从输入url到浏览器显示页面的过程
总体来说有两个大的方面:
一、网络通信连接部分。二、页面渲染展示部分。
细分详细过程:
(网络通信)
1、输入url。
2、DNS解析域名。
3、拿到IP地址后,浏览器向服务器建立tcp连接。
4、浏览器向web服务器发送http请求。
5、服务器收到请求并响应。
(页面渲染)
6、服务器返回相应文件,浏览器进行页面渲染。
详细描述之前,先拉个概念出来:
网络通信协议:
一、OSI模型(开放式系统互连)
1、应用层。文件传输,虚拟终端 TFTP,HTTP,SNMP,FTP,SMTP,DNS,Telnet
2、表示层。代码转换,数据加密,没有协议
3、会话层。解除或建立与别的接点的联系,没有协议
4、传输层。提供端对端的接口 TCP,UDP
5、网络层。为数据包选择路由 IP,ICMP,RIP,OSPF,BGP,IGMP
6、数据链路层。传输有地址的帧以及错误检测功能 SLIP,CSLIP,PPP,ARP,RARP,MTU
7、物理层。
注:没有协议指不具体包含在TCP/IP协议里。
二、TCP/IP协议(模型)
1、应用层。HTTP,FTP,Telnet,SMTP和 Gopher等(应用层,表示层,会话层)
2、传输层。tcp,udp
3、网络互联层。ip,icmp(网络层)
4、网络接口层。(数据链路层,物理层)
图是借鉴的==

注:TCP/IP与OSI区别在于OSI是一个理论上的网络通信模型,而TCP/IP则是实际运行的网络协议。
好了,开始上大菜了!
1、输入url。
在你输入地址的时候,浏览器就已经开始智能匹配缓存中(比如历史记录、书签)的地址了,体验详见地址栏的补全功能。一般网络地址有域名和IP地址,域名方便记忆,但是为了让计算机这个高级物种理解我们还是要把域名转换成IP地址,互联网上每一台计算机的唯一标识就是它的IP地址,所以就引出了下文。
2、DNS解析域名。
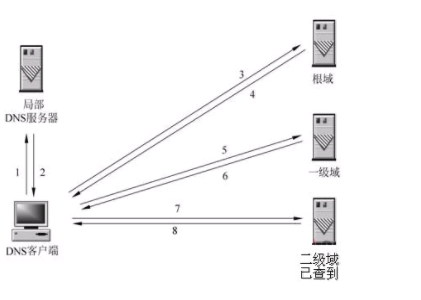
这个知识点比较厉害了。DNS域名系统,因特网上作为域名和IP地址相互映射分布式数据库。说白了DNS就是充当域名和IP地址之间翻译官的角色,把域名(网址)翻译成对应的IP地址,俗称域名解析。说说怎么解析:
1> 首先客户端检查本地是否有对应的IP地址,查看本地磁盘的hosts文件,看是否有对应的IP地址,有那就直接使用文件给到的IP地址,如若没有,那就接着看。
2> 浏览器会发送一个DNS请求到本地的DNS服务器(例如中国电信啊,移动啊,这些网络提供商提供的)本地的DNS服务器收到请求后,先查询它的缓存记录,缓存中有要找的记录,那么返回IP地址,如果没有要找的记录,那么本地DNS服务器会向根服务器进行查找(递归查询)。
查询方式例如: .com -> baidu.com. -> www.baidu.com.
3> 如果根域服务器没有查到域名和IP的对应结果。它会返回来告诉本地DNS服务器你可以去域服务器(例如.com.服务器)上接着找了,顺带给出你要找的域服务器的地址(迭代查询)。然后本地服务器再次向域服务器发送查询请求,如果域服务器有域名和IP的对应关系,那么,域服务器才不会给你返回结果!它会告诉你你所需要域名解析的服务器的地址。
4> 本地服务器再次向域名解析服务器发出请求,这时拿到对应的结果,它不仅会把IP地址返回给客户机,而且会把这一结果保存在缓存中,便于下次查找使用(这里有个大概念,DNS缓存,属于DNS优化范畴)。
这个图也是借鉴的==

下来就抛出了三个概念:
1、递归查询。
这个图也是借鉴的==

2、迭代查询。
这个图也是借鉴的==
拓展:
这个图也是借鉴的==

3、负载均衡。
这是一个大学问,现在北京时间凌晨2.26。不细总结了,这个就是说如果网站访问量大,为一个主机名配置多个IP地址,对应每个DNS查询分配不同的IP地址,达到开源节流的目的。这个区分可以是地理位置啊,大的功能啊。
先写到这,贼困,闲了继续码。
回来了,上朝!
