第三百六十七节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)scrapy写入数据到elasticsearch中
第三百六十七节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)scrapy写入数据到elasticsearch中
前面我们讲到的elasticsearch(搜索引擎)操作,如:增、删、改、查等操作都是用的elasticsearch的语言命令,就像sql命令一样,当然elasticsearch官方也提供了一个python操作elasticsearch(搜索引擎)的接口包,就像sqlalchemy操作数据库一样的ORM框,这样我们操作elasticsearch就不用写命令了,用elasticsearch-dsl-py这个模块来操作,也就是用python的方式操作一个类即可
elasticsearch-dsl-py下载
下载地址:https://github.com/elastic/elasticsearch-dsl-py
文档说明:http://elasticsearch-dsl.readthedocs.io/en/latest/
首先安装好elasticsearch-dsl-py模块
1、elasticsearch-dsl模块使用说明
create_connection(hosts=['127.0.0.1']):连接elasticsearch(搜索引擎)服务器方法,可以连接多台服务器
class Meta:设置索引名称和表名称
索引类名称.init(): 生成索引和表以及字段
实例化索引类.save():将数据写入elasticsearch(搜索引擎)
elasticsearch_orm.py 操作elasticsearch(搜索引擎)文件
#!/usr/bin/env python
# -*- coding:utf8 -*-
from datetime import datetime
from elasticsearch_dsl import DocType, Date, Nested, Boolean, \
analyzer, InnerObjectWrapper, Completion, Keyword, Text, Integer # 更多字段类型见第三百六十四节elasticsearch(搜索引擎)的mapping映射管理 from elasticsearch_dsl.connections import connections # 导入连接elasticsearch(搜索引擎)服务器方法
connections.create_connection(hosts=['127.0.0.1']) class lagouType(DocType): # 自定义一个类来继承DocType类
# Text类型需要分词,所以需要知道中文分词器,ik_max_wordwei为中文分词器
title = Text(analyzer="ik_max_word") # 设置,字段名称=字段类型,Text为字符串类型并且可以分词建立倒排索引
description = Text(analyzer="ik_max_word")
keywords = Text(analyzer="ik_max_word")
url = Keyword() # 设置,字段名称=字段类型,Keyword为普通字符串类型,不分词
riqi = Date() # 设置,字段名称=字段类型,Date日期类型 class Meta: # Meta是固定写法
index = "lagou" # 设置索引名称(相当于数据库名称)
doc_type = 'biao' # 设置表名称 if __name__ == "__main__": # 判断在本代码文件执行才执行里面的方法,其他页面调用的则不执行里面的方法
lagouType.init() # 生成elasticsearch(搜索引擎)的索引,表,字段等信息 # 使用方法说明:
# 在要要操作elasticsearch(搜索引擎)的页面,导入此模块
# lagou = lagouType() #实例化类
# lagou.title = '值' #要写入字段=值
# lagou.description = '值'
# lagou.keywords = '值'
# lagou.url = '值'
# lagou.riqi = '值'
# lagou.save() #将数据写入elasticsearch(搜索引擎)
2、scrapy写入数据到elasticsearch中
爬虫文件
# -*- coding: utf-8 -*-
import scrapy
