聚类--K均值算法
import numpy as np
from sklearn.datasets import load_iris
iris = load_iris()
x = iris.data[:,1]
y = np.zeros(150) def initcenter(x,k): #初始聚类中心数组
return x[0:k].reshape(k) def nearest(kc,i): #数组中的值,与聚类中心最小距离所在类别的索引号
d = (abs(kc-i))
w = np.where(d == np.min(d))
return w[0][0] def xclassify(x,y,kc):
for i in range(x.shape[0]): #对数组的每个值进行分类,shape[0]读取矩阵第一维度的长度
y[i] = nearest(kc,x[i])
return y def kcmean(x,y,kc,k): #计算各聚类新均值
l = list(kc)
flag = False
for c in range(k):
print(c)
m = np.where(y == c)
n=np.mean(x[m])
if l[c] != n:
l[c] = n
flag = True #聚类中心发生变化
print(l,flag)
return (np.array(l),flag) k = 3
kc = initcenter(x,k) flag = True
print(x,y,kc,flag) #判断聚类中心和目标函数的值是否发生改变,若不变,则输出结果,若改变,则返回2
while flag:
y = xclassify(x,y,kc)
kc, flag = kcmean(x,y,kc,k)
print(y,kc,type(kc)) print(x,y)
import matplotlib.pyplot as plt
plt.scatter(x,x,c=y,s=50,cmap="rainbow");
plt.show()

x=np.random.randint(1,100,[20,1]) y=np.zeros(20) k=3 def initcenter(x,k): return x[:k] def nearest(kc,i): d = (abs(kc - i)) w = np.where(d ==np.min(d)) return w [0] [0] kc = initcenter(x,k) nearest(kc,14)

for i in range(x.shape[0]):
print(nearest(kc,x[i]))
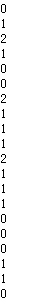
for i in range(x.shape[0]):
y[i] = nearest(kc,x[i])
print(y)
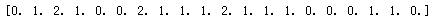
for i in range(x.shape[0]):
y[i]=nearest(kc,x[i])
print(y)
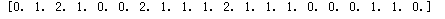
def initcenter(x,k):
return x[:k] def nearest(kc, i):
d = (abs(kc - 1))
w= np.where(d == np.min(d))
return w[0][0] def xclassify(x,y,kc):
for i in range(x.shape[0]):
y[i] = nearest(kc,x[i])
return y kc = initcenter(x,k)
nearest(kc,93)
m = np.where(y == 0)
np.mean(x[m])
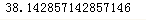
kc[0]=24
flag = True
import numpy as np
from sklearn.datasets import load_iris
iris = load_iris()
x = iris.data[:,1]
y = np.zeros(150) def nearest(kc,i): #初始聚类中心数组
return x[0:k] def nearest(kc,i): #数组中的值,与聚类中心最小距离所在类别的索引号
d = (abs(kc - i))
w = np.where(d == np.min(d))
return w[0][0] def kcmean(x, y, kc, k): #计算各聚类新均值
l =list(kc)
flag = False
for c in range(k):
m = np.where(y == c)
if m[0].shape != (0,):
n = np.mean(x[m])
if l[c] != n:
l[c] = n
flag = True #聚类中心发生改变
return (np.array(1),flag) def xclassify(x,y,kc):
for i in range(x.shape[0]): #对数组的每个值分类
y[i] = nearest(kc,x[i])
return y k = 3
kc = initcenter(x,k) falg = True
print(x, y, kc, flag)
while flag:
y = xclassify(x, y, kc)
xc, flag = kcmean(x, y, kc, k) print(y,kc)
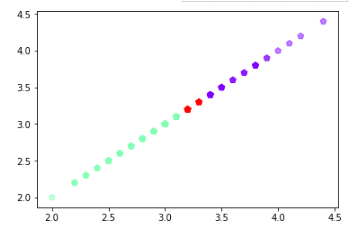
import matplotlib.pyplot as plt
plt.scatter(x, x, c=y, s=50, cmap='rainbow',marker='p',alpha=0.5);
plt.show()
from sklearn.cluster import KMeans
import numpy as np
from sklearn.datasets import load_iris
import matplotlib.pyplot as plt
data = load_iris()
iris = data.data
petal_len = iris
print(petal_len)
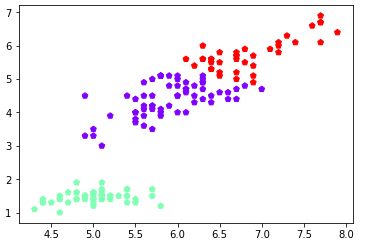
k_means = KMeans(n_clusters=3) #三个聚类中心
result = k_means.fit(petal_len) #Kmeans自动分类
kc = result.cluster_centers_ #自动分类后的聚类中心
y_means = k_means.predict(petal_len) #预测Y值
plt.scatter(petal_len[:,0],petal_len[:,2],c=y_means, marker='p',cmap='rainbow')
plt.show()
聚类--K均值算法的更多相关文章
- 聚类--K均值算法:自主实现与sklearn.cluster.KMeans调用
1.用python实现K均值算法 import numpy as np x = np.random.randint(1,100,20)#产生的20个一到一百的随机整数 y = np.zeros(20) ...
