spark集成kerberos
1、生成票据
1.1、创建认证用户
登陆到kdc服务器,使用root或者可以使用root权限的普通用户操作:
# kadmin.local -q “addprinc -randkey spark/yjt”
1.2、生成密钥文件
生成spark密钥文件
# kadmin.local -q “xst -norankey -k /etc/spark.keytab spark/yjt”
拷贝sparkkeytab到所有的spark集群节点的conf目录下
1.3、修改权限
# chmod 404 /data1/hadoop/spark/conf/spark.keytab
# chown hduser:hduser /data1/hadoop/spark/conf/spark.keytab
2、集群内部测试
2.1、获取票据
# klint -it /data1/hadoop/spark/conf/spark.keytab spark/yjt
(1)、本地机器测试
# spark-submit --principal spark/yjt --keytab /data1/hadoop/spark/conf/spark.keytab --class org.apache.spark.examples.SparkPi examples/jars/spark-examples_2.11-2.4.0.jar 10
(2) 、提交到yarn, 模式是client
spark-submit --principal spark/yjt --keytab /data1/hadoop/spark/conf/spark.keytab --class org.apache.spark.examples.SparkPi --master yarn examples/jars/spark-examples_2.11-2.4.0.jar 10
查看8088信息:

(3) 、提交到yarn集群,模式是cluster
# spark-submit --principal spark/yjt --keytab /data1/hadoop/spark/conf/spark.keytab --class org.apache.spark.examples.SparkPi --master yarn --deploy-mode cluster examples/jars/spark-examples_2.11-2.4.0.jar 10
查看8088信息:

3、客户端测试
3.1、hduser用户测试
安装spark或者从集群拷贝一份到客户端
客户端测试用户使用hduser
获取票据
# kinit -kt /data1/hadoop/spark/conf/spark.keytab spark/yjt

(1) 、提交到本地集群
# ./bin/spark-submit --principal spark/yjt --keytab /data1/hadoop/spark/conf/spark.keytab --class org.apache.spark.examples.SparkPi --master spark://192.168.0.230:7077 examples/jars/spark-examples_2.11-2.4.0.jar 10
注意:使用这种方式提交需要在集群里面的hosts文件配置客户端的主机域名映射关系。
(2) 、提交到yarn,模式client
# ./bin/spark-submit --principal spark/yjt --keytab /data1/hadoop/spark/conf/spark.keytab --class org.apache.spark.examples.SparkPi --master yarn examples/jars/spark-examples_2.11-2.4.0.jar 10
注:这种方式也需要在集群内部设置客户端主机名映射关系
(3) 、提交到yarn,模式cluster
# ./bin/spark-submit --principal spark/yjt --keytab /data1/hadoop/spark/conf/spark.keytab --class org.apache.spark.examples.SparkPi --master yarn --deploy-mode cluster examples/jars/spark-examples_2.11-2.4.0.jar 10

3.2、其他用户测试
(1)、创建用户yujt
# useradd -s /bin/bash -m -d /home/yujt -G hduser yujt
# echo “Your Password” | passwd --stdin yujt
(2)、修改spark.keytab权限
# chmod 404 /data1/hadoop/spark/conf/spark.keytab
注: 以上操作root或者sudo,需要root权限
# su - yujt
(3)、修改yujt这个用户的环境变量
修改用户的~/.bashrc文件,添加如下信息:(当然最好是直接修改/etc/profile,这样在创建用户的时候就不需要为每个用户添加环境变量信息)
export JAVA_HOME=/data1/hadoop/jdk
export PATH=${JAVA_HOME}/bin:$PATH
export HADOOP_HOME=/data1/hadoop/hadoop
export PATH=${HADOOP_HOME}/bin:${HADOOP_HOME}/sbin:$PATH
(4) 、测试本地standlone模式
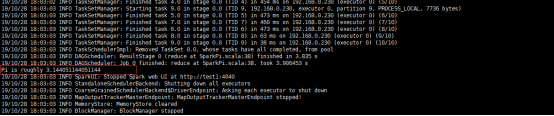
# ./bin/spark-submit --principal spark/yjt --keytab /data1/hadoop/spark/conf/spark.keytab --class org.apache.spark.examples.SparkPi --master spark://192.168.0.230:7077 examples/jars/spark-examples_2.11-2.4.0.jar 10
如上述,执行成功。
(5) 、测试yarn, 部署模式client
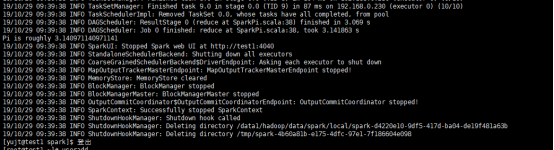
# $ ./bin/spark-submit --principal spark/yjt --keytab /data1/hadoop/spark/conf/spark.keytab --class org.apache.spark.examples.SparkPi --master yarn examples/jars/spark-examples_2.11-2.4.0.jar 10
执行结果如下:

Web界面如下:

(6) 、测试yarn, 部署模式cluster

注:上述在执行任务的时候,我们使用了--principal 和--keytab参数,其实,如果使用kinit -kt /data1/hadoop/spark/conf/spark.keytab spark/yjt获取了票据以后,可以省略这两个参数。
spark集成kerberos的更多相关文章
- Spark:利用Eclipse构建Spark集成开发环境
前一篇文章“Apache Spark学习:将Spark部署到Hadoop 2.2.0上”介绍了如何使用Maven编译生成可直接运行在Hadoop 2.2.0上的Spark jar包,而本文则在此基础上 ...
- spark集成hive遭遇mysql check失败的问题
问题: spark集成hive,启动spark-shell或者spark-sql的时候,报错: INFO MetaStoreDirectSql: MySQL check failed, assumin ...
- Ambari集成Kerberos报错汇总
Ambari集成Kerberos报错汇总 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.查看报错的配置信息步骤 1>.点击Test Kerberos Client,查看相 ...
- HDP安全之集成kerberos/LDAP、ranger(knox自带LDAP)
----------------------目录导航见左上角------------------------------- 环境 HDP 3.0.1.0 (已有) JDK 1.8.0_91 (已有 ...
- Spark集成
一.Spark 架构与优化器 1.Spark架构 (重点) 2.Spark优化器 二.Spark+SQL的API (重点) 1.DataSet简介 2.DataFrame简介 3.RDD与DF/DS的 ...
- 机器学习 - pycharm, pyspark, spark集成篇
AS WE ALL KNOW,学机器学习的一般都是从python+sklearn开始学,适用于数据量不大的场景(这里就别计较“不大”具体指标是啥了,哈哈) 数据量大了,就需要用到其他技术了,如:spa ...
- 挖坑:hive集成kerberos
集成hive+kerberos前,hadoop已经支持kerberos,所以基础安装略去: https://www.cnblogs.com/garfieldcgf/p/10077331.html 直接 ...
- 机器学习 - 开发环境安装pycharm + pyspark + spark集成篇
AS WE ALL KNOW,学机器学习的一般都是从python+sklearn开始学,适用于数据量不大的场景(这里就别计较“不大”具体指标是啥了,哈哈) 数据量大了,就需要用到其他技术了,如:spa ...
- hive集成kerberos
1.票据的生成 kdc服务器操作,生成用于hive身份验证的principal 1.1.创建principal # kadmin.local -q “addprinc -randkey hive/yj ...
随机推荐
- Source roots (or source folders) Test source roots (or test source folders; shown as rootTest)Resource rootsTest resource roots
idea中Mark Directory As里的Sources Root.ReSources Root等的区别 1.Source roots (or source folders) 通过这个类指定一个 ...
- 四级CET大学词汇六级备份
Cet6六级中要考到法庭词汇的小故事 如何安排六级考试前的一个月1.每天按照我的要求去背单词2.做四套真题,词汇部分 只做词汇 3.做personal dictionary把真题中出现的所有不认识的 ...
- 使用虹软ArcFac,java 离线SDK 进行人脸识别
公司项目需要人脸识别登录,需要支持离线识别,所以无法使用在线的人脸识别的API,于是使用到了离线SDK来对比识别人脸相识度. 获取人脸抓拍的图片需要对接设备,这里不做记录,假设我们已经获取到了人脸图片 ...
- php 弹窗案例
<?php // 弹出对话框并且返回原来的页面 echo "<script language=\"JavaScript\">\r\n"; ec ...
- Django-模型层(多表操作)
目录 1.创建模型 1.1方式一:自行创建第三张表 1.2方式二:通过ManyToManyField自动创建第三张表 1.3关于db_column和verbose_name 1.4关于on_delet ...
- Python_正则表达式语法
1.正则表达式中的操作符: 2.re库的使用: import re #search方法要求只要待匹配的字符串中包含正则表达式中的字符串就可以 match = re.search('python+',' ...
- session和cookie的区别和联系详解,Cookie Session相关看这篇就够了。
本文转自:91博客:原文地址:http://www.9191boke.com/199015867.html 有一朋友做面试官的时候,曾经问过很多朋友这个问题: Cookie 和 Session 有什么 ...
- PC软件/web网站/小程序/手机APP产品如何增加个人收款接口
接入前准备 通过 XorPay 注册个人收款接口,原理是帮助你签约支付宝和微信(不需要营业执照)支持个人支付宝和个人微信支付接口,大概几分钟可以开通,开通后即可永久使用 PC 网站接入 效果:用户点击 ...
- Linux跑脚本用sh和./有什么区别?
一个很有意思的例子: sh是一个shell.运行sh a.sh,表示我使用sh来解释这个脚本:如果我直接运行./a.sh,首先你会查找脚本第一行是否指定了解释器,如果没指定,那么就用当前系统默认的sh ...
- D. Nested Segments(树状数组、离散化)
题目链接 参考博客 题意: 给n个线段,对于每个线段问它覆盖了多少个线段. 思路: 由于线段端点是在2e9范围内,所以要先离散化到2e5内(左右端点都离散化了,而且实际上离散化的范围是4e5),然后对 ...