3、拿到IP地址后,浏览器向服务器建立tcp连接。
这里就到了网络通信的应用层。在拿到域名对应的IP地址后,浏览器会以一个随机端口(1024<端口<65535)向服务器的WEB程序80端口发起TCP的连接请求。这中间经历一段漫长而又复杂的旅程(路由器啊,网卡啊,设备等等...)最终到达了web程序,然后建立tcp的连接,并发起http请求。
这里扔出三个概念:
1、TCP(传输控制协议)
属于传输层协议,为应用程序提供可靠的通信连接。适合于一次传输大批数据的情况。并适用于要求得到响应的应用程序。
2、http(超文本传输协议)
属于应用层协议,是请求与响应模式的、无状态的协议,常基于TCP的连接方式。
3、https
http报文是包裹在tcp报文下发送过去的,服务器在收到tcp报文的时候,会把里面的http报文提取出来。这里就有一个问题,http报文是明文,如果传输不当中途被截取了那么可能存在信息泄露的风险。有个解决办法就是,在http进入tcp的时候把http报文进行加密,加密使用到SSL技术(SSL具体还在研究中)顾名思义https=http+SSL。
HTTPS介于http 和tcp之间,在传输数据前需要和客户端与服务器双方进行一个握手(TLS/SSL),在握手过程中确立双方加密传输数据的密码信息。个人理解说白了就是http的加密。
附加:抛个网络协议的知识点传送门http://blog.csdn.net/ithomer/article/details/5662524
4、浏览器向web服务器发送http请求。
发起的http请求这一行为发生在客户端,实质上就是把http请求报文通过tcp协议发送到指定的服务器端口。写到这里,会发现生成了两个大的知识点,第一:http请求报文都有什么内容。第二:通过tcp的传输过程经历了什么。
搞清楚逻辑嵌套,下来就好逐一分析了。
一、http请求报文有什么内容:
http请求包含请求行,请求头和请求主体。
1、请求行:
包含请求url版本,包含请求方法:GET和POST(这个知识点在之后的ajax相关博客中细说)
2、请求头:
常见的请求报头有: Accept, Accept-Charset, Accept-Encoding, Accept-Language, Content-Type, Authorization, Cookie, User-Agent等。包含可以申明浏览器所用语言,数据是否要缓存,和一些协议类信息。
3、请求主体:
包含客户端向服务器提交的数据。
GET/sample.jspHTTP/1.1 Accept:image/gif.image/jpeg,*/* Accept-Language:zh-cn
Connection:Keep-Alive Host:localhost User-
Agent:Mozila/4.0(compatible;MSIE5.01;Window NT5.0) Accept-Encoding:gzip,deflate
username=jinqiao&password=123
注:请求头和请求体之间必须要有一个换行,意味着请求头的结束请求体的开始。
二、通过tcp的传输过程经历了什么
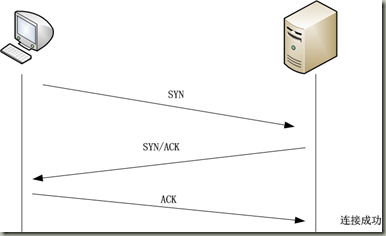
1、三次握手:tcp协议为了方便传输报文,会把发送的请求报文拆分成小的报文段进行管理,并把它们编号,为了服务器能准确具体的还原返回报文信息。客户端发送一个带有SYN标志的数据包给接收端,然后等待接收端回复。接收端收到数据包之后再给客户端返回一个带有SYN/ACK标志的数据包以示确认。客户端收到数据包后返回一个ACK标志的数据包给服务器以表示握手成功,就是告诉双方,好了,我俩已经建立连接了,现在可以开始传输数据了。中间在规定的延迟时间里双方没有收到数据包,那么重新发送。很好理解,贴出张图片:
注:为什么需要三次握手:为了防止已失效的连接请求报文段突然又传送到了服务端,因而产生错误。(摘录)
图片还是借鉴的==
传输方式知道了,下来就要开始确定每次传输数据包的具体传输人了,这里产生了两个概念IP协议和mac地址(物理地址)。传输过程中IP协议需要把tcp分割好的数据包发送给接收端,这时它需要得到接收端的mac地址(固定的,IP地址(可变)和MAC地址是对应关系,可以使用ARP协议将IP地址转化为MAC地址),才能准确的把数据包发送过去。当通信的双方不在同一个局域网时,需要多次中转才能把数据发送成功,在中转的过程中凭借下一个MAC地址来查找到下一个接收方,最后达到成功传输的目的。
2、四次挥手:用来断开连接(这里就不做详细描述了)
HTTP/1.1 200 OK
