基于 Rainbond 部署 DolphinScheduler 高可用集群
本文描述通过 Rainbond 云原生应用管理平台 一键部署高可用的 DolphinScheduler 集群,这种方式适合给不太了解 Kubernetes、容器化等复杂技术的用户使用,降低了在 Kubernetes 中部署 DolphinScheduler 的门槛。
Apache DolphinScheduler 是一个分布式易扩展的可视化 DAG 工作流任务调度开源系统。解决数据研发ETL 错综复杂的依赖关系,不能直观监控任务健康状态等问题。DolphinScheduler 以 DAG 流式的方式将 Task 组装起来,可实时监控任务的运行状态,同时支持重试、从指定节点恢复失败、暂停及Kill任务等操作
简单易用:DAG 监控界面,所有流程定义都是可视化,通过拖拽任务定制 DAG,通过 API 方式与第三方系统对接, 一键部署
高可靠性:去中心化的多 Master 和多 Worker, 自身支持 HA 功能, 采用任务队列来避免过载,不会造成机器卡死
丰富的使用场景:支持暂停恢复操作.支持多租户,更好的应对大数据的使用场景. 支持更多的任务类型,如 spark, hive, mr, python, sub_process, shell
高扩展性:支持自定义任务类型,调度器使用分布式调度,调度能力随集群线性增长,Master 和 Worker 支持动态上下线
前提条件
- 可用的 Rainbond 云原生应用管理平台,请参阅文档 Rainbond 快速安装
DolphinScheduler 集群一键部署
