容器化部署Cassandra高可用集群
前提:
三台装有docker的虚拟机,这里用VM1,VM2,VM3表达(当然生产环境要用三个独立物理机,否则无高可用可言),装docker可参见Ubuntu离线安装docker。
开始部署:
部署图
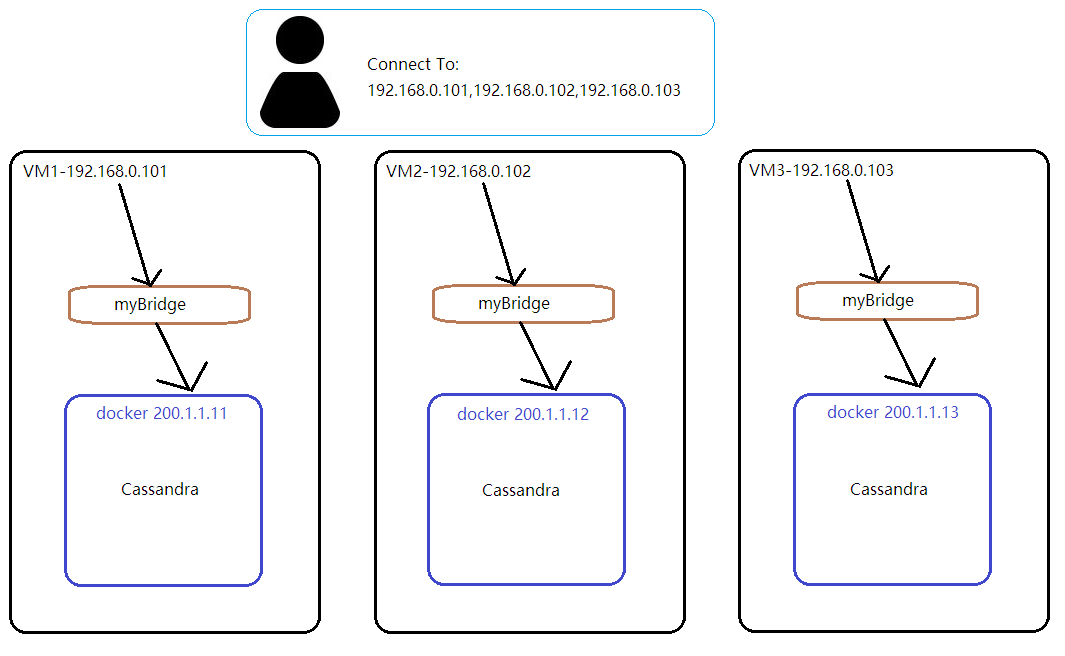
如上图所示,三台VM的IP分别为:
192.168.0.101
192.168.0.102
192.168.0.103
客户端将使用这三个IP来连接集群,每个VM通过端口映射由docker网桥myBridge来与Cassandra容器通信,容器的IP会在启动容器时指定
部署步骤:
1. 建docker网桥myBridge(名字随意)
在三台VM上,这里假定是ubuntu16.04.5,使用docker命令创建自定义docker网桥,用于VM和docker容器通讯
sudo docker network create --driver=bridge --subnet=200.1.1.0/24 myBridge
2. 准备cassandra的docker镜像,data目录,cassandra.yaml配置文件
首先创建好如下目录,假如VM的用户名是capcom923
/home/capcom923/cassandra/
2.1. docker镜像
由于我们要单独挂载cassandra.yaml配置文件,直接使用官方cassandra docker镜像会导致无法启动(因为镜像的启动文件docker-entrypoint.sh要修改cassandra.yaml文件,会造成device busy的错误),所以我注释掉了cassandra官网镜像中docker-entrypoint.sh文件的38行至53行,并重新生成了docker镜像,并导出为tar包供大家直接使用,请直接下载:(链接:https://pan.baidu.com/s/14n9_DGHCkAFRumln8muuQw 提取码:l1rx )
将tar包下载到该位置/home/capcom923/cassandra/cassandra-3.11.2-bps.tar
2.3. data目录
创建一个叫data的空目录即可
/home/capcom923/cassandra/data/
该目录用于cassandra存放所有持久化的数据
2.3. cassandra.yaml配置文件
该文件是cassandra的主要配置文件,由于三台VM的IP和角色各不尽相同,所以配置文件也不一样。
基于默认的cassandra.yaml文件,要对三台VM进行以下配置:
第一台VM:角色为种子节点,该节点在集群扩容缩容时,以及其它节点重启时是必须活着的,其它时候是可以宕机的。
| 配置节 | 值 | 说明 |
| cluster_name | 'MyCluster' | 集群的名字,同一个集群的名字要相同 |
| authenticator | PasswordAuthenticator | 生产环境都要用户名密码认证,默认的用户名/密码是cassandra/cassandra |
| seeds | 192.168.0.101 | 种子节点VM的IP,注意不是容器的IP。 |
| broadcast_address | 192.168.0.101 | 节点VM的IP,注意不是容器的IP。 |
| broadcast_rpc_address | 192.168.0.101 | 节点VM的IP,注意不是容器的IP。 |
| listen_address | 200.1.1.11 | 节点容器的IP。 |
| auto_snapshot | false | 尽管官方建议是true,但实际使用时,太消耗磁盘,所以建议改为false |
| endpoint_snitch | GossipingPropertyFileSnitch | 生产环境标配 |
编辑完毕后,存放在/home/capcom923/cassandra/cassandra.yaml
第二台VM:角色为普通节点
