Lucene 03 - 什么是分词器 + 使用IK中文分词器
1 分词器概述
1.1 分词器简介
在对文档(Document)中的内容进行索引前, 需要对域(Field)中的内容使用分析对象(分词器)进行分词.
**分词的目的是为了索引, 索引的目的是为了搜索. **
- 分词的过程是 先分词, 再过滤:
- 分词: 将Document中Field域的值切分成一个一个的单词. 具体的切分方法(算法)由具体使用的分词器内部实现.
- 过滤: 去除标点符号,去除停用词(的、是、is、the、a等), 词的大写转为小写.
- 分词流程图:

- 停用词说明:
停用词是指为了节省存储空间和提高搜索效率, 搜索引擎在索引内容或处理搜索请求时会自动忽略的字词, 这些字或词被称为"stop words". 如语气助词、副词、介词、连接词等, 通常自身没有明确的含义, 只有放在一个上下文语句中才有意义(如:的、在、啊, is、a等).
例如:
原始文档内容:Lucene is a Java full-text search engine
分析以后的词:lucene java full text search engine
1.2 分词器的使用
(1) 索引流程使用
流程: 把原始数据转换成文档对象(Document), 再使用分词器将文档域(Field)的内容切分成一个一个的词语.
目的: 方便后续建立索引.
(2) 检索流程使用
流程: 根据用户输入的查询关键词, 使用分词器将关键词进行分词以后, 建立查询对象(Query), 再执行搜索.
注意: 索引流程和检索流程使用的分词器, 必须统一.
1.3 中文分词器
1.3.1 中文分词器简介
英文本身是以单词为单位, 单词与单词之间, 句子之间通常是空格、逗号、句号分隔. 因而对于英文, 可以简单的以空格来判断某个字符串是否是一个词, 比如: I love China, love和China很容易被程序处理.
但是中文是以字为单位的, 字与字再组成词, 词再组成句子. 中文: 我爱中国, 电脑不知道“爱中”是一个词, 还是“中国”是一个词?所以我们需要一定的规则来告诉电脑应该怎么切分, 这就是中文分词器所要解决的问题.
常见的有一元切分法“我爱中国”: 我、爱、中、国. 二元切分法“我爱中国”: 我爱、爱中、中国.
1.3.2 Lucene提供的中文分词器
StandardAnalyzer分词器: 单字分词器: 一个字切分成一个词, 一元切分法.CJKAnalyzer分词器: 二元切分法: 把相邻的两个字, 作为一个词.SmartChineseAnalyzer分词器: 通常一元切分法, 二元切分法都不能满足我们的业务需求. 而SmartChineseAnalyzer对中文支持较好, 但是扩展性差, 针对扩展词库、停用词均不好处理.
**说明: Lucene提供的中文分词器, 只做了解, 企业项目中不推荐使用. **
1.3.3 第三方中文分词器
paoding: 庖丁解牛分词器, 可在https://code.google.com/p/paoding/下载. 没有持续更新, 只支持到lucene3.0, 项目中不予以考虑使用.mmseg4j: 最新版已从https://code.google.com/p/mmseg4j/移至https://github.com/chenlb/mmseg4j-solr. 支持Lucene4.10, 且在github中有持续更新, 使用的是mmseg算法.IK-analyzer: 最新版在https://code.google.com/p/ik-analyzer/上, 支持Lucene 4.10. 从2006年12月推出1.0版开始, IKAnalyzer已经推出了4个大版本. 最初是以开源项目Luence为应用主体的, 结合词典分词和文法分析算法的中文分词组件. 从3.0版本开始, IK发展为面向Java的公用分词组件, 独立于Lucene项目, 同时提供了对Lucene的默认优化实现. **适合在项目中应用. **
2 IK分词器的使用
说明: 由于IK分词器是对Lucene分词器的扩展实现, 使用IK分词器与使用Lucene分词器是一样的.