- 第八次作业:聚类--K均值算法:自主实现与sklearn.cluster.KMeans调用
import numpy as np x = np.random.randint(1,100,[20,1]) y = np.zeros(20) k = 3 def initcenter(x,k): r ...
- 聚类算法:K-means 算法(k均值算法)
k-means算法: 第一步:选$K$个初始聚类中心,$z_1(1),z_2(1),\cdots,z_k(1)$,其中括号内的序号为寻找聚类中心的迭代运算的次序号. 聚类中心的向量值可任意设 ...
- 机器学习之K均值算法(K-means)聚类
K均值算法(K-means)聚类 [关键词]K个种子,均值 一.K-means算法原理 聚类的概念:一种无监督的学习,事先不知道类别,自动将相似的对象归到同一个簇中. K-Means算法是一种聚类分析 ...
- 一句话总结K均值算法
一句话总结K均值算法 核心:把样本分配到离它最近的类中心所属的类,类中心由属于这个类的所有样本确定. k均值算法是一种无监督的聚类算法.算法将每个样本分配到离它最近的那个类中心所代表的类,而类中心的确 ...
- 【机器学习】K均值算法(I)
K均值算法是一类非监督学习类,其可以通过观察样本的离散性来对样本进行分类. 例如,在对如下图所示的样本中进行聚类,则执行如下步骤 1:随机选取3个点作为聚类中心. 2:簇分配:遍历所有样本然后依据每个 ...
- Bisecting KMeans (二分K均值)算法讲解及实现
算法原理 由于传统的KMeans算法的聚类结果易受到初始聚类中心点选择的影响,因此在传统的KMeans算法的基础上进行算法改进,对初始中心点选取比较严格,各中心点的距离较远,这就避免了初始聚类中心会选 ...
- KMeans (K均值)算法讲解及实现
算法原理 KMeans算法是典型的基于距离的聚类算法,采用距离作为相似性的评价指标,即认为两个对象的距离越近,其相似度就越大.该算法认为簇是由距离靠近的对象组成的,因此把得到紧凑且独立的簇作为最终目标 ...
- 聚类分析K均值算法讲解
聚类分析及K均值算法讲解 吴裕雄 当今信息大爆炸时代,公司企业.教育科学.医疗卫生.社会民生等领域每天都在产生大量的结构多样的数据.产生数据的方式更是多种多样,如各类的:摄像头.传感器.报表.海量网络 ...
随机推荐
- 毕业设计 Makefile 编写
一天下来,Makefile终于完成了,可以实现c文件和头文件不同目录,并将输出文件输出到其他如output目录,将执行文件和makefile文件并列: 源码如下: # ================ ...
- 论文笔记:Towards Diverse and Natural Image Descriptions via a Conditional GAN
论文笔记:Towards Diverse and Natural Image Descriptions via a Conditional GAN ICCV 2017 Paper: http://op ...
- flask No such command "init-db".
在Daily目录下,使用cmd窗口执行,不要使用IDE的命令行 set FLASK_APP=DLY set FLASK_ENV=development flask init_app
- 补充资料——自己实现极大似然估计(最大似然估计)MLE
这篇文章给了我一个启发,我们可以自己用已知分布的密度函数进行组合,然后构建一个新的密度函数啦,然后用极大似然估计MLE进行估计. 代码和结果演示 代码: #取出MASS包这中的数据 data(geys ...
- 给video添加自定义进度条
思路: 1.进度条,首先要知道视频的总长度,和视频的当前进度,与其对应的便是进度条的总长度和当前的长度,两者比值相等 2.获取视频的总长度(单位是秒),获取当前进度 3.要实现的功能,首先是进度条根据 ...
- 第 8 章 容器网络 - 072 - 一文搞懂各种 Docker 网络
Docker 起初只提供了简单的 single-host 网络,显然这不利于 Docker 构建容器集群并通过 scale-out 方式横向扩展到多个主机上. 跨主机网络方案: Docker Over ...
- iview table 实现在数据中自定义标识
做了一个商旅订票的项目,在详情中有一个因公超标在表格中用一个“超”字显示的需求.后台框架用的iview+vue,也就是在iview Table中改变.在iview的框架中改变东西首先要想到的是ivie ...
- scrapy数据存储在mysql数据库的两种方式
方法一:同步操作 1.pipelines.py文件(处理数据的python文件) import pymysql class LvyouPipeline(object): def __init__(se ...
- OR,RR,HR 临床分析应用中的差别 对照组暴露比值b/d
1.相对危险度(relative risk,RR).指暴露于某因素发生某事件的风险,即A/(A+B),除以未暴露人群发生的该事件的风险,即C/(C+D),所得的比值,即RR=[A/(A+B)]/[C/ ...
- leetcode 703数据流中的第K大元素
这里思路是堆排序,而且是小根堆.C++中包含在头文件<queue>的priority_queue本质就是堆排序实现的.其中priority_queue函数原型是 priority_queu ...