- 对接并访问内置的开源应用商店,搜索关键词
dolp即可找到 DolphinScheduler 应用。
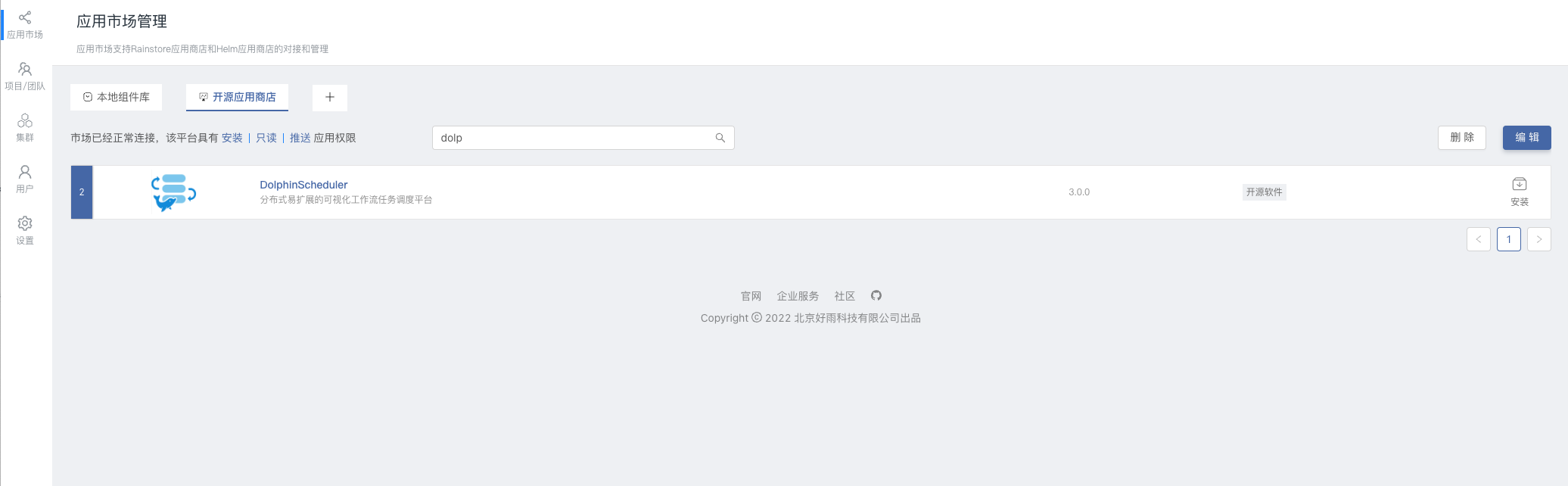
- 点击 DolphinScheduler 右侧的
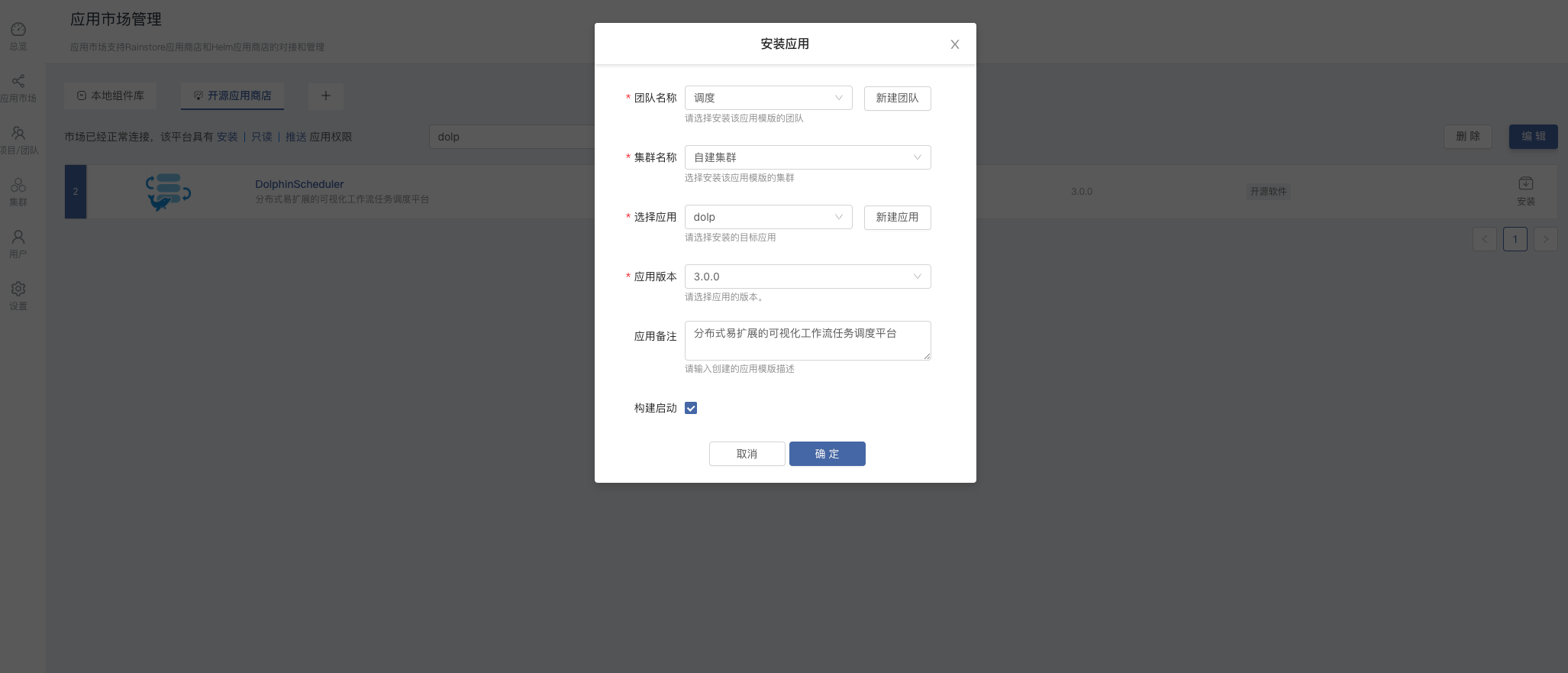
安装进入安装页面,填写对应的信息,点击确定即可开始安装,自动跳转至应用视图。
| 选择项 | 说明 |
|---|---|
| 团队名称 | 用户自建的工作空间,以命名空间隔离 |
| 集群名称 | 选择 DolphinScheduler 被部署到哪一个 K8s 集群 |
| 选择应用 | 选择 DolphinScheduler 被部署到哪一个应用,应用中包含有若干有关联的组件 |
