filebeat+Elk实现日志收集并使用kibana展示
工作流程图
通过Filegeat收集日志,将日志的数据推送到kafka然后通过logstash去消费发送到Es,再通过索引的方式将数据用kibana进行展示;
1、部署测试机器规划
| ip | logstash 版本 | es,kibana,logstash 版本 | filbeat 版本 | kafka |
| 192.168.113.130 | V7.16.2 | V7.16.2(es,logstash,Filegeat) | V7.16.2 | V3.0.1 |
| 192.168.113.131 | V7.16.2 | V7.16.2(es) | V7.16.2 | V3.0.1 |
| 192.168.113.132 | V7.16.2 | V7.16.2(es,kibana) | V7.16.2 | V3.0.1 |
2、部署kafka请参考文章centos-7部署kafka-v2.13.3.0.1集群
创建一个topic用于测试fibeat发送nginx日志消息到kafka并让logstash消费
[root@localhost bin]# ./kafka-topics.sh --create --replication-factor 1 --partitions 2 --topic nginx-log --bootstrap-server 192.168.113.130:9092查看创建好的topic以及副本数跟分区
[root@localhost kafka]# ./bin/kafka-topics.sh --describe --topic nginx-log --bootstrap-server 192.168.113.130:9092查看当前所有topic
[root@localhost kafka]# ./bin/kafka-topics.sh --bootstrap-server 192.168.113.130:9092 --list查看组
[root@localhost kafka]# ./bin/kafka-consumer-groups.sh --bootstrap-server 192.168.113.130:9092 --list查看组下面的topic的消费情况
[root@localhost kafka]# ./bin/kafka-consumer-groups.sh --bootstrap-server 192.168.113.130:9092 --describe --group +组名3、部署Elasticsearch请参考文档centos7部署elasticsearch-7.16.2分布式集群
4、安装部署kibana
规划:把kibana单机安装在192.168.113.132上面
下载相应版本的kibana并解压
wget https://artifacts.elastic.co/downloads/kibana/kibana-7.16.2-linux-x86_64.tar.gz
tar xf kibana-7.16.2-linux-x86_64修改配置文件
[root@localhost opt]# mv kibana-7.16.2-linux-x86_64 kafka && cd kibana