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import CrawlSpider, Rule
from adc.items import LagouItem,LagouItemLoader #导入items容器类,和ItemLoader类
import time class LagouSpider(CrawlSpider): #创建爬虫类
name = 'lagou' #爬虫名称
allowed_domains = ['www.luyin.org'] #起始域名
start_urls = ['http://www.luyin.org/'] #起始url custom_settings = {
"AUTOTHROTTLE_ENABLED": True, #覆盖掉settings.py里的相同设置,开启COOKIES
"DOWNLOAD_DELAY":5
} rules = (
#配置抓取列表页规则
Rule(LinkExtractor(allow=('ggwa/.*')), follow=True), #配置抓取内容页规则
Rule(LinkExtractor(allow=('post/\d+.html.*')), callback='parse_job', follow=True),
) def parse_job(self, response): #回调函数,注意:因为CrawlS模板的源码创建了parse回调函数,所以切记我们不能创建parse名称的函数
atime = time.localtime(time.time()) #获取系统当前时间
dqatime = "{0}-{1}-{2} {3}:{4}:{5}".format(
atime.tm_year,
atime.tm_mon,
atime.tm_mday,
atime.tm_hour,
atime.tm_min,
atime.tm_sec
) # 将格式化时间日期,单独取出来拼接成一个完整日期 url = response.url item_loader = LagouItemLoader(LagouItem(), response=response) # 将数据填充进items.py文件的LagouItem
item_loader.add_xpath('title', '/html/head/title/text()')
item_loader.add_xpath('description', '/html/head/meta[@name="Description"]/@content')
item_loader.add_xpath('keywords', '/html/head/meta[@name="keywords"]/@content')
item_loader.add_value('url', url)
item_loader.add_value('riqi', dqatime)
article_item = item_loader.load_item()
yield article_item
items.py文件
# -*- coding: utf-8 -*- # Define here the models for your scraped items
#
# See documentation in:
# http://doc.scrapy.org/en/latest/topics/items.html
#items.py,文件是专门用于,接收爬虫获取到的数据信息的,就相当于是容器文件 import scrapy
from scrapy.loader.processors import MapCompose,TakeFirst
from scrapy.loader import ItemLoader #导入ItemLoader类也就加载items容器类填充数据
from adc.models.elasticsearch_orm import lagouType #导入elasticsearch操作模块 class LagouItemLoader(ItemLoader): #自定义Loader继承ItemLoader类,在爬虫页面调用这个类填充数据到Item类
default_output_processor = TakeFirst() #默认利用ItemLoader类,加载items容器类填充数据,是列表类型,可以通过TakeFirst()方法,获取到列表里的内容 def tianjia(value): #自定义数据预处理函数