| 配置节 | 值 | 说明 |
| cluster_name | 'MyCluster' | 集群的名字,同一个集群的名字要相同 |
| authenticator | PasswordAuthenticator | 生产环境都要用户名密码认证,默认的用户名/密码是cassandra/cassandra |
| seeds | 192.168.0.101 | 种子节点VM的IP,注意不是容器的IP。 |
| broadcast_address | 192.168.0.102 | 节点VM的IP,注意不是容器的IP。 |
| broadcast_rpc_address | 192.168.0.102 | 节点VM的IP,注意不是容器的IP。 |
| listen_address | 200.1.1.12 | 节点容器的IP。 |
| auto_snapshot | false | 尽管官方建议是true,但实际使用时,太消耗磁盘,所以建议改为false |
| endpoint_snitch | GossipingPropertyFileSnitch | 生产环境标配 |
编辑完毕后,存放在/home/capcom923/cassandra/cassandra.yaml
第三台VM:角色为普通节点
| 配置节 | 值 | 说明 |
| cluster_name | 'MyCluster' | 集群的名字,同一个集群的名字要相同 |
| authenticator | PasswordAuthenticator | 生产环境都要用户名密码认证,默认的用户名/密码是cassandra/cassandra |
| seeds | 192.168.0.101 | 种子节点VM的IP,注意不是容器的IP。 |
| broadcast_address | 192.168.0.103 | 节点VM的IP,注意不是容器的IP。 |
| broadcast_rpc_address | 192.168.0.103 | 节点VM的IP,注意不是容器的IP。 |
| listen_address | 200.1.1.13 | 节点容器的IP。 |
| auto_snapshot | false | 尽管官方建议是true,但实际使用时,太消耗磁盘,所以建议改为false |
| endpoint_snitch | GossipingPropertyFileSnitch | 生产环境标配 |
编辑完毕后,存放在/home/capcom923/cassandra/cassandra.yaml
我也将这三个配置好的文件给大家参考,分别在1/2/3文件夹里(链接:https://pan.baidu.com/s/10i_iBdvMdfgFQHoWEUG6LQ 提取码:h7n4 )
至此,所以每台VM的目录结构为
/home/capcom923/cassandra/cassandra-3.11.2-bps.tar
/home/capcom923/cassandra/data/
/home/capcom923/cassandra/cassandra.yaml
3. 加载cassandra的docker镜像
在三台VM上执行
docker load -i /home/capcom923/cassandra/cassandra-3.11.2-bps.tar
4. 运行cassandra集群
在每一台VM上,先关闭ubuntu防火墙
sudo service ufw stop
sudo service firewalld stop(如果装了firewalld的话)
在第一台VM上:
sudo docker run --name cassandraNode1 -d -e CASSANDRA_DC=datacenter1 -v /home/capcom923/cassandra/cassandra.yaml:/etc/cassandra/cassandra.yaml -v /home/capcom923/cassandra/data:/var/lib/cassandra --restart unless-stopped --network myBridge --ip 200.1.1.11 -p 7000:7000 -p 9042:9042 cassandra:3.11.2.bps
