pre-train是迁移学习的基础,虽然Google已经发布了各种预训练好的模型,而且因为资源消耗巨大,自己再预训练也不现 ...
- 如何判断一个Http Message的结束——python源码解读
HTTP/1.1 默认的连接方式是长连接,不能通过简单的TCP连接关闭判断HttpMessage的结束. 以下是几种判断HttpMessage结束的方式: 1. HTTP协议约定status ...
随机推荐
- JMeter主要元件
配置元件 http cookie管理器 http信息头管理器 http请求默认值 统一管理 快速切换测试环境 http cache管理器 静态资源 监听器元件 查看结果树 分析查看某个请求的详情 请求 ...
- Android命令行启动模拟器
我们在平时的开发中会经常需要使用模拟器进行调试,这个时候我们就要先打开Android Studio来启动模拟器,然后再运行App.这个流程中启动Android Studio需要花费一些时间,而模拟器的 ...
- 在modal中的datetimepicker插件BUG修复
前言:因为在模态框用到datetimepicker这一日期控件,而选中日期时,会触发模态框的再次打开,导致上面表单选的值会重新加载 解决办法: 用stopPropagation() 方法阻止事件传播, ...
- Mybatis里@InsertProvider、@UpdateProvider方法里使用if test标签
例如: ··· insert into TEST1(<if test="base_id!=null and base_id!=''">base_id,</if&g ...
- vue 移动端项目切换页面,页面置顶
之前项目是pc端是使用router的方式实现置顶的 //main.js router.afterEach((to, from, next) => { window.scrollTo(0, 0) ...
- vue-devtools 安装
vue火了很久了,但是一直赶不上时代步伐的我今天才开始学,首先,根据vue官网介绍,推荐安装Vue Devtools.它允许你在一个更友好的界面中审查和调试 Vue 应用. 首先,将vue-devto ...
- MySQL5.7.26二进制安装
1.安装系统版本 2.解压更换路径 tar xf mysql-5.7.26-linux-glibc2.12-x86_64.tar.gz mv mysql-5.7.26-linux-glibc2.12- ...
- 如何用redis统计海量UV?
前言 我们先思考一个常见的业务问题:如果你负责开发维护一个大型的网站,有一天老板找产品经理要网站每个网页每天的 UV 数据,然后让你来开发这个统计模块,你会如何实现? 统计uv的常用方法以及优缺点 其 ...
- js Promise用法
Promise 英文意思是 承诺的意思,是对将来的事情做了承诺, Promise 有三种状态, Pending 进行中或者等待中 Fulfilled 已成功 Rejected 已失败 Promise ...
- 洛谷4234最小差值生成树 (LCT维护生成树)
这也是一道LCT维护生成树的题. 那么我们还是按照套路,先对边进行排序,然后顺次加入. 不过和别的题有所不同的是: 在本题中,我们需要保证LCT中正好有\(n-1\)条边的时候,才能更新\(ans\) ...