| 应用版本 | 选择 DolphinScheduler 的版本,目前可选版本为 3.0.0-beta2 |
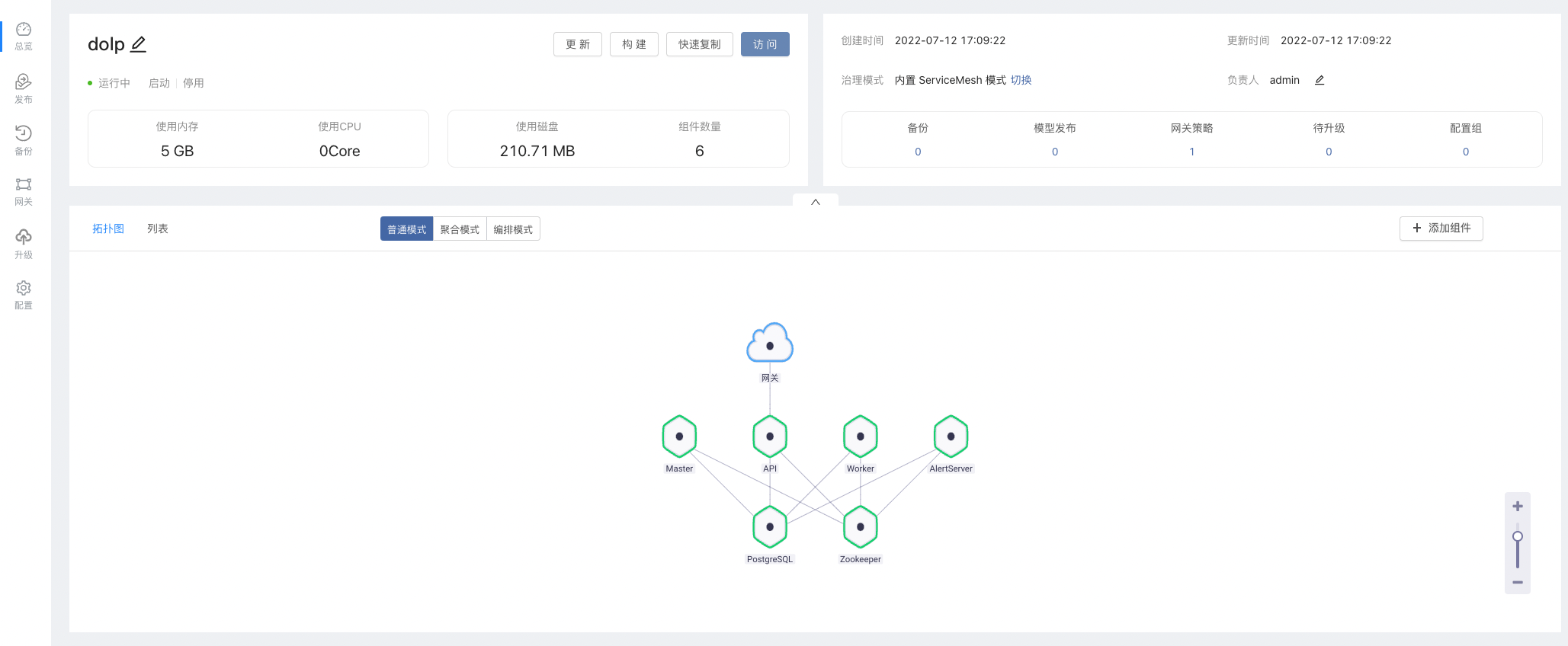
- 等待几分钟后,DolphinScheduler 集群就会安装完成,并运行起来。
- 点击访问,将访问 DolphinScheduler-API 组件,默认的用户密码是
admin/dolphinscheduler123
API Master Worker 节点伸缩
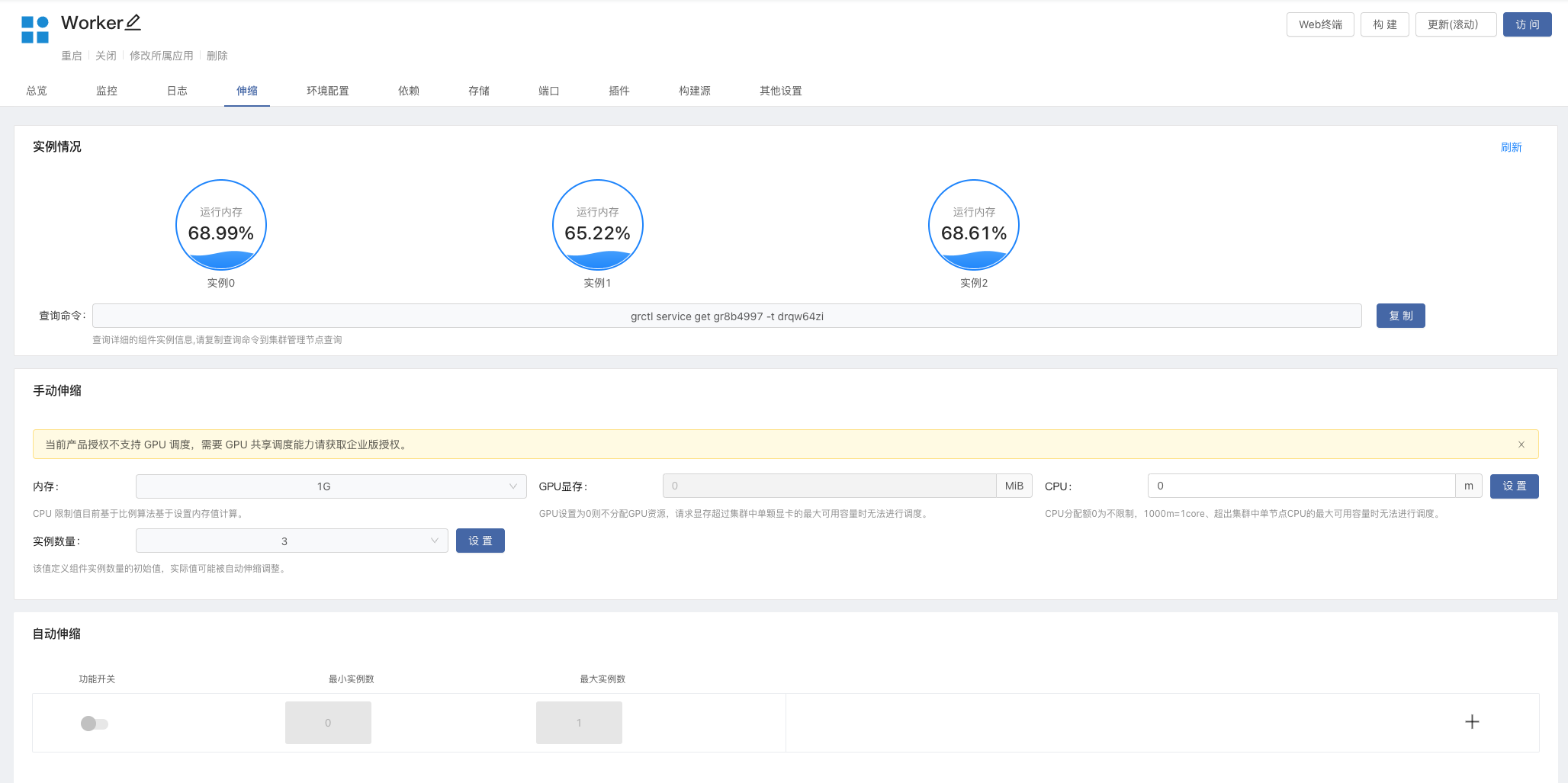
DolphinScheduler API、Master、Worker 都支持伸缩多个实例,多个实例可以保证整个集群的高可用性。