2.1 配置pom.xml文件, 加入IK分词器的依赖
<project>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<!-- mysql版本 -->
<mysql.version>5.1.44</mysql.version>
<!-- lucene版本 -->
<lucene.version>4.10.4</lucene.version>
<!-- ik分词器版本 -->
<ik.version>2012_u6</ik.version>
</properties>
<dependencies>
<!-- ik分词器 -->
<dependency>
<groupId>com.janeluo</groupId>
<artifactId>ikanalyzer</artifactId>
<version>${ik.version}</version>
</dependency>
</dependencies>
</project>
2.2 修改索引流程的分词器

2.3 修改检索流程的分词器

2.4 重新创建索引
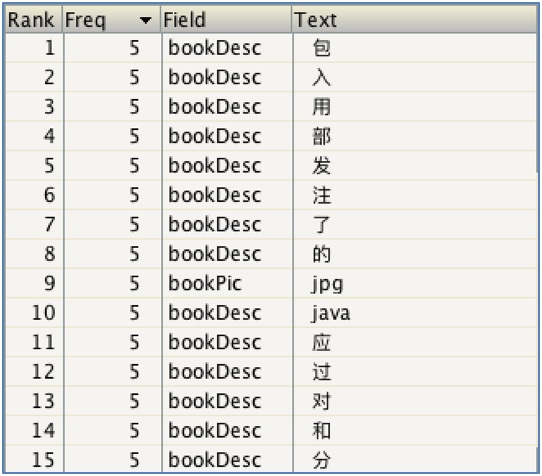
使用Lucene默认的标准分词器(一元分词器):
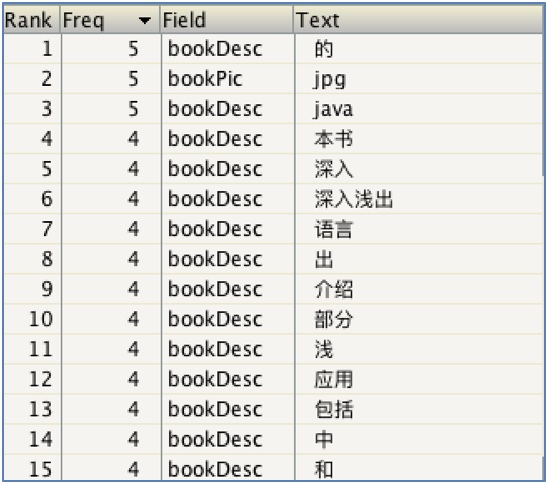
使用ik分词器之后(对中文分词支持较好):
3 扩展中文词库
说明: 企业开发中, 随着业务的发展, 会产生一些新的词语不需要分词, 而需要作为整体匹配, 如: 尬聊, 戏精, 蓝瘦香菇; 也可能有一些词语会过时, 需要停用.
-- 通过配置文件来实现.
3.1 加入IK分词器的配置文件
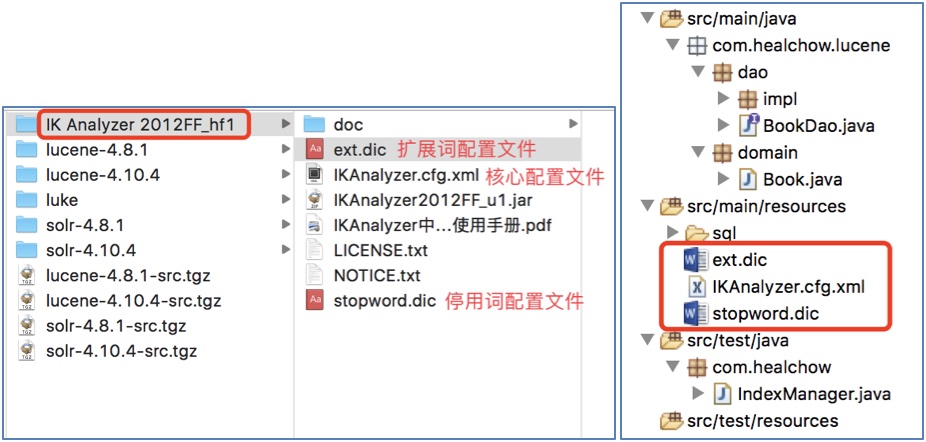
说明: 这些配置文件需要放到类的根路径下.
