Tkinter 之爬虫框架项目实战
一、效果图
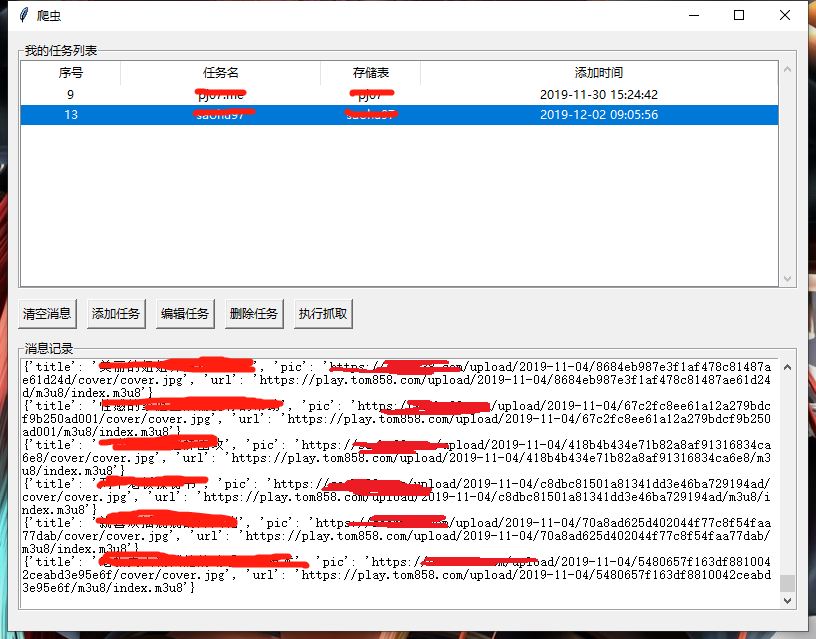
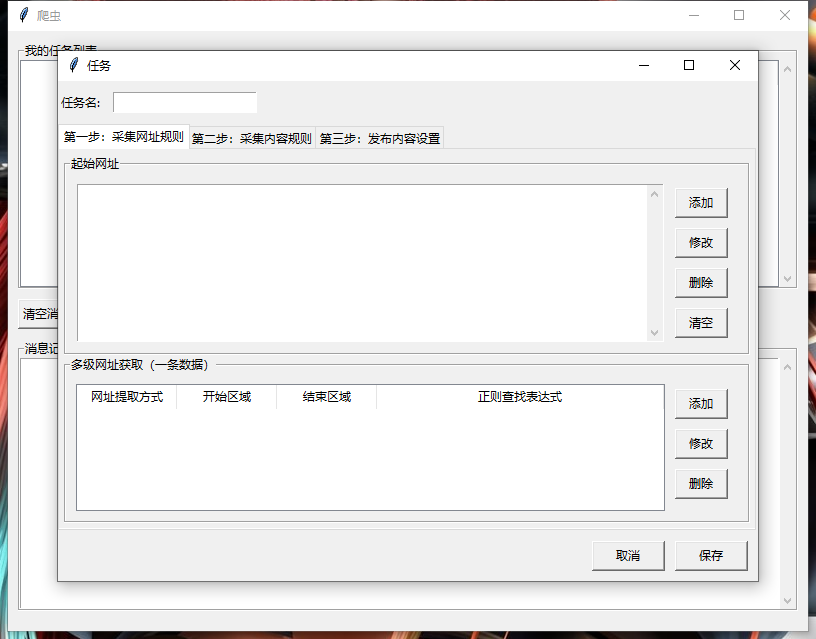
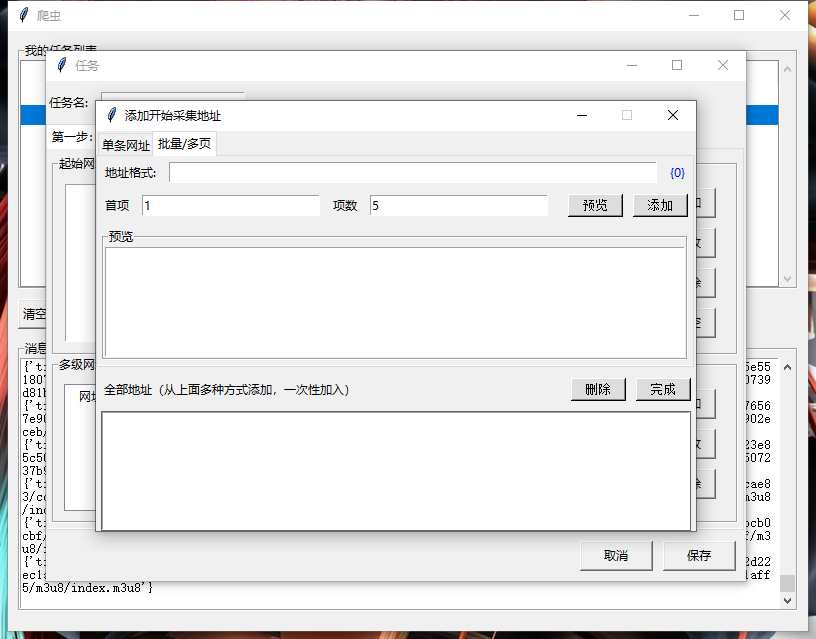
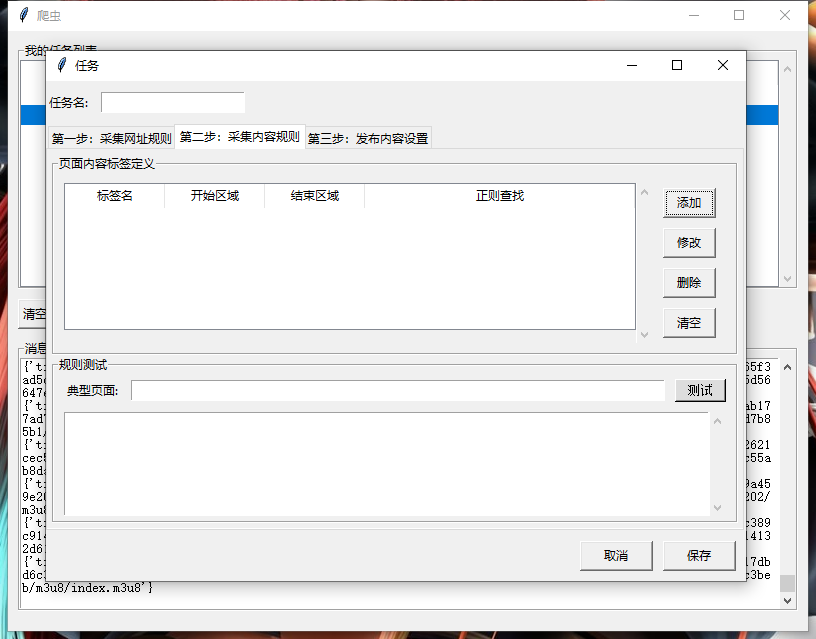
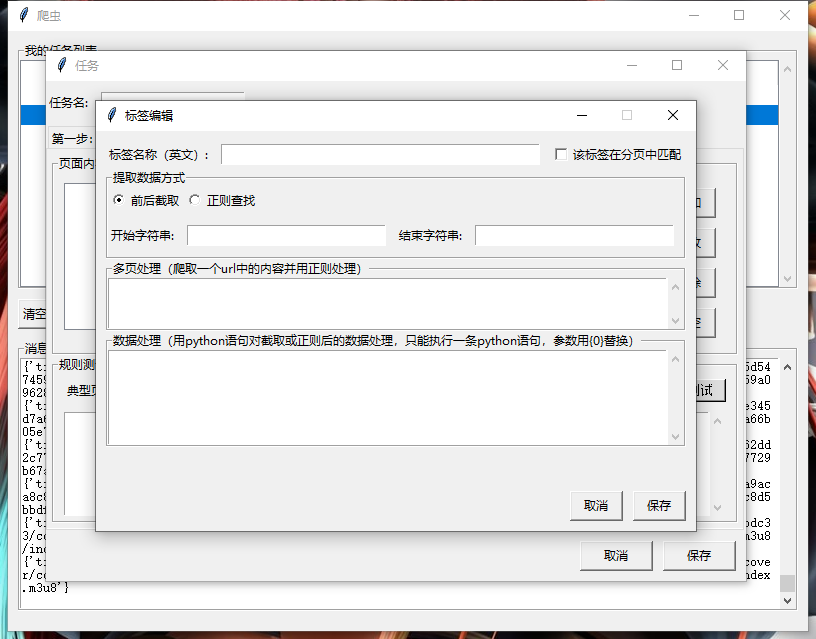
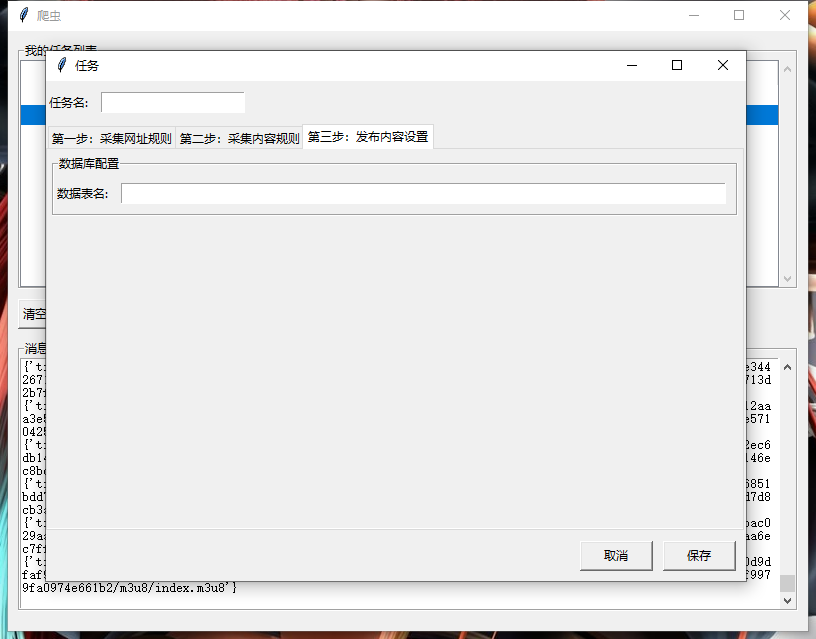
二、源码
''' 测试内容页爬取'''
def test_content_url(self):
try:
url = self.test_url_var.get().strip()
items = self.content_tree.get_children('')
content = self.get_html(url)
content_dict = {}
self.test_text.delete(1.0, END)
for item in items:
value = self.content_tree.item(item).get('values')
if value[4] == 0:
print(value)
if value[5] == 0:
# substring
return_value = self.deal_with_sustring(content, value[1], value[2]) if value[6]:
return_value = self.request_again(url, return_value, value[6])
if value[7]:
exec_content = value[7].format(return_value)
return_value = self.deal_with_python(exec_content)
return_value = self.c
content_dict[value[0]] = return_value
self.test_text.insert(END, value[0] + ': ' + return_value + '\n')
else:
# re
pattern = re.findall(value[3], content, re.I|re.M)
if pattern:
pattern_value = pattern[0]
else:
pattern_value = ''
if value[6]:
pattern_value = self.request_again(url, pattern_value, value[6])
if value[7]:
exec_content = value[7].format(pattern_value)
return_value = self.deal_with_python(exec_content)
self.test_text.insert(END, value[0] + ': ' + pattern_value + '\n')
content_dict[value[0]] = pattern_value
else:
print('%s在列表页提取' % value[0])
print(content_dict)
except Exception as e:
print(e)
self.test_text.insert(END, '错误信息:' + str(e))
有需要源码的可以评论哦~
Tkinter 之爬虫框架项目实战的更多相关文章
- Python爬虫教程-32-Scrapy 爬虫框架项目 Settings.py 介绍
本篇介绍项目开发的过程中,对 Setting 文件的配置和使用 Python爬虫教程-32-Scrapy 爬虫框架项目 Settings.py 介绍 settings.py 文件的使用 想要详细查看 ...
- Python爬虫教程-31-创建 Scrapy 爬虫框架项目
本篇是介绍在 Anaconda 环境下,创建 Scrapy 爬虫框架项目的步骤,且介绍比较详细 Python爬虫教程-31-创建 Scrapy 爬虫框架项目 首先说一下,本篇是在 Anaconda 环 ...
