Tkinter 之爬虫框架项目实战
一、效果图
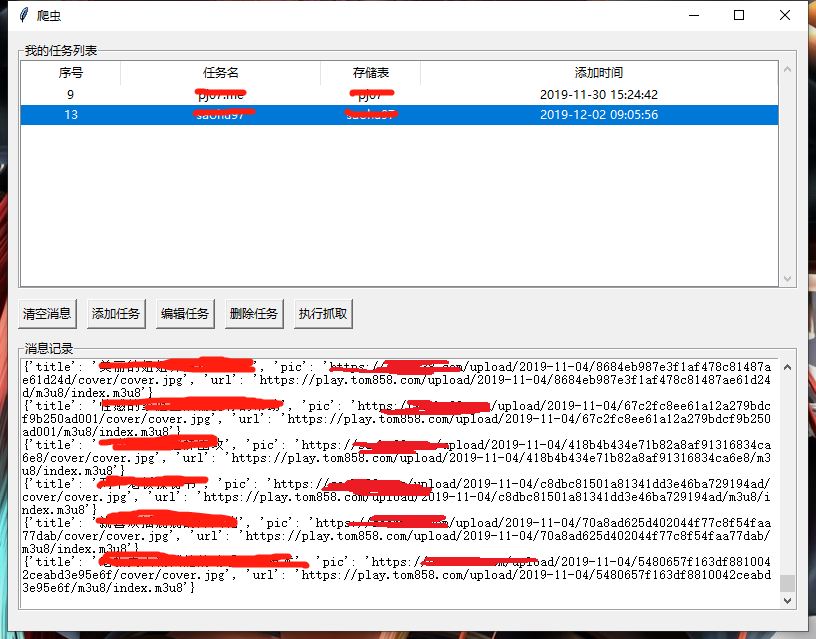
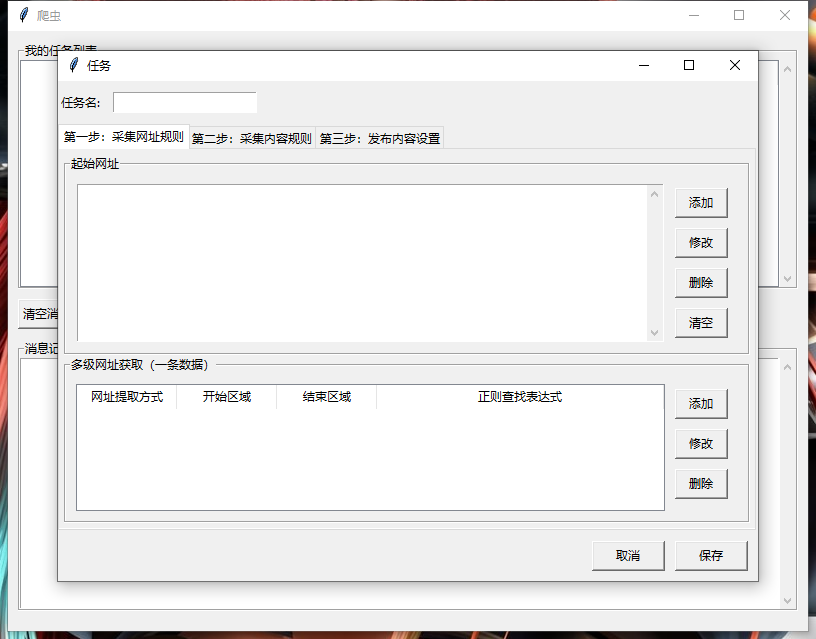
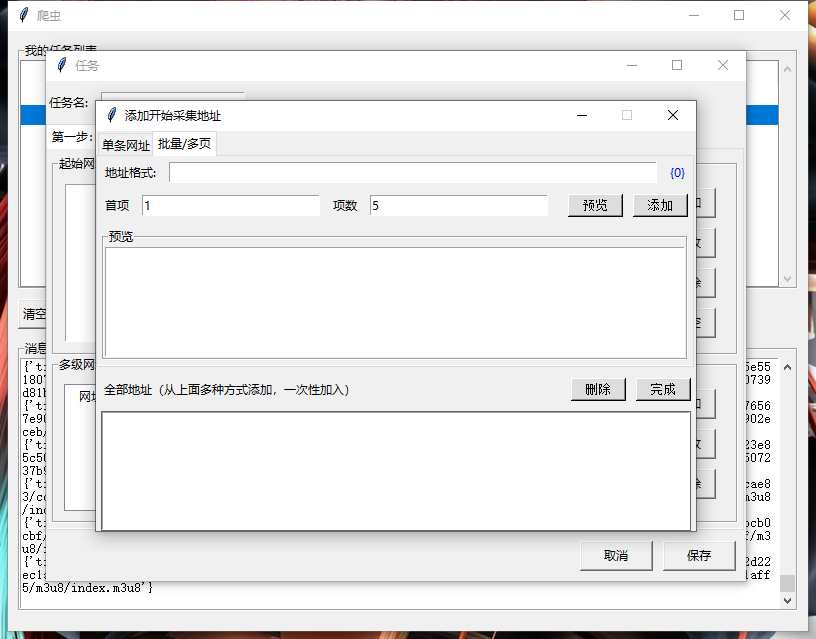
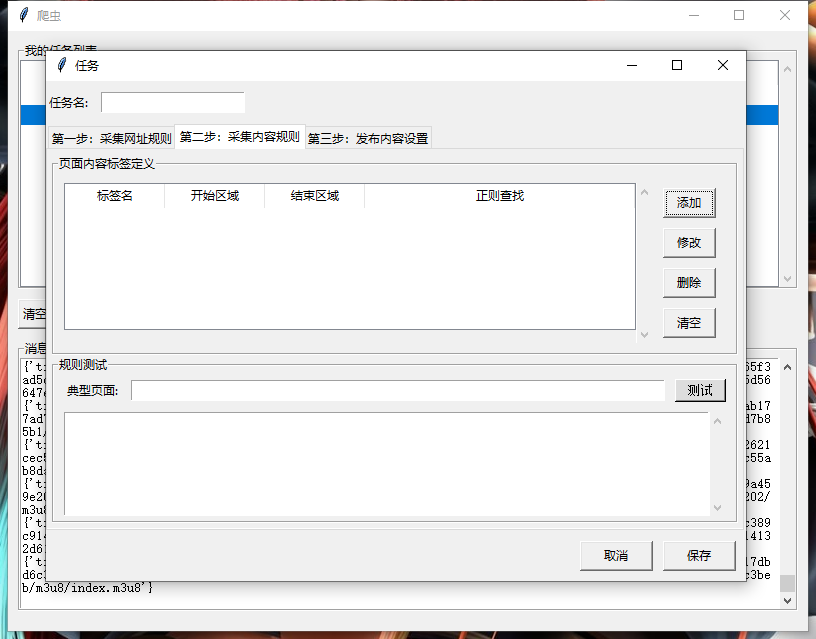
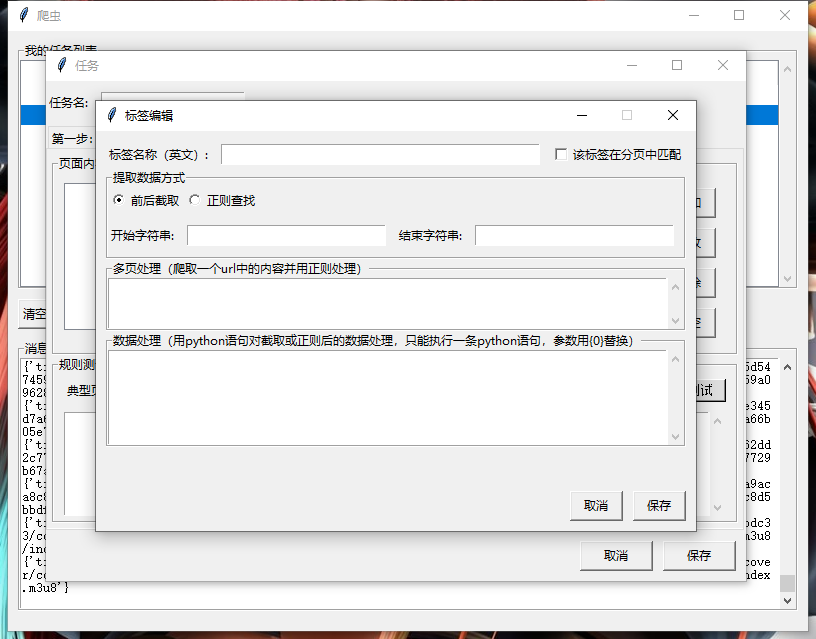
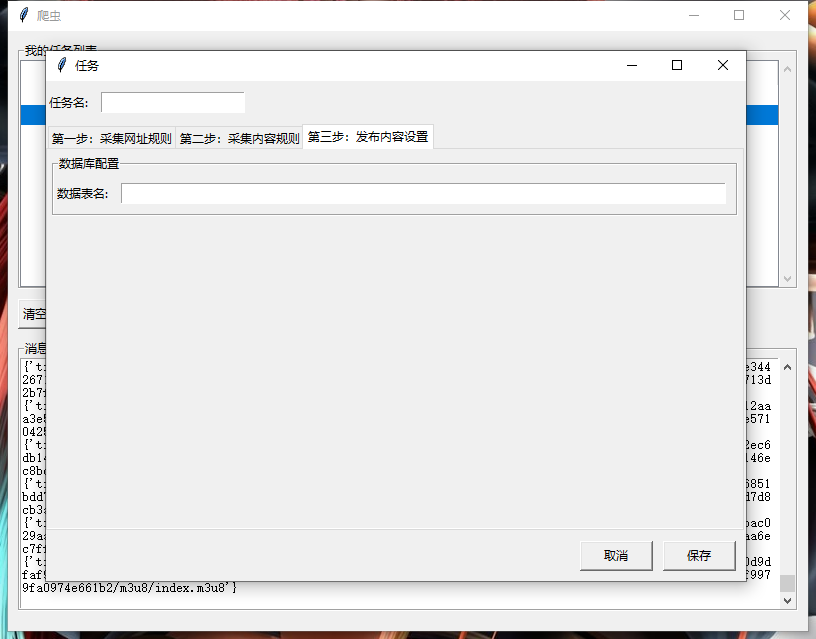
二、源码
''' 测试内容页爬取'''
def test_content_url(self):
try:
url = self.test_url_var.get().strip()
items = self.content_tree.get_children('')
content = self.get_html(url)
content_dict = {}
self.test_text.delete(1.0, END)
for item in items:
value = self.content_tree.item(item).get('values')
if value[4] == 0:
print(value)
if value[5] == 0:
# substring
return_value = self.deal_with_sustring(content, value[1], value[2]) if value[6]:
return_value = self.request_again(url, return_value, value[6])
if value[7]:
exec_content = value[7].format(return_value)
return_value = self.deal_with_python(exec_content)
return_value = self.c
content_dict[value[0]] = return_value
self.test_text.insert(END, value[0] + ': ' + return_value + '\n')
else:
# re
pattern = re.findall(value[3], content, re.I|re.M)
if pattern:
pattern_value = pattern[0]
else:
pattern_value = ''
if value[6]:
pattern_value = self.request_again(url, pattern_value, value[6])
if value[7]:
exec_content = value[7].format(pattern_value)
return_value = self.deal_with_python(exec_content)
self.test_text.insert(END, value[0] + ': ' + pattern_value + '\n')
content_dict[value[0]] = pattern_value
else:
print('%s在列表页提取' % value[0])
print(content_dict)
except Exception as e:
print(e)
self.test_text.insert(END, '错误信息:' + str(e))
有需要源码的可以评论哦~
Tkinter 之爬虫框架项目实战的更多相关文章
- Python爬虫教程-32-Scrapy 爬虫框架项目 Settings.py 介绍
本篇介绍项目开发的过程中,对 Setting 文件的配置和使用 Python爬虫教程-32-Scrapy 爬虫框架项目 Settings.py 介绍 settings.py 文件的使用 想要详细查看 ...
- Python爬虫教程-31-创建 Scrapy 爬虫框架项目
本篇是介绍在 Anaconda 环境下,创建 Scrapy 爬虫框架项目的步骤,且介绍比较详细 Python爬虫教程-31-创建 Scrapy 爬虫框架项目 首先说一下,本篇是在 Anaconda 环 ...