return value #将处理后的数据返给Item class LagouItem(scrapy.Item): #设置爬虫获取到的信息容器类
title = scrapy.Field( #接收爬虫获取到的title信息
input_processor=MapCompose(tianjia), #将数据预处理函数名称传入MapCompose方法里处理,数据预处理函数的形式参数value会自动接收字段title
)
description = scrapy.Field()
keywords = scrapy.Field()
url = scrapy.Field()
riqi = scrapy.Field() def save_to_es(self):
lagou = lagouType() # 实例化elasticsearch(搜索引擎对象)
lagou.title = self['title'] # 字段名称=值
lagou.description = self['description']
lagou.keywords = self['keywords']
lagou.url = self['url']
lagou.riqi = self['riqi']
lagou.save() # 将数据写入elasticsearch(搜索引擎对象)
return
pipelines.py文件
# -*- coding: utf-8 -*- # Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: http://doc.scrapy.org/en/latest/topics/item-pipeline.html
from adc.models.elasticsearch_orm import lagouType #导入elasticsearch操作模块 class AdcPipeline(object):
def process_item(self, item, spider): #也可以在这里将数据写入elasticsearch搜索引擎,这里的缺点是统一处理
# lagou = lagouType()
# lagou.title = item['title']
# lagou.description = item['description']
# lagou.keywords = item['keywords']
# lagou.url = item['url']
# lagou.riqi = item['riqi']
# lagou.save()
item.save_to_es() #执行items.py文件的save_to_es方法将数据写入elasticsearch搜索引擎
return item
settings.py文件,注册pipelines
# Configure item pipelines
# See http://scrapy.readthedocs.org/en/latest/topics/item-pipeline.html
ITEM_PIPELINES = {
'adc.pipelines.AdcPipeline': 300,
}
main.py爬虫启动文件
#!/usr/bin/env python
# -*- coding:utf8 -*- from scrapy.cmdline import execute #导入执行scrapy命令方法
import sys
import os sys.path.append(os.path.join(os.getcwd())) #给Python解释器,添加模块新路径 ,将main.py文件所在目录添加到Python解释器 execute(['scrapy', 'crawl', 'lagou', '--nolog']) #执行scrapy命令 # execute(['scrapy', 'crawl', 'lagou']) #执行scrapy命令
运行爬虫
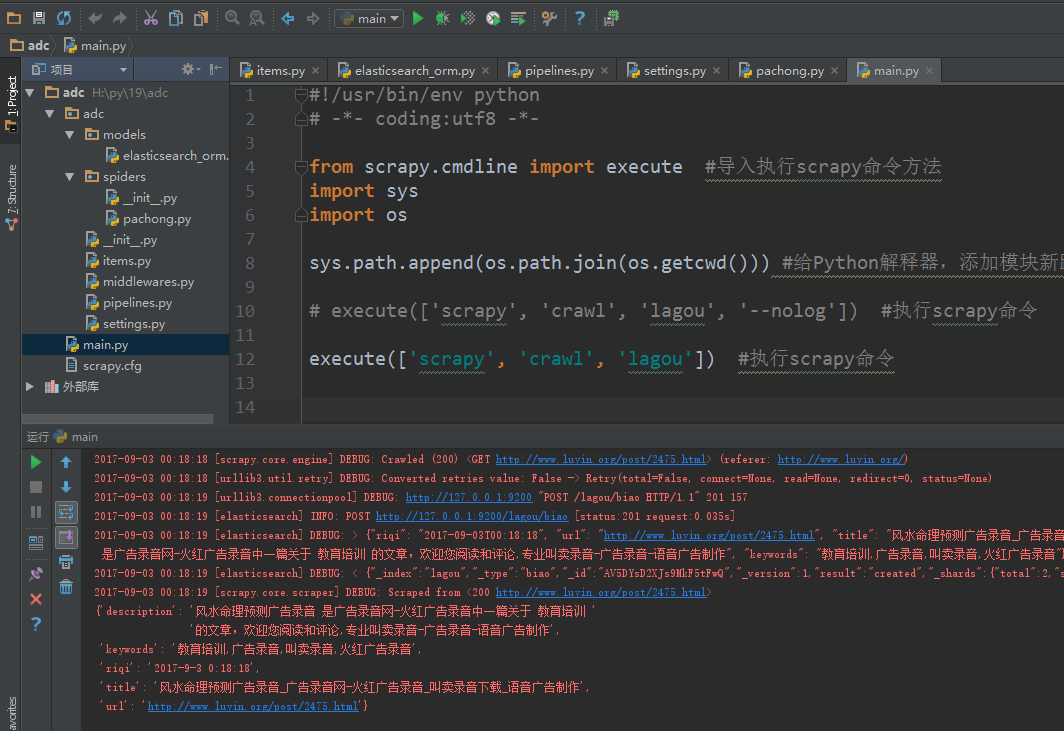
写入elasticsearch(搜索引擎)情况
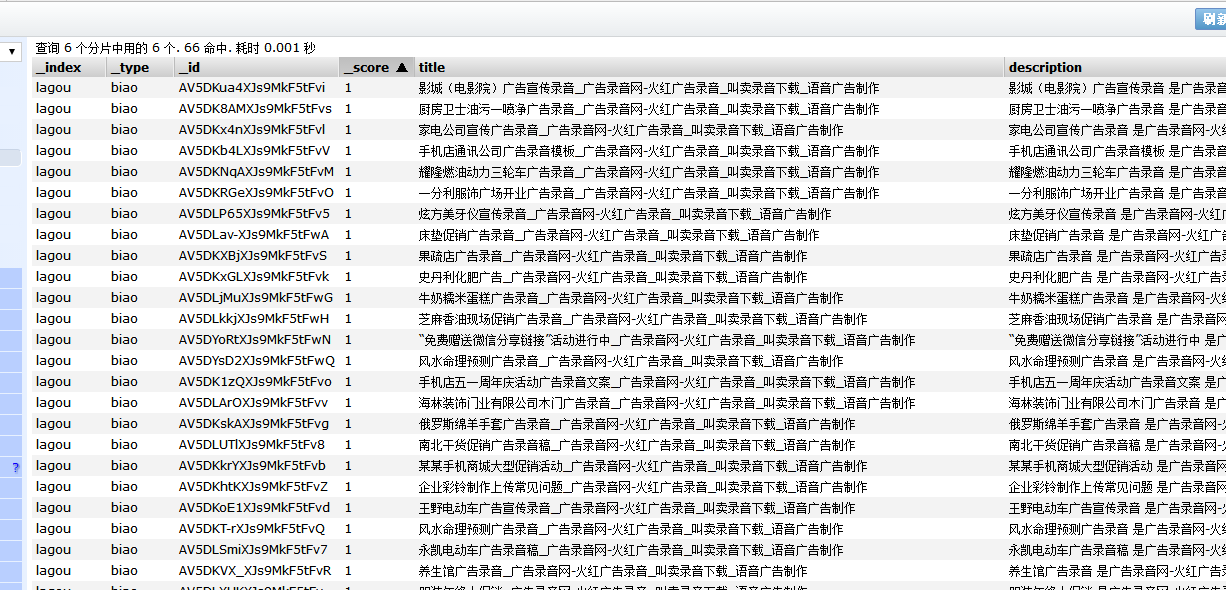
补充:elasticsearch-dsl 的 增删改查
#!/usr/bin/env python
# -*- coding:utf8 -*-
from datetime import datetime
from elasticsearch_dsl import DocType, Date, Nested, Boolean, \