Date: Sat, 31 Dec 2005 23:59:59 GMT Content-Type: text/html;charset=ISO-8859-1
Content-Length: 122 <html> <head> <title>http</title>
</head>
<body> <!-- body goes here --> </body>
</html>
2xx:成功,表示服务器已成功接收到请求并进行处理。
3xx:重定向,表示服务器要求客户端重定向。
4xx:客户端错误,例404请求资源不存在。
5xx:服务器错误,服务器未正常处理客户端的请求而出现的错误。
拓展:
服务器的永久重定向响应:
这个知识点介于客户端发送http请求和服务器返回http响应之间。(其实是已经到达服务器了)
举个栗子,输入两个网站http://sohu.com 和http://www.souhu.com,搜索引擎会以为它们是两个网站,这样会减少搜索率,使得网站在搜索引擎的排名会降低,而搜索引擎得到301重定向后,会把这两个网站划分到一个网站下面,增加搜索排名。同时这样也会节约缓存资源。就是说服务器给浏览器响应一个301永久重定向响应浏览器就会直接访问http://www.souhu,com
重定向原因:(摘录)
6、服务器返回相应文件,浏览器进行页面渲染。
从网站上黏贴过来:解析html以构建dom树 -> 构建render树 -> 布局render树 -> 绘制render树
说说自己的理解,浏览器在未全部接收到HTML文件的时候,就已经开始进行dom树(HTML结构)的渲染了,其中js,css,img文件和dom树的请求方式是异步的(就是说如果遇到外链的文件下载的时候浏览器会再次发送http请求重复上述步骤),两者并不会相互影响。也就是说先渲染html结构,然后浏览器再向服务器发送请求下载js,css图片等文件。
浏览器先渲染了dom结构,在收到css文件的时候,会把css里的样式加入到dom结构里进行渲染,js文件会改变dom结构的排序,在加载js文件的时候,HTML的渲染就会暂停(排除有async属性的结束文件,当然此类文件也禁止使用document.write();),虽然说css的加载不会影响js的加载,但是也必须保证在js加载之前,css,HTML都要加载完毕,所以说这就是为什么开发网页要把js文件放在页面最下面(中间还有个知识点js阻塞)。这里面就涉及到了回流和重绘,这两者非常消耗网站性能。
-----------------------------------------我是华丽的分割线---------------------------------------
总结:
在实习的第一家公司就学习整理过从url到页面的相关内容,这次把笔记翻出来,重新整理,文笔还有待改进,这篇博文写了三天。网络协议方面的内容好久不接触,忘了挺多,所以参考了好多网络协议的相关网站。页面渲染这部分知识点还有超多,但是精力有限,先写个理解性版本,后面再来查漏补缺。
学习理解了从URL到页面的过程,知道明白了也就对web性能优化有了个大概的认知。说白了web性能优化也是基于以上内容不断改进和避免一些错误做法,来达到性能优化的目的。所以趁热打铁下一篇博文就计划写web性能优化。现在时间6.8号凌晨32,现在正是高考时期,祝广大考生考试顺利。好了,退朝就寝!
此篇博文所参考的资源有:
http://blog.csdn.net/aishangyutian12/article/details/53133552
http://www.kuqin.com/shuoit/20170324/353413.html
http://www.cnblogs.com/kongxy/p/4615226.html
http://www.cnblogs.com/li0803/archive/2008/11/03/1324746.html
http://www.cnblogs.com/roverliang/p/5176456.html
http://blog.csdn.net/ithomer/article/details/5662524
感谢提供我借鉴图片的各位仁兄,如果有什么不可描述的事情,请告知我修改。
从输入url到浏览器显示页面的过程的更多相关文章
- 输入URL到浏览器显示页面的过程,搜集各方面资料总结一下
面试中经常会被问到这个问题吧,唉,我最开始被问到的时候也就能大概说一些流程.被问得多了,自己就想去找找这个问题的全面回答,于是乎搜了很多资料和网上的文章,根据那些文章写一个总结. 写得不好,或者有意见 ...
