Working hard to know your neighbor's margins:Local descriptor learning loss论文笔记
Abstract
论文提出了一种新的训练方法,受到了 Lowe’s matching criterion for SIFT的启发。这种新的loss,要比负责的正则方法更好。把这个新的loss方法结合L2Net就得到了HardNet。它具有和SIFT同样的特征维度(128),并且在 wide baseline stereo, patch verification and instance retrieval benchmarks这样的任务上取得了最高水准的表现。
Introduction
Sampling and loss
过程如图1.首先一个batch中的匹配块生成 \(\mathcal{X}=\left(A_{i}, P_{i}\right)_{i=1 . . n}\),A代表anchor,P代表positive。那么每一对就是源于相同的一个3D point。
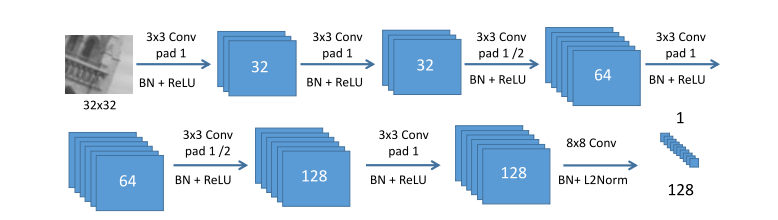
然后这2n个patches进入图2中的网络,使用得到的特征计算出一个图1中的距离矩阵。
\]
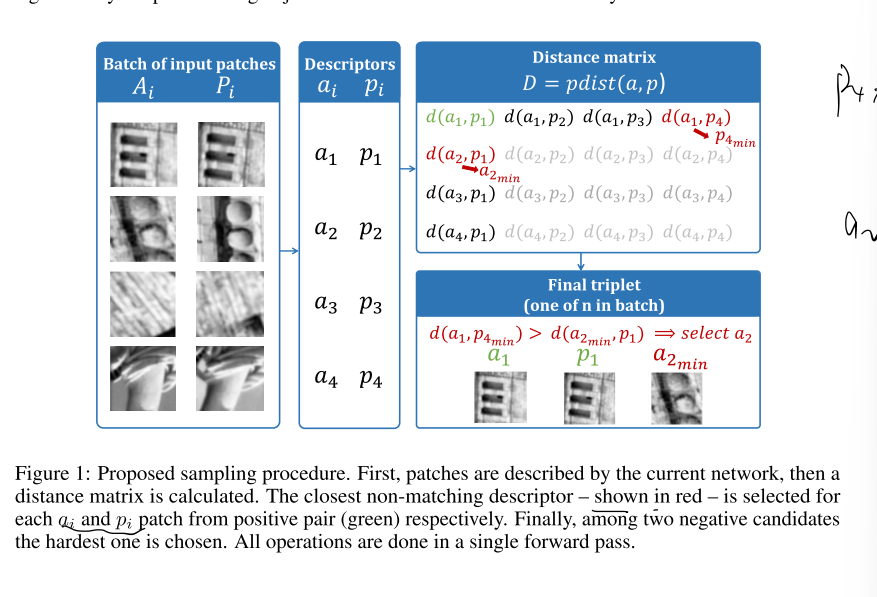
然后在这个矩阵里寻找与\(a_i,p_i\)最相近的那两个negative点(不属于同一个3D point)。假设\(a_i\)对应的是M,\(p_i\)对应的是N。倘若\(distance(a_i,M)<distance(p_i,N)\),这样的话,我们就得到了一个triplet的训练数据\((a_i,p_i,M)\),反之则是\((p_i,a_i,N)\)。
然后将这n个配对,送到loss函数里面:
\]