analyzer, InnerObjectWrapper, Completion, Keyword, Text, Integer # 更多字段类型见第三百六十四节elasticsearch(搜索引擎)的mapping映射管理 from elasticsearch_dsl.connections import connections # 导入连接elasticsearch(搜索引擎)服务器方法
connections.create_connection(hosts=['127.0.0.1']) class lagouType(DocType): # 自定义一个类来继承DocType类
# Text类型需要分词,所以需要知道中文分词器,ik_max_wordwei为中文分词器
title = Text(analyzer="ik_max_word") # 设置,字段名称=字段类型,Text为字符串类型并且可以分词建立倒排索引
description = Text(analyzer="ik_max_word")
keywords = Text(analyzer="ik_max_word")
url = Keyword() # 设置,字段名称=字段类型,Keyword为普通字符串类型,不分词
riqi = Date() # 设置,字段名称=字段类型,Date日期类型 class Meta: # Meta是固定写法
index = "lagou" # 设置索引名称(相当于数据库名称)
doc_type = 'biao' # 设置表名称 if __name__ == "__main__": # 判断在本代码文件执行才执行里面的方法,其他页面调用的则不执行里面的方法
lagouType.init() # 生成elasticsearch(搜索引擎)的索引,表,字段等信息 # 使用方法说明:
# 在要要操作elasticsearch(搜索引擎)的页面,导入此模块
# lagou = lagouType() #实例化类
# lagou.title = '值' #要写入字段=值
# lagou.description = '值'
# lagou.keywords = '值'
# lagou.url = '值'
# lagou.riqi = '值'
# lagou.save() #将数据写入elasticsearch(搜索引擎)
1新增数据
from adc.models.elasticsearch_orm import lagouType #导入刚才配置的elasticsearch操作模块 lagou = lagouType() # 实例化elasticsearch(搜索引擎对象)
lagou._id = 1 #自定义ID,很重要,以后都是根据ID来操作
lagou.title = self['title'] # 字段名称=值
lagou.description = self['description']
lagou.keywords = self['keywords']
lagou.url = self['url']
lagou.riqi = self['riqi']
lagou.save() # 将数据写入elasticsearch(搜索引擎对象)
2删除指定数据
from adc.models.elasticsearch_orm import lagouType #导入刚才配置的elasticsearch操作模块
sousuo_orm = lagouType() # 实例化
sousuo_orm.get(id=1).delete() # 删除id等于1的数据
3修改指定的数据
from adc.models.elasticsearch_orm import lagouType #导入刚才配置的elasticsearch操作模块 sousuo_orm = lagouType() # 实例化
sousuo_orm.get(id=1).update(title='') # 修改id等于1的数据
以上全部使用elasticsearch-dsl模块
注意下面使用的原生elasticsearch模块
删除指定使用,就是相当于删除指定数据库
使用原生elasticsearch模块删除指定索引
from elasticsearch import Elasticsearch # 导入原生的elasticsearch(搜索引擎)接口
client = Elasticsearch(hosts=settings.Elasticsearch_hosts) # 连接原生的elasticsearch # 使用原生elasticsearch模块删除指定索引
#要做容错处理,如果索引不存在会报错
try:
client.indices.delete(index='jxiou_zuopin')