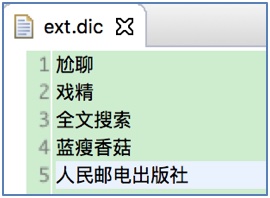
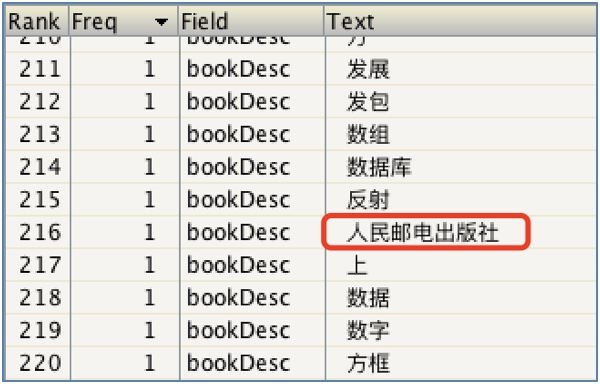
3.2 增加扩展词演示(扩展: 人民邮电出版社)
说明: 在ext.dic文件中增加"人民邮电出版社":
注意: 不要使用Windows自带的记事本或Word, 因为这些程序会在文件中加入一些标记符号(bom, byte order market), 导致配置文件不能被识别.
增加扩展词之后:
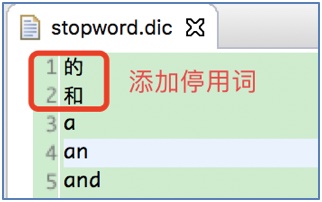
3.3 增加停用词演示(增加: 的、和)
在stopword.dic文件增加停用词(的、和):
增加停用词之前:
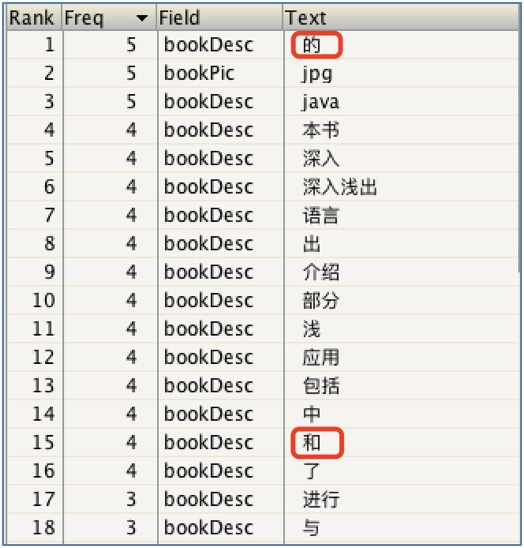
增加停用词之后:

注意事项:
修改扩展词配置文件ext.dic和停用词配置文件stopword.dic, 不能使用Windows自带的记事本程序修改, 否则修改以后不生效: 记事本程序会增加一些bom符号.
推荐使用Emacs, Vim, Sublime等编辑器修改.
版权声明
作者: 马瘦风
出处: 博客园 马瘦风的博客
您的支持是对博主的极大鼓励, 感谢您的阅读.
本文版权归博主所有, 欢迎转载, 但请保留此段声明, 并在文章页面明显位置给出原文链接, 否则博主保留追究相关人员法律责任的权利.
Lucene 03 - 什么是分词器 + 使用IK中文分词器的更多相关文章
- ES[7.6.x]学习笔记(七)IK中文分词器
在上一节中,我们给大家介绍了ES的分析器,我相信大家对ES的全文搜索已经有了深刻的印象.分析器包含3个部分:字符过滤器.分词器.分词过滤器.在上一节的例子,大家发现了,都是英文的例子,是吧?因为ES是 ...
- Solr学习笔记之2、集成IK中文分词器
Solr学习笔记之2.集成IK中文分词器 一.下载IK中文分词器 IK中文分词器 此文IK版本:IK Analyer 2012-FF hotfix 1 完整分发包 二.在Solr中集成IK中文分词器 ...
- Lucene系列四:Lucene提供的分词器、IKAnalyze中文分词器集成、扩展 IKAnalyzer的停用词和新词
一.Lucene提供的分词器StandardAnalyzer和SmartChineseAnalyzer 1.新建一个测试Lucene提供的分词器的maven项目LuceneAnalyzer 2. 在p ...