以 Worker 为例,进入组件内 -> 伸缩,设置实例数量。
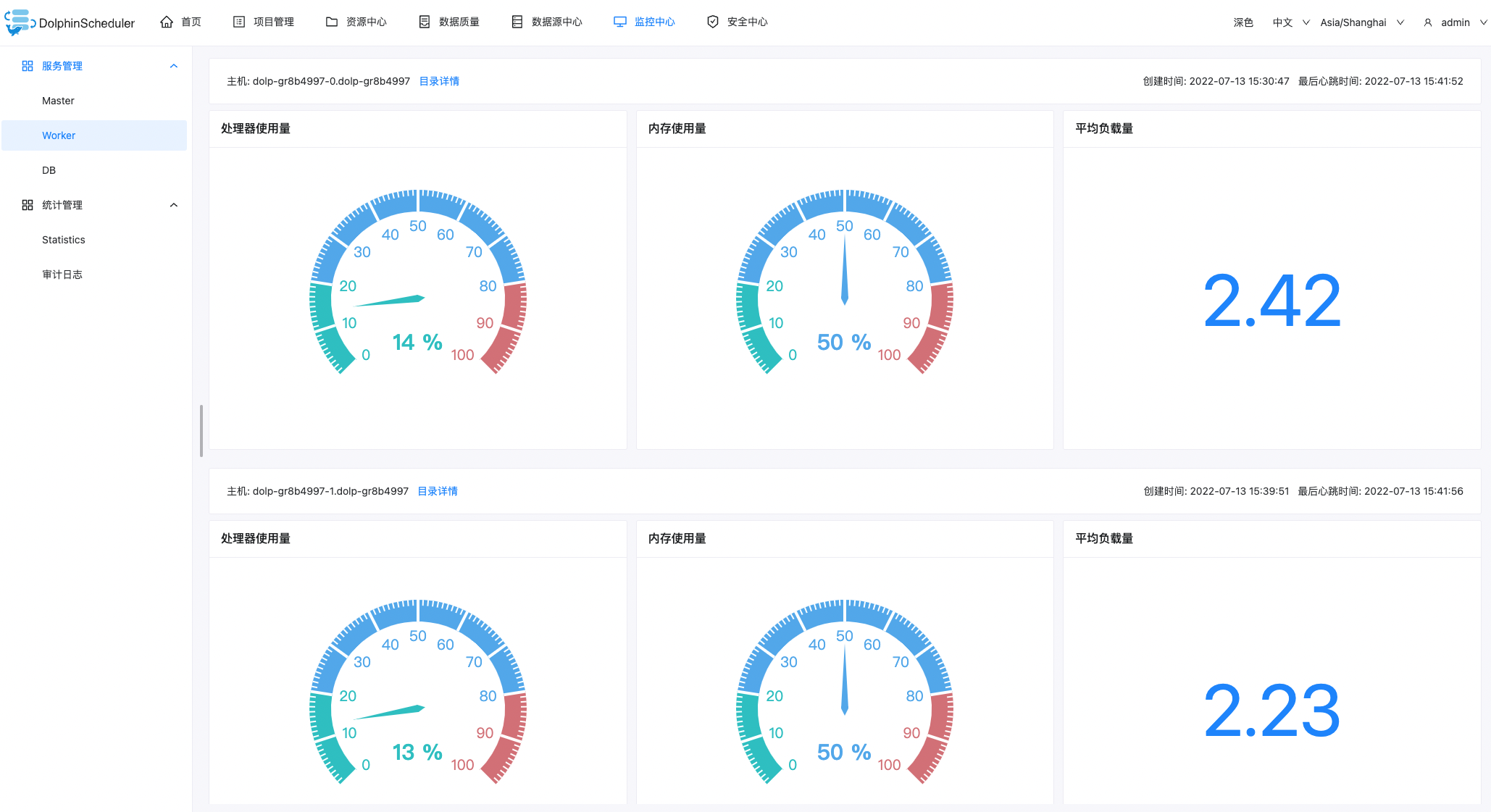
验证 Worker 节点,进入 DolphinScheduler UI -> 监控中心 -> Worker 查看节点信息。
配置文件
API 和 Worker 服务共用 /opt/dolphinscheduler/conf/common.properties ,修改配置时只需修改 API 服务的配置文件。
如何支持 Python 3?
Worker 服务默认安装了 Python3,使用时可以添加环境变量 PYTHON_HOME=/usr/bin/python3
如何支持 Hadoop, Spark, DataX 等?