except Exception as e:
pass
原生查询
from elasticsearch import Elasticsearch # 导入原生的elasticsearch(搜索引擎)接口
client = Elasticsearch(hosts=Elasticsearch_hosts) # 连接原生的elasticsearch response = client.search( # 原生的elasticsearch接口的search()方法,就是搜索,可以支持原生elasticsearch语句查询
index="jxiou_zuopin", # 设置索引名称
doc_type="zuopin", # 设置表名称
body={ # 书写elasticsearch语句
"query": {
"multi_match": { # multi_match查询
"query": sousuoci, # 查询关键词
"fields": ["title"] # 查询字段
}
},
"from": (page - 1) * tiaoshu, # 从第几条开始获取
"size": tiaoshu, # 获取多少条数据
"highlight": { # 查询关键词高亮处理
"pre_tags": ['<span class="gaoliang">'], # 高亮开始标签
"post_tags": ['</span>'], # 高亮结束标签
"fields": { # 高亮设置
"title": {} # 高亮字段
}
}
}
)
# 开始获取数据
total_nums = response["hits"]["total"] # 获取查询结果的总条数 hit_list = [] # 设置一个列表来储存搜索到的信息,返回给html页面 for hit in response["hits"]["hits"]: # 循环查询到的结果
hit_dict = {} # 设置一个字典来储存循环结果
if "title" in hit["highlight"]: # 判断title字段,如果高亮字段有类容
hit_dict["title"] = "".join(hit["highlight"]["title"]) # 获取高亮里的title
else:
hit_dict["title"] = hit["_source"]["title"] # 否则获取不是高亮里的title hit_dict["id"] = hit["_source"]["nid"] # 获取返回nid # 加密样音地址
hit_dict["yangsrc"] = jia_mi(str(hit["_source"]["yangsrc"])) # 获取返回yangsrc hit_list.append(hit_dict)
第三百六十七节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)scrapy写入数据到elasticsearch中的更多相关文章
- 第三百六十二节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)基本的索引和文档CRUD操作、增、删、改、查
第三百六十二节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)基本的索引和文档CRUD操作.增.删.改.查 elasticsearch(搜索引擎)基本的索引 ...
- 第三百七十二节,Python分布式爬虫打造搜索引擎Scrapy精讲—scrapyd部署scrapy项目
第三百七十二节,Python分布式爬虫打造搜索引擎Scrapy精讲—scrapyd部署scrapy项目 scrapyd模块是专门用于部署scrapy项目的,可以部署和管理scrapy项目 下载地址:h ...
- 第三百五十二节,Python分布式爬虫打造搜索引擎Scrapy精讲—chrome谷歌浏览器无界面运行、scrapy-splash、splinter
第三百五十二节,Python分布式爬虫打造搜索引擎Scrapy精讲—chrome谷歌浏览器无界面运行.scrapy-splash. splinter 1.chrome谷歌浏览器无界面运行 chrome ...
- 第三百七十七节,Django+Xadmin打造上线标准的在线教育平台—apps目录建立,以及数据表生成
第三百七十七节,Django+Xadmin打造上线标准的在线教育平台—apps目录建立,以及数据表生成 apps目录建立 我们创建一个apps目录,将所有的app放到apps目录里去,这样方便管理,也 ...