- 搜索引擎ElasticSearch系列(五): ElasticSearch2.4.4 IK中文分词器插件安装
一:IK分词器简介 IK Analyzer是一个开源的,基于java语言开发的轻量级的中文分词工具包.从2006年12月推出1.0版开始, IKAnalyzer已经推出了4个大版本.最初,它是以开源 ...
- Solr6.6.0添加IK中文分词器
IK分词器就是一款中国人开发的,扩展性很好的中文分词器,它支持扩展词库,可以自己定制分词项,这对中文分词无疑是友好的. jar包下载链接:http://pan.baidu.com/s/1o85I15o ...
- Solr7.2.1环境搭建和配置ik中文分词器
solr7.2.1环境搭建和配置ik中文分词器 安装环境:Jdk 1.8. windows 10 安装包准备: solr 各种版本集合下载:http://archive.apache.org/dist ...
- 真分布式SolrCloud+Zookeeper+tomcat搭建、索引Mysql数据库、IK中文分词器配置以及web项目中solr的应用(1)
版权声明:本文为博主原创文章,转载请注明本文地址.http://www.cnblogs.com/o0Iris0o/p/5813856.html 内容介绍: 真分布式SolrCloud+Zookeepe ...
- 对本地Solr服务器添加IK中文分词器实现全文检索功能
在上一篇随笔中我们提到schema.xml中<field/>元素标签的配置,该标签中有四个属性,分别是name.type.indexed与stored,这篇随笔将讲述通过设置type属性的 ...
- Kafka:ZK+Kafka+Spark Streaming集群环境搭建(十九)ES6.2.2 安装Ik中文分词器
注: elasticsearch 版本6.2.2 1)集群模式,则每个节点都需要安装ik分词,安装插件完毕后需要重启服务,创建mapping前如果有机器未安装分词,则可能该索引可能为RED,需要删除后 ...
随机推荐
- Python ftplib模块
Python ftplib模块 官方文档:https://docs.python.org/3/library/ftplib.html?highlight=ftplib#module-ftplib 实例 ...
- Spring Cloud微服务笔记(二)Spring Cloud 简介
Spring Cloud 简介 Spring Cloud的设计理念是Integrate Everything,即充分利用现有的开源组件, 在它们之上设计一套统一的规范/接口使它们能够接入Spring ...
- UI分层中使用PageFactory
基于原PO设计模式,需要改变原有的从文件中读取文件,更改为PageFactory模式.做出如下改动: 1 2 public MsysPage(DriverBase driver) { super(dr ...
- 第k个素因子只有3 5 7 的数
题目描述 有一些数的素因子只有3.5.7,请设计一个算法,找出其中的第k个数. 给定一个数int k,请返回第k个数.保证k小于等于100. 测试样例: 3 返回:7 int findKth(int ...
- Day2----《Pattern Recognition and Machine Learning》Christopher M. Bishop
用一个例子来讲述regression. 采用sin(2*pi*x)加入微弱的正态分布噪声的方式来获得一些数据,然后用多项式模型来进行拟合. 在评价模型的准确性时,采用了误差函数的方式,用根均方误差的方 ...
- NOIP2006普及组 Jam的计数法
普及组重要的模拟题.附上题目链接 https://www.luogu.org/problem/show?pid=1061 (写水题题解算是巩固提醒自己细心吧qwq) 样例输入: bdfij 样例输出: ...
- summary of week
Summary of week Catalog 计算机基础 解释器 编码 数据类型 输入 输出 变量 注释 运算符 条件判断 循环 Content 计算机基础 计算机组成 软件 解释器 操作系统 : ...
- python学习:利用循环语句完善输入设置
利用循环语句完善输入设置 使用for循环: 代码1:_user = "alex"_password = "abc123" for i in range(3): ...
- 关于实体类getset方法首字母小写问题
实体类:private Date cDateTime;private String cNickname; public Date getcDateTime() { return cDateTime;} ...
- Mesos源码分析(4) Mesos Master的启动之三
3. ModuleManager::load(flags.modules.get())如果有参数--modules或者--modules_dir=dirpath,则会将路径中的so文件load进来 ...