- Scrapy爬虫框架(实战篇)【Scrapy框架对接Splash抓取javaScript动态渲染页面】
(1).前言 动态页面:HTML文档中的部分是由客户端运行JS脚本生成的,即服务器生成部分HTML文档内容,其余的再由客户端生成 静态页面:整个HTML文档是在服务器端生成的,即服务器生成好了,再发送 ...
- 纯手写SpringMVC到SpringBoot框架项目实战
引言 Spring Boot其设计目的是用来简化新Spring应用的初始搭建以及开发过程.该框架使用了特定的方式来进行配置,从而使开发人员不再需要定义样板化的配置. 通过这种方式,springboot ...
- UI自动化测试框架(项目实战)python、Selenium(日志、邮件、pageobject)
其实百度UI自动化测试框架,会出来很多相关的信息,不过就没有找到纯项目的,无法拿来使用的:所以我最近就写了一个简单,不过可以拿来在真正项目中可以使用的测试框架. 项目的地址:https://githu ...
- scrapy爬虫框架入门实战
博客 https://www.jianshu.com/p/61911e00abd0 项目源码 https://github.com/ppy2790/jianshu/blob/master/jiansh ...
- python爬虫小项目实战
- jsoup爬虫,项目实战,欢迎收看
import com.mongodb.BasicDBObject import com.mongodb.DBCollection import org.jsoup.Jsoup import org.j ...
- Python爬虫教程-30-Scrapy 爬虫框架介绍
从本篇开始学习 Scrapy 爬虫框架 Python爬虫教程-30-Scrapy 爬虫框架介绍 框架:框架就是对于相同的相似的部分,代码做到不出错,而我们就可以将注意力放到我们自己的部分了 常见爬虫框 ...
随机推荐
- 一分钟告诉你什么是OPC DA质量代码
[关于TOP Server OPC Server试用版可登录慧都网该产品下载页进行下载] OPC DA(OPC实时数据访问规范)定义了包括数据值,更新时间与数据品质信息的相关标准.这个定义相信大家都很 ...
- 编辑/etc/passwd文件进行权限升级的技巧
0x00 前言 在本文中,我们将学习“修改/etc/passwd文件以创建或更改用户的root权限的各种方法”.有时,一旦目标被攻击,就必须知道如何在/etc/passwd文件中编辑自己的用户以进行权 ...
- Python使用numpy进行数据转换
一.测试数据 二.代码实现 # -*- coding: utf-8 -*- """ Created on Sun Jul 7 11:35:01 2019 加载数据时对指定 ...
- 【体系结构】有关Oracle SCN知识点的整理
[体系结构]有关Oracle SCN知识点的整理 1 BLOG文档结构图 BLOG_Oracle_lhr_Oracle SCN的一点研究.pdf 2 前言部分 2.1 导读和注意事项 各位技 ...
- 部署GitLab时, 问题
1. 开启防火墙可能会对 nginx 造成影响. 2. 安装 gitlab 会自带一个 nginx, 启动后会对 现有的nginx 造成影响, 解决方案 参考 连接 1
- Ubuntu 开发环境搭建
一.修改权限 Ubuntu 用户权限相关命令 - 彭浪 - 博客园 Ubuntu 文件文件夹查看权限和设置权限 - 朝阳的向日葵 - 博客园 二.安装简体中文支持 三.安装搜狗输入法 四.安装Goog ...
- 修改mysql数据存储位置
停止mysql服务. 在mysql安装目录下找到mysql配置文件my.ini. 在my.ini中找到mysql数据存储位置配置datadir选项,比如我电脑上的配置如下: # Path to the ...
- python-pyhon与模块安装
python 安装Python,配置环境变量,路径为python安装路径,如D:\pythoncmd中输入python可以识别则安装成功 pip升级指令python -m pip install -- ...
- 【快捷键】印象笔记Markdown快捷键
新建 Markdown 笔记 CMD+D 粗体 CMD+B 斜体 CMD+I 删除线 CMD+S 分隔线 CMD+L 编号列表 CMD+Shift+O 项目符号列表 CMD+Shift+U 插入待办事 ...
- Xshell连接虚拟机中的Ubuntu
虚拟机中安装好Ubuntu系统后使用cmd测试ping 设置xshell的连接ip 连接 连接失败 安装openssh-server sudo apt install openssh-server 再 ...