聚类--K均值算法
import numpy as np
from sklearn.datasets import load_iris
iris = load_iris()
x = iris.data[:,1]
y = np.zeros(150) def initcenter(x,k): #初始聚类中心数组
return x[0:k].reshape(k) def nearest(kc,i): #数组中的值,与聚类中心最小距离所在类别的索引号
d = (abs(kc-i))
w = np.where(d == np.min(d))
return w[0][0] def xclassify(x,y,kc):
for i in range(x.shape[0]): #对数组的每个值进行分类,shape[0]读取矩阵第一维度的长度
y[i] = nearest(kc,x[i])
return y def kcmean(x,y,kc,k): #计算各聚类新均值
l = list(kc)
flag = False
for c in range(k):
print(c)
m = np.where(y == c)
n=np.mean(x[m])
if l[c] != n:
l[c] = n
flag = True #聚类中心发生变化
print(l,flag)
return (np.array(l),flag) k = 3
kc = initcenter(x,k) flag = True
print(x,y,kc,flag) #判断聚类中心和目标函数的值是否发生改变,若不变,则输出结果,若改变,则返回2
while flag:
y = xclassify(x,y,kc)
kc, flag = kcmean(x,y,kc,k)
print(y,kc,type(kc)) print(x,y)
import matplotlib.pyplot as plt
plt.scatter(x,x,c=y,s=50,cmap="rainbow");
plt.show()

x=np.random.randint(1,100,[20,1]) y=np.zeros(20) k=3 def initcenter(x,k): return x[:k] def nearest(kc,i): d = (abs(kc - i)) w = np.where(d ==np.min(d)) return w [0] [0] kc = initcenter(x,k) nearest(kc,14)

for i in range(x.shape[0]):
print(nearest(kc,x[i]))
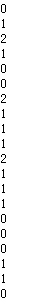
for i in range(x.shape[0]):
y[i] = nearest(kc,x[i])
print(y)
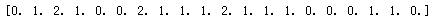
for i in range(x.shape[0]):
y[i]=nearest(kc,x[i])
print(y)
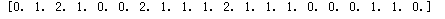
def initcenter(x,k):
return x[:k] def nearest(kc, i):
d = (abs(kc - 1))
w= np.where(d == np.min(d))
return w[0][0] def xclassify(x,y,kc):
for i in range(x.shape[0]):
y[i] = nearest(kc,x[i])
return y kc = initcenter(x,k)
nearest(kc,93)
m = np.where(y == 0)
np.mean(x[m])
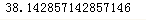
kc[0]=24
flag = True
import numpy as np
from sklearn.datasets import load_iris
iris = load_iris()
x = iris.data[:,1]
y = np.zeros(150) def nearest(kc,i): #初始聚类中心数组
return x[0:k] def nearest(kc,i): #数组中的值,与聚类中心最小距离所在类别的索引号
d = (abs(kc - i))
w = np.where(d == np.min(d))
return w[0][0] def kcmean(x, y, kc, k): #计算各聚类新均值
l =list(kc)
flag = False
for c in range(k):
m = np.where(y == c)
if m[0].shape != (0,):
n = np.mean(x[m])
if l[c] != n:
l[c] = n
flag = True #聚类中心发生改变
return (np.array(1),flag) def xclassify(x,y,kc):
for i in range(x.shape[0]): #对数组的每个值分类
y[i] = nearest(kc,x[i])
return y k = 3
kc = initcenter(x,k) falg = True
print(x, y, kc, flag)
while flag:
y = xclassify(x, y, kc)
xc, flag = kcmean(x, y, kc, k) print(y,kc)
import matplotlib.pyplot as plt
plt.scatter(x, x, c=y, s=50, cmap='rainbow',marker='p',alpha=0.5);
plt.show()
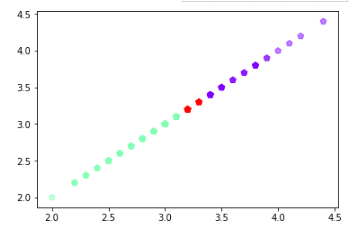
from sklearn.cluster import KMeans
import numpy as np
from sklearn.datasets import load_iris
import matplotlib.pyplot as plt
data = load_iris()
iris = data.data
petal_len = iris
print(petal_len)
k_means = KMeans(n_clusters=3) #三个聚类中心
result = k_means.fit(petal_len) #Kmeans自动分类
kc = result.cluster_centers_ #自动分类后的聚类中心
y_means = k_means.predict(petal_len) #预测Y值
plt.scatter(petal_len[:,0],petal_len[:,2],c=y_means, marker='p',cmap='rainbow')
plt.show()
聚类--K均值算法的更多相关文章
- 聚类--K均值算法:自主实现与sklearn.cluster.KMeans调用
1.用python实现K均值算法 import numpy as np x = np.random.randint(1,100,20)#产生的20个一到一百的随机整数 y = np.zeros(20) ...