- Scrapy爬虫框架(实战篇)【Scrapy框架对接Splash抓取javaScript动态渲染页面】
(1).前言 动态页面:HTML文档中的部分是由客户端运行JS脚本生成的,即服务器生成部分HTML文档内容,其余的再由客户端生成 静态页面:整个HTML文档是在服务器端生成的,即服务器生成好了,再发送 ...
- 纯手写SpringMVC到SpringBoot框架项目实战
引言 Spring Boot其设计目的是用来简化新Spring应用的初始搭建以及开发过程.该框架使用了特定的方式来进行配置,从而使开发人员不再需要定义样板化的配置. 通过这种方式,springboot ...
- UI自动化测试框架(项目实战)python、Selenium(日志、邮件、pageobject)
其实百度UI自动化测试框架,会出来很多相关的信息,不过就没有找到纯项目的,无法拿来使用的:所以我最近就写了一个简单,不过可以拿来在真正项目中可以使用的测试框架. 项目的地址:https://githu ...
- scrapy爬虫框架入门实战
博客 https://www.jianshu.com/p/61911e00abd0 项目源码 https://github.com/ppy2790/jianshu/blob/master/jiansh ...
- python爬虫小项目实战
- jsoup爬虫,项目实战,欢迎收看
import com.mongodb.BasicDBObject import com.mongodb.DBCollection import org.jsoup.Jsoup import org.j ...
- Python爬虫教程-30-Scrapy 爬虫框架介绍
从本篇开始学习 Scrapy 爬虫框架 Python爬虫教程-30-Scrapy 爬虫框架介绍 框架:框架就是对于相同的相似的部分,代码做到不出错,而我们就可以将注意力放到我们自己的部分了 常见爬虫框 ...
随机推荐
- 用GraphicsMagick处理svg转png遇到的坑
1前言 用GraphicsMagick处理svg转png,且背景是透明且没有黑边,由于使用虚拟机的gm版本是1.3.28导致有黑边问题且svg中path中有opacity属性时,加上+antialia ...
- ssm(spring+springmvc+mybatis)整合之环境配置
1-1.导包 导入SpringMVC.Spring.MyBatis.mybatis-spring.mysql.druid.json.上传和下载.验证的包 1-2.创建并配置web.xml文件 配置sp ...
- nodeJS从入门到进阶二(网络部分)
一.网络服务器 1.http状态码 1xx: 表示普通请求,没有特殊含义 2xx:请求成功 200:请求成功 3xx:表示重定向 301 永久重定向 302 临时重定向 303 使用缓存(服务器没有更 ...
- vue+element 按钮来回切换
需求很简单,实现很容易,日常记录一下 templace代码: data数据声明: me'thods方法:
- MySQL删除语句
删除数据(DELETE) 使用前需注意:删除(DELETE),是删除一(条)行数据.假如我们有四条(行)数据,换句话说,你要删除其中一条(行) 名字为“xx”的用户,那么关于他的 i所有数据都会被删除 ...
- MySQL Replication--复制延迟03--Seconds_Behind_Master计算
Seconds_Behind_Master计算原理 当从库上复制IO进程和复制SQL进程正常运行,且SQL线程处于执行状态而非等待IO进程同步BINLOG时,复制延迟时间计算如下: 复制延迟时间(Se ...
- SQL LISTAGG 合并行
LISTAGG Syntax 语法 listagg_overflow_clause::= Purpose For a specified measure, LISTAGG orders data w ...
- php后端模式,php-fpm以及php-cgi, fast-cgi,以及与nginx的关系
关于cgi是什么,fast-cgi是什么,php-cgi是什么,fast-cgi是什么,下面这篇讲的很清楚: https://segmentfault.com/q/1010000000256516 另 ...
- LeetCode LCP 3 机器人大冒险
题目解析: 对于本题主要的核心是对于一个指令字符串如“RURUU”,如果我们假设它的终点坐标为(8,8),其实只要统计指令字符串中的R的个数和U的个数(对于我给出的例子而言,num_R == 2,nu ...
- Codeforces E. Weakness and Poorness(三分最大子列和)
题目描述: E. Weakness and Poorness time limit per test 2 seconds memory limit per test 256 megabytes inp ...