在第二台VM上:
sudo docker run --name cassandraNode2 -d -e CASSANDRA_DC=datacenter1 -v /home/capcom923/cassandra/cassandra.yaml:/etc/cassandra/cassandra.yaml -v /home/capcom923/cassandra/data:/var/lib/cassandra --restart unless-stopped --network myBridge --ip 200.1.1.12 -p 7000:7000 -p 9042:9042 cassandra:3.11.2.bps
在第三台VM上:
sudo docker run --name cassandraNode3 -d -e CASSANDRA_DC=datacenter1 -v /home/capcom923/cassandra/cassandra.yaml:/etc/cassandra/cassandra.yaml -v /home/capcom923/cassandra/data:/var/lib/cassandra --restart unless-stopped --network myBridge --ip 200.1.1.13 -p 7000:7000 -p 9042:9042 cassandra:3.11.2.bps
5. 检查cassandra集群
在第一台VM上执行
sudo docker exec -it cassandraNode1 bash
进入容器之后,执行
nodetool status
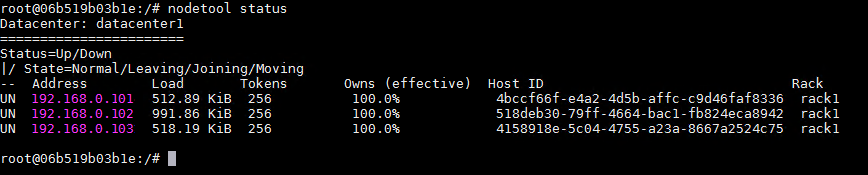
注意三个节点开头的信息,UN代表Up Normal状态,都是UN就证明集群工作正常了,开始有UJ,说明Up Joining,一会儿就会变UN
6. 修改system_auth的配置
在第五步的窗口中继续执行
cqlsh -u cassandra -p cassandra
连接进cassandra控制台
并输入ALTER KEYSPACE system_auth WITH replication = {'class': 'NetworkTopologyStrategy','datacenter1': '3'};
回车
将这个keyspace的策略和副本改成3,
然后输入exit退出cassandra控制台
再输入nodetool repair执行修复
然后在其余两台VM中的容器中都要执行nodetool repair,由此用户认证授权表得以及时同步,否则会引起从某一台节点无法登录的情况。
注意,cassandra/cassandra是系统默认用户,登录时要求至少过半的节点存活才可以。
至此,搭建完毕~
容器化部署Cassandra高可用集群的更多相关文章
- (六) Docker 部署 Redis 高可用集群 (sentinel 哨兵模式)
参考并感谢 官方文档 https://hub.docker.com/_/redis GitHub https://github.com/antirez/redis happyJared https:/ ...
- 部署MYSQL高可用集群
mysql-day08 部署MYSQL高可用集群 u 集群架构 ...
- 部署zookeepe高可用集群
部署zookeepe高可用集群 部署规划 Nno1 192.16 ...
- 一键部署Kubernetes高可用集群
三台master,四台node,系统版本为CentOS7 IP ROLE 172.60.0.226 master01 172.60.0.86 master02 172.60.0.106 master0 ...