- 第八次作业:聚类--K均值算法:自主实现与sklearn.cluster.KMeans调用
import numpy as np x = np.random.randint(1,100,[20,1]) y = np.zeros(20) k = 3 def initcenter(x,k): r ...
- 聚类算法:K-means 算法(k均值算法)
k-means算法: 第一步:选$K$个初始聚类中心,$z_1(1),z_2(1),\cdots,z_k(1)$,其中括号内的序号为寻找聚类中心的迭代运算的次序号. 聚类中心的向量值可任意设 ...
- 机器学习之K均值算法(K-means)聚类
K均值算法(K-means)聚类 [关键词]K个种子,均值 一.K-means算法原理 聚类的概念:一种无监督的学习,事先不知道类别,自动将相似的对象归到同一个簇中. K-Means算法是一种聚类分析 ...
- 一句话总结K均值算法
一句话总结K均值算法 核心:把样本分配到离它最近的类中心所属的类,类中心由属于这个类的所有样本确定. k均值算法是一种无监督的聚类算法.算法将每个样本分配到离它最近的那个类中心所代表的类,而类中心的确 ...
- 【机器学习】K均值算法(I)
K均值算法是一类非监督学习类,其可以通过观察样本的离散性来对样本进行分类. 例如,在对如下图所示的样本中进行聚类,则执行如下步骤 1:随机选取3个点作为聚类中心. 2:簇分配:遍历所有样本然后依据每个 ...
- Bisecting KMeans (二分K均值)算法讲解及实现
算法原理 由于传统的KMeans算法的聚类结果易受到初始聚类中心点选择的影响,因此在传统的KMeans算法的基础上进行算法改进,对初始中心点选取比较严格,各中心点的距离较远,这就避免了初始聚类中心会选 ...
- KMeans (K均值)算法讲解及实现
算法原理 KMeans算法是典型的基于距离的聚类算法,采用距离作为相似性的评价指标,即认为两个对象的距离越近,其相似度就越大.该算法认为簇是由距离靠近的对象组成的,因此把得到紧凑且独立的簇作为最终目标 ...
- 聚类分析K均值算法讲解
聚类分析及K均值算法讲解 吴裕雄 当今信息大爆炸时代,公司企业.教育科学.医疗卫生.社会民生等领域每天都在产生大量的结构多样的数据.产生数据的方式更是多种多样,如各类的:摄像头.传感器.报表.海量网络 ...
随机推荐
- spring boot+自定义 AOP 实现全局校验
最近公司重构项目,重构为最热的微服务框架 spring boot, 重构的时候遇到几个可以统一处理的问题,也是项目中经常遇到,列如:统一校验参数,统一捕获异常... 仅凭代码 去控制参数的校验,有时候 ...
- python第二天3.1
算数运算符arithmetic operator: + - * / % % : 取余,取模.取的是第一个操作数和第二个操作数除法的余数.整除结果为0. 10 % 3 1 10 ...
- 关于PHP5.6连接SqlServer
在做一个PHP报名系统的时候需要使用mssql来和winform结合起来使用, 但是发现我的php环境没有sqlsrv模块,于是乎,我就开始百度了 找到了微软官方下载地址,对照php版本,下载对应的模 ...
- Manjaro搭建无密访问samba服务器
为了方便Linux在Windows平台下开发,搭建Manjaro无密访问samba服务器 后面加了Windows下搭建samba方法 安装smb服务器 我用的是Manjaro gnome 18,需要安 ...
- VBoxManage安装
扩展包的版本需要与VirtualBox的版本一致,通过帮助可以查看VirtualBox的版本信息,然后在http://download.virtualbox.org/virtualbox/寻找对应的版 ...
- Http 状态码:
消息 100 Continue 101 Switching Protocols 102 Processing 成功 200 OK 201 Created 202 Accepted 203 Non-Au ...
- 亚马逊(Review、Feedback)差评怎么处理?
移除亚马逊Review差评,我看也就这三招靠谱点! 亚马逊特别重视review,差评会直接影响到listing的浏览量和销量,甚至还可以摧毁一个账号.遇到一个差的review怎么办?网上看到很多讲移除 ...
- 事务,mybatis
数据库事务:一件完整的事情, 要么全部成功,要么就全部失败 金典案例:转账 A给B转账:100 A:-100 B:+100 如何开启事务: Start transaction; 之前的转账操作(如果在 ...
- Python面向对象编程 -- 类和实例、访问限制
面向对象编程 Object Oriented Programming,简称OOP,是一种程序设计思想.OOP把对象作为程序的基本单元,一个对象包含了数据和操作数据的函数. 面向过程的程序设计把计算机程 ...
- ArcGIS中删除“点”附带的对应“文本信息”
现状: 用ArcMap打开对应的.mxd文件,导入KML数据后,几何类型“点” - 每一个点都附带对应的文本信息“Placemark”,如下图: 问题:ArcGIS中如何 删除“点”附带的对应“文本信 ...