上述的M就是\(p_{j_{min}}\),N就是\(a_{k_{min}}\)
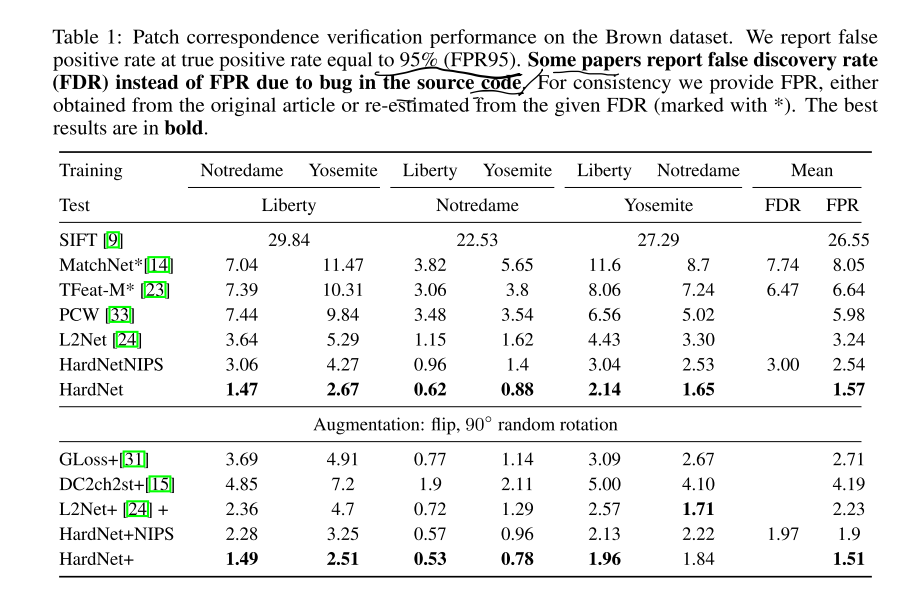
Results
batch size influence
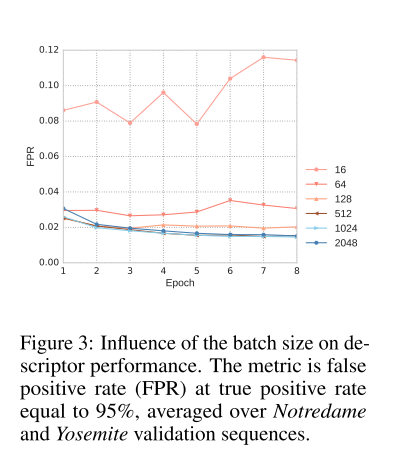
通过上文中的Sampling and loss小节可以看出,HardNet的表现与Bathsize应该有很大关系,
当Bathsize>512之后,模型性能就不会有明显提示了。
Empirical evaluation
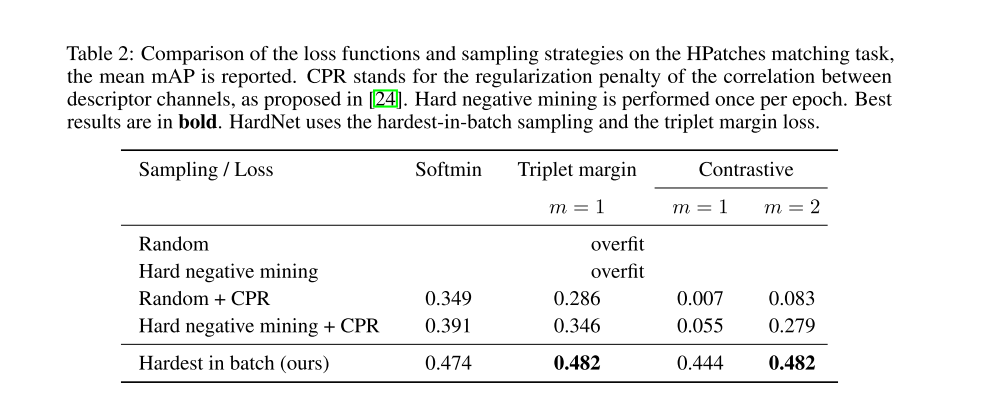
Ablation study
这一节作者使用不同的loss函数和不同的采样方法进行研究,得出hardest-in-batch的采样方法是使得模型表现好的主要原因。
Wide baseline stereo
为了检测模型的泛化能力以及对极端情况的应对能力,作者在W1BS这个数据集上进行测试,关于这个数据集的extreme change可参考下图:

结果:
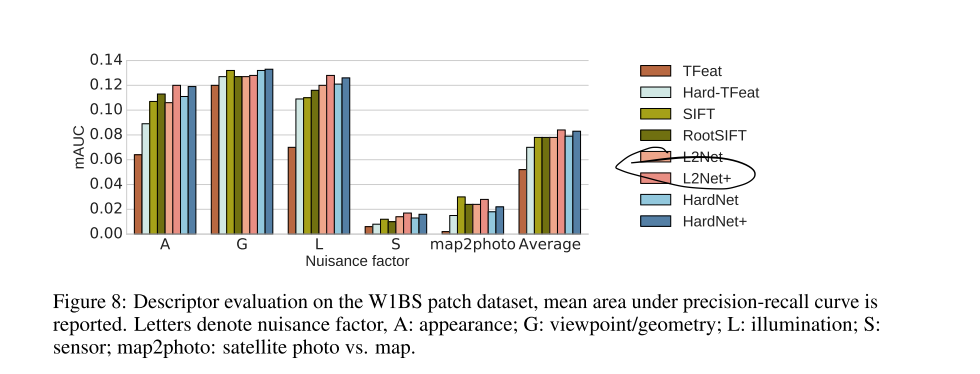
可以看到,HardNet和L2Net的表现相差不大。
Conclusion
- 作者提出了一种基于Batch的
Hard-neagtive mining和loss function,使得模型更加容易训练表现更好
Working hard to know your neighbor's margins:Local descriptor learning loss论文笔记的更多相关文章
- HardNet解读
论文:Working hard to know your neighbor’s margins: Local descriptor learning loss 为什么介绍此文:这篇2018cvpr文 ...