- Hadoop部署方式-高可用集群部署(High Availability)
版权声明:原创作品,谢绝转载!否则将追究法律责任. 本篇博客的高可用集群是建立在完全分布式基础之上的,详情请参考:https://www.cnblogs.com/yinzhengjie/p/90651 ...
- 基于 Rainbond 部署 DolphinScheduler 高可用集群
本文描述通过 Rainbond 云原生应用管理平台 一键部署高可用的 DolphinScheduler 集群,这种方式适合给不太了解 Kubernetes.容器化等复杂技术的用户使用,降低了在 Kub ...
- 部署 kube-controller-manager 高可用集群
目录 前言 创建kube-controller-manager证书和私钥 生成证书和私钥 将生成的证书和私钥分发到所有master节点 创建和分发kubeconfig文件 分发kubeconfig到所 ...
- k8s集群中部署Rook-Ceph高可用集群
先决条件 为确保您有一个准备就绪的 Kubernetes 集群Rook,您可以按照这些说明进行操作. 为了配置 Ceph 存储集群,至少需要以下本地存储选项之一: 原始设备(无分区或格式化文件系统) ...
- 一文吃透如何部署kubernetes高可用集群
使用 k8s 官方提供的部署工具 kubeadm 自动安装,需要在 master 和 node 节点上安装 docker 等组件,然后初始化,把管理端的控制服务和 node 上的服务都以 pod 的方 ...
随机推荐
- VB中获取网页数据
以下是在Microsoft Visual Basic 6.0 中文版下做的 VB可以抓取网页数据,所用的控件是Inet控件. 第一步:单击工程-->部件 选择Microsoft Internet ...
- js作用域和内存
对于一本编程语言来讲,个人认为,最基本的就是存储,在存储,读取,计算值的时候是按照一定的规则来操作,这套规则呢就叫做作用域. 值保存,读取,的时候需要一个范围,如果以按照函数为单位的话就做函数作用域, ...
- 小妖精的完美游戏教室——人工智能,A*算法,启发因子篇
//================================================================//// Copyright (C) 2017 Team Saluk ...
- windows7 64位系统安装CPU版本TensorFlow(anaconda3.6)
1>下载anaconda3.6,https://www.anaconda.com/download/,选择64位的anaconda3.6,安装时候,路径可以自定义,但是要选择把路径添加到环境变量 ...
- Evosuite使用方法入门
Evosuite使用方法入门 1.简要介绍 EvoSuite开源工具可以基于Eclipse进行测试用例的自动生成,生成的测试用例符合Junit标准(直接生成可进行Junit的java文件),满 ...
- C++ 状态机接口
最近的状态极差,甚至代码也写不下去了.给自己手臂上的两刀没有任何的作用,看来早已经是麻痹了. 一直想弄一个勉强能用的状态机,用于在各种涉及到状态转换的时候用到,然而脑子并不是太清醒. 先放在这里一个接 ...
- zabbix使用客户端和不使用客户端监控指定端口
监控指定端口也很简单,以监控181主机的22端口为例 点击已成功监控的181主机的监控项 点击创建监控项 使用客户端监控端口:选择键值net.tcp.listen[port],需要自己把port改成2 ...
- mysql 生成时间序列数据 - 存储过程
由于时间自动转换为int值, 做一步转化,也可在调用时处理 use `test`; CREATE table test.test1 as SELECT state, id, `规格条码`, `色号条码 ...
- 【代码问题】MatConvNet自带example中 fast_rcnn_evaluate出错
fast_rcnn_evaluate中调用cnn_setup_data_voc07函数读取相关数据时,在类似 [gtids,t]=textread(sprintf(VOCopts.imgsetpath ...
- Spark配置参数详解
以下是整理的Spark中的一些配置参数,官方文档请参考Spark Configuration. Spark提供三个位置用来配置系统: Spark属性:控制大部分的应用程序参数,可以用SparkConf ...