以 Datax 为例:
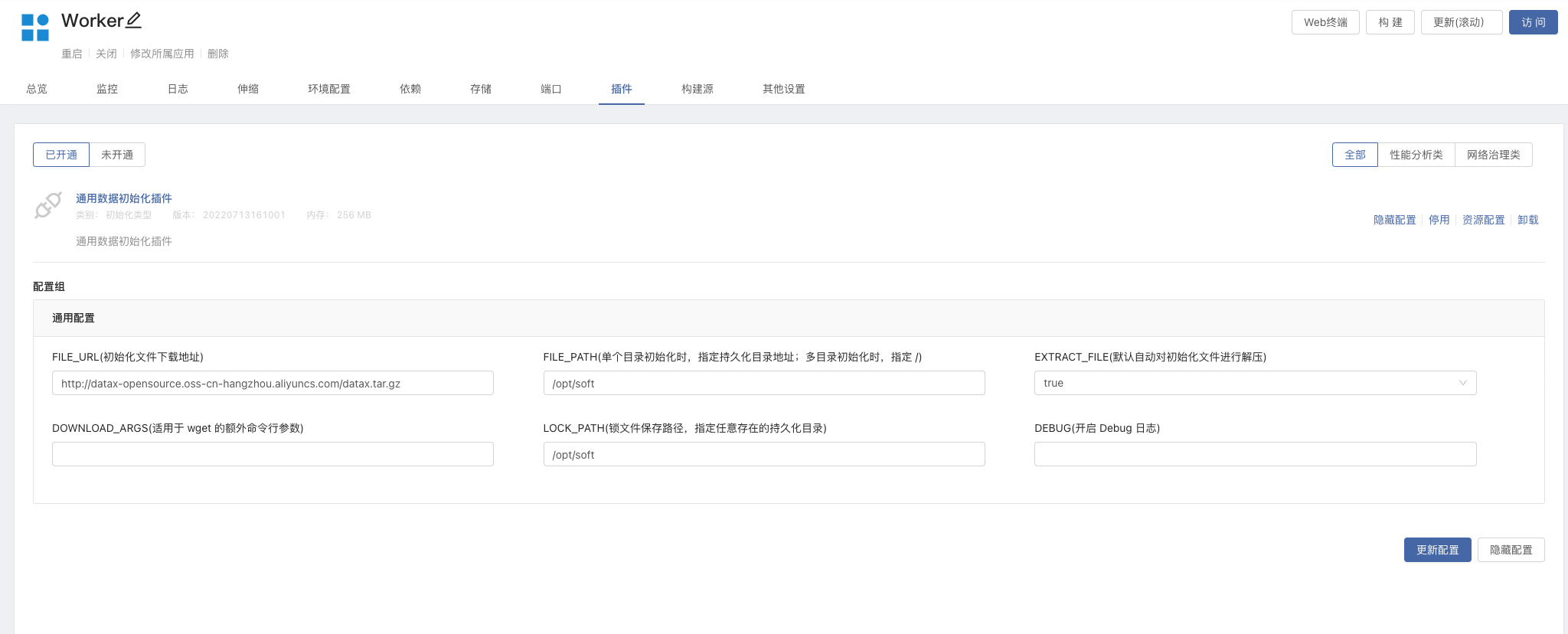
- 安装插件。Rainbond 团队视图 -> 插件 -> 从应用商店安装插件 -> 搜索
通用数据初始化插件并安装。 - 开通插件。进入 Worker 组件内 -> 插件 -> 开通
通用数据初始化插件,并修改配置- FILE_URL:http://datax-opensource.oss-cn-hangzhou.aliyuncs.com/datax.tar.gz
- FILE_PATH:/opt/soft
- LOCK_PATH:/opt/soft
- 更新组件,初始化插件会自动下载
Datax并解压到/opt/soft目录下。
基于 Rainbond 部署 DolphinScheduler 高可用集群的更多相关文章
- 基于docker实现redis高可用集群
基于docker实现redis高可用集群 yls 2019-9-20 简介 基于docker和docker-compose 使用redis集群和sentinel集群,达到redis高可用,为缓存做铺垫 ...
- (六) Docker 部署 Redis 高可用集群 (sentinel 哨兵模式)
参考并感谢 官方文档 https://hub.docker.com/_/redis GitHub https://github.com/antirez/redis happyJared https:/ ...
- 部署MYSQL高可用集群
mysql-day08 部署MYSQL高可用集群 u 集群架构 ...
- 部署zookeepe高可用集群
部署zookeepe高可用集群 部署规划 Nno1 192.16 ...
- 一键部署Kubernetes高可用集群
三台master,四台node,系统版本为CentOS7 IP ROLE 172.60.0.226 master01 172.60.0.86 master02 172.60.0.106 master0 ...