- 第三百二十七节,web爬虫讲解2—urllib库爬虫—基础使用—超时设置—自动模拟http请求
第三百二十七节,web爬虫讲解2—urllib库爬虫 利用python系统自带的urllib库写简单爬虫 urlopen()获取一个URL的html源码read()读出html源码内容decode(& ...
- 第三百九十七节,Django+Xadmin打造上线标准的在线教育平台—其他插件使用说,主题本地化设置
第三百九十七节,Django+Xadmin打造上线标准的在线教育平台—其他插件使用说,主题本地化设置 主题设置是在xadmin\plugins\themes.py这个文件 默认xadmin是通过下面这 ...
- 第三百八十七节,Django+Xadmin打造上线标准的在线教育平台—网站上传资源的配置与显示
第三百八十七节,Django+Xadmin打造上线标准的在线教育平台—网站上传资源的配置与显示 首先了解一下static静态文件与上传资源的区别,static静态文件里面一般防止的我们网站样式的文件, ...
- 第三百四十八节,Python分布式爬虫打造搜索引擎Scrapy精讲—通过自定义中间件全局随机更换代理IP
第三百四十八节,Python分布式爬虫打造搜索引擎Scrapy精讲—通过自定义中间件全局随机更换代理IP 设置代理ip只需要,自定义一个中间件,重写process_request方法, request ...
- 第三百四十三节,Python分布式爬虫打造搜索引擎Scrapy精讲—scrapy模拟登陆和知乎倒立文字验证码识别
第三百四十三节,Python分布式爬虫打造搜索引擎Scrapy精讲—scrapy模拟登陆和知乎倒立文字验证码识别 第一步.首先下载,大神者也的倒立文字验证码识别程序 下载地址:https://gith ...
随机推荐
- [Windows Azure] How to Monitor Cloud Services
How to Monitor Cloud Services To use this feature and other new Windows Azure capabilities, sign up ...
- ES6,新增数据结构Set的用法
ES6 提供了新的数据结构 Set. 特性 似于数组,但它的一大特性就是所有元素都是唯一的,没有重复. 我们可以利用这一唯一特性进行数组的去重工作. 单一数组的去重. let set6 = new S ...
- angular.js测试框架protracotr自带的webdriver-manager启动问题“Invalid or corrupt jarfile”
按照官网安装完protractor. 升级webdriver-manager,获取selenium-server-standalone库文件以及各种浏览器驱动文件. webdriver-manager ...
- 每日英语:Proactive Advice for Dealing With Grief: Seek Out New Experiences
When her husband died of cancer 10 years ago, Becky Aikman says she experienced grief and adapted to ...
- linux命令(51):set 指定行,直接替换并修改文件
sed 命令: 指定行,从第一行到第一行: 把该行的ssd,换成cd: -i 表示的是替换并直接修改文件: sed -i '1,1s/ssd/cd/g' test_file 命令使用: sed - ...
- 2015-07学习总结——网络编程(TCP/IP)
之前学习的主要内容是单机上的处理,比如编程语言.游戏编程.数据库.多媒体编解码.其实对网络也有些接触,比如WWW.HTTP.UDP/TCP.RTP.RTMP.SNMP.FTP.单播组播.Telnet. ...
- Windows API 错误码
在多数情况下,windows API在发生错误时很少抛出异常,多数是通过函数返回值进行处理.(windows api中无返回值的函数很少.) windows api错误处理通常按照以下方式:首先api ...
- JAVA-JSP内置对象之session对象设置并获得session生命周期
相关资料:<21天学通Java Web开发> session对象设置并获得session生命周期1.通过session对象的setMaxInactiveInterval()方法可以设置se ...
- wcf消息契约
1.最多一个参数和一个返回值,返回值和参数的类型都是消息类型. 下面的代码为定义一个消息契约的实例 [MessageContract] public class MyMessage { ...
- /.well-known/apple-app-site-association
Technical Q&A QA1919 Incoming requests for /.well-known/apple-app-site-association file Q: Why ...