- Learning Spread-out Local Feature Descriptors
论文Learning Spread-out Local Feature Descriptors 为什么介绍此文:引入了一种正则化手段,结合其他网络的损失函数,尤其是最新cvpr 2018的hardne ...
- KNN(k-nearest neighbor的缩写)又叫最近邻算法
KNN(k-nearest neighbor的缩写)又叫最近邻算法 机器学习笔记--KNN算法1 前言 Hello ,everyone. 我是小花.大四毕业,留在学校有点事情,就在这里和大家吹吹我们的 ...
- cluster analysis in data mining
https://en.wikipedia.org/wiki/K-means_clustering k-means clustering is a method of vector quantizati ...
- 阅读MDN文档之基本盒模型(三)
Box properties Margin collapsing Adjacent siblings(相邻兄弟) Parent and first/last child Empty blocks Ac ...
- face recognition[翻译][深度人脸识别:综述]
这里翻译下<Deep face recognition: a survey v4>. 1 引言 由于它的非侵入性和自然特征,人脸识别已经成为身份识别中重要的生物认证技术,也已经应用到许多领 ...
- 学习笔记之k-nearest neighbors algorithm (k-NN)
k-nearest neighbors algorithm - Wikipedia https://en.wikipedia.org/wiki/K-nearest_neighbors_algorith ...
- LogisticRegression in MLLib
例子 iris数据训练Logistic模型.特征petal width和petal height,分类目标有三类. import org.apache.spark.mllib.classificati ...
- SVM的代码实现-python
隔了好久木有更新了,因为发现自己numpy的很多操作都忘记了,加上最近有点忙... 接着上次 我们得到的迭代函数为 首先j != yi j = yi import numpy as np def sv ...
随机推荐
- 【LeetCode】224. Basic Calculator 解题报告(Python)
作者: 负雪明烛 id: fuxuemingzhu 个人博客: http://fuxuemingzhu.cn/ 目录 题目描述 题目大意 解题方法 栈 参考资料 日期 题目地址:https://lee ...
- 使用.NET 6开发TodoList应用(16)——实现查询排序
系列导航及源代码 使用.NET 6开发TodoList应用文章索引 需求 关于查询的另一个需求是要根据前端请求的排序字段进行对结果相应的排序. 目标 实现根据排序要求返回排序后的结果 原理与思路 要实 ...
- linux 之 非root用户安装mysql5.7.27
下载 下载 mysql-5.7.27-linux-glibc2.12-x86_64.tar.gz 详见linux(CentOS7) 之 MySQL 5.7.30 下载及安装. 配置规划 用户: zhj ...
- java同时替换多个字符串
参考资料: https://blog.csdn.net/qq_39390545/article/details/106020221 来自为知笔记(Wiz)
- mysql 5.7.29 在centos7.6下超简单的本地yum源安装与配置
目录 生成yum源元数据 从网易镜像站下载MySQL 5.7 的 bundle包 创建文件 mysql-local.repo 执行yum install命令 生成yum源元数据 createrepo ...
- Git 如何放弃所有本地修改
git checkout . #本地所有的修改,没有提交的,都返回到原来的状态 git stash #把所有没有提交的修改暂存到stash里面.可用git stash pop恢复. git reset ...
- Git Book PDF下载
Download Git-Book
- 信息收集&Fuzz
本文译自https://0xjoyghosh.medium.com/information-gathering-scanning-for-sensitive-information-reloaded- ...
- 我的2021年度总结-回忆录|附旅行Vlog
今天是农历腊月初十,还有20天就是2022年了.这一年,些许遗憾,些许期盼.时间久了,很多事已经慢慢模糊了,只记得,这最后几个月的闲碎小事. 不止多久,很久没有码字了.有些事,记不清,忆不得.时至今年 ...
- 生产环境上,哨兵模式集群Redis版本升级应用实战
背景: 由于生产环境上所使用的Redis版本并不一致,好久也没有更新,为了避免版本不同对Redis集群造成影响,从而升级为统一Redis版本! 1.集群架构 一主两从三哨兵: 2.升级方案 (1)升级 ...