- 从输入URL到浏览器显示页面发生了哪些事情---个人理解
经典面试题:从输入URL到页面显示发生了哪些事情 以前一直都记不住,这次自己理解了一下 用自己的话总结了一次,不对的地方希望大佬给我指出来 1.主机通过DHCP协议获取客户端的IP地址.子网掩码和DN ...
- 从输入URL到浏览器显示页面发生了什么
1.输入网址 当你开始输入网址比如www.cnblogs.com时游览器就可以在书签或者历史记录里面去搜索相关的网址推荐给你. 2.游览器查找域名的IP地址 ① 请求发起后,游览器首先会解析这个域名, ...
- 从输入URL到浏览器显示页面
去看经典是不会错的,如果觉得太长,那就休息一下继续看. 经验告诉我,读一篇经典足矣,不要浪费时间去搜索其他地方到处复制粘贴的博文. 所以奉上我过滤的经典: 1.How browser work 2.h ...
- 输入url到渲染出页面的过程
输入地址 浏览器查找域名的 IP 地址 这一步包括 DNS 具体的查找过程,包括:浏览器缓存->系统缓存->路由器缓存... 浏览器向 web 服务器发送一个 HTTP 请求 服务器的永久 ...
- 在浏览器中输入 url 地址到显示主页的过程
总体来说分为以下几个过程:1. DNS 解析2. TCP 连接3. 发送 HTTP 请求4. 服务器处理请求并返回 HTTP 报文5. 浏览器解析渲染页面6. 连接结束
- 从输入 URL 到浏览器接收的过程中发生了什么事情
从输入 URL 到浏览器接收的过程中发生了什么事情? 原文:http://www.codeceo.com/article/url-cpu-broswer.html 从触屏到 CPU 首先是「输入 U ...
- 输入url后浏览器干了些什么(详解)
输入url后浏览器干了些什么(详解) DNS(Domain Name System, 域名系统) 解析 DNS解析的过程就是寻找哪台机器上有你真正需要的资源过程.但你在浏览器张红输入一个地址时,例如: ...
- 从输入 URL 到浏览器接收的过程中发生了什么事情?
从输入 URL 到浏览器接收的过程中发生了什么事情? What really happens when you navigate to a URL 上面两篇文章都解读的很好,值得阅读. 接下来在总结一 ...
随机推荐
- sbt is a build tool for Scala, Java, and more
http://www.scala-sbt.org/0.13/docs/index.html sbt is a build tool for Scala, Java, and more. It requ ...
- 手游服务器php架构比较
从swoole项目开始到现在,一直有人在问这个问题.今天来抽空讲一下它.为什么swoole非要使用纯C来写而不是PHP代码来实现,核心的原因有2点: 1. PHP无法直接调用操作系统API 如send ...
- hihoCoder 1578 Visiting Peking University 【贪心】 (ACM-ICPC国际大学生程序设计竞赛北京赛区(2017)网络赛)
#1578 : Visiting Peking University 时间限制:1000ms 单点时限:1000ms 内存限制:256MB 描述 Ming is going to travel for ...
- “There's no Qt version assigned to this project for platform ” - visual studio plugin for Qt
1.find menu "Qt VS Tools", select Qt Options 2.add a new Qt version 3. right click the tar ...
- 计算机学院大学生程序设计竞赛(2015’12)Happy Value
Happy Value Time Limit: 2000/1000 MS (Java/Others) Memory Limit: 32768/32768 K (Java/Others) Tota ...
- 跳转到AppStore 的不同位置办法
程序跳转到appstore中指定的应用 1.进入appstore中指定的应用NSString *str = [NSString stringWithFormat: ...
- java中的泛型类和泛型方法
1.泛型是什么? 泛型(Generic type 或者 generics)是对 Java 语言的类型系统的一种扩展,以支持创建可以按类型进行参数化的类. 可以在集合框架(Collection fram ...
- java中wait和notify
在JAVA中,是没有类似于PV操作.进程互斥等相关的方法的.JAVA的进程同步是通过synchronized()来实现的,需要说明的是,JAVA的synchronized()方法类似于操作系统概念中的 ...
- Linux Shell高级技巧(目录)
为了方便我们每个人的学习,这里将给出Linux Shell高级技巧五篇系列博客的目录以供大家在需要时参阅和查找. Linux Shell高级技巧(一) http://www.cnblogs.com/s ...
- npm 脚本
查看安装的包: npm list -g --depth 0 考虑到用CLI这种方式来运行本地的webpack不是特别方便,我们可以设置一个快捷方式,在package.json添加一个npm脚本(npm ...