- Hadoop部署方式-高可用集群部署(High Availability)
版权声明:原创作品,谢绝转载!否则将追究法律责任. 本篇博客的高可用集群是建立在完全分布式基础之上的,详情请参考:https://www.cnblogs.com/yinzhengjie/p/90651 ...
- heatbeat-gui实现基于nfs的mysql高可用集群
一.简述HA高可用集群 高可用集群就是当集群中的一个节点发生各种软硬件及人为故障时,集群中的其他节点能够自动接管故障节点的资源并向外提供服务.以实现减少业务中断时间,为用户提供更可靠,更高效的服务. ...
- 容器化部署Cassandra高可用集群
前提: 三台装有docker的虚拟机,这里用VM1,VM2,VM3表达(当然生产环境要用三个独立物理机,否则无高可用可言),装docker可参见Ubuntu离线安装docker. 开始部署: 部署图 ...
- 基于keepalived搭建MySQL高可用集群
MySQL的高可用方案一般有如下几种: keepalived+双主,MHA,MMM,Heartbeat+DRBD,PXC,Galera Cluster 比较常用的是keepalived+双主,MHA和 ...
随机推荐
- javaScript深拷贝和浅拷贝简单梳理
在了解深拷贝和浅拷贝之前,我们先梳理一下: JavaScript中,分为基本数据类型(原始值)和复杂类型(对象),同时它们各自的数据类型细分下又有好几种数据类型 基本数据类型 数字Number 字符串 ...
- 【深度学习 论文篇 03-2】Pytorch搭建SSD模型踩坑集锦
论文地址:https://arxiv.org/abs/1512.02325 源码地址:http://github.com/amdegroot/ssd.pytorch 环境1:torch1.9.0+CP ...
- 审计 Linux 系统的操作行为的 5 种方案对比
点击上方"开源Linux",选择"设为星标" 回复"学习"获取独家整理的学习资料! 很多时候我们为了安全审计或者故障跟踪排错,可能会记录分析 ...
- Solon 1.7.6 发布,更现代感的应用开发框架
相对于 Spring Boot 和 Spring Cloud 的项目 启动快 5 - 10 倍 qps 高 2- 3 倍 运行时内存节省 1/3 ~ 1/2 打包可以缩小到 1/2 ~ 1/10(比如 ...
- 小米 pro 笔记本双硬盘设置引导盘
功能键 F2 进入 BIOS F12 进入 Boot 选项 步骤 小米 Pro 默认是开启了 UEFI,如果 Boot 选项没有显示出期望的系统盘,那么就是这个系统盘没有 UEFI 分区,按照这个文档 ...
- 【动态UAC权限】无盾程序(win32&cmd)
可以看到两种不同的提权方式,注意是动态,用代码提权,而不是用清单文件提前处理. 函数都写好了,这里不多做解释. win32程序: 首先需要这俩头文件,第二个我忘了啥函数要用了,总之出问题加上就对了:( ...
- 印尼医疗龙头企业Halodoc的数据平台转型之Lakehouse架构
1. 摘要 在 Halodoc,我们始终致力于为最终用户简化医疗保健服务,随着公司的发展,我们不断构建和提供新功能. 我们两年前建立的可能无法支持我们今天管理的数据量,以解决我们决定改进数据平台架构的 ...
- python初识数据类型(字典、集合、元组、布尔)与运算符
目录 python数据类型(dict.tuple.set.bool) 字典 集合 元组 布尔值 用户交互与输出 获取用户输入 输出信息 格式化输出 基本运算符 算术运算符 比较运算符 逻辑运算符 赋值 ...
- Python常用标准库(pickle序列化和JSON序列化)
常用的标准库 序列化模块 import pickle 序列化和反序列化 把不能直接存储的数据变得可存储,这个过程叫做序列化.把文件中的数据拿出来,回复称原来的数据类型,这个过程叫做反序列化. 在文件中 ...
- 场景实践:基于 IntelliJ IDEA 插件部署微服务应用
体验简介 阿里云云起实验室提供相关实验资源,点击前往 本场景指导您把微服务应用部署到 SAE 平台: 登陆 SAE 控制台,基于 jar 包创建应用 基于 IntelliJ IDEA 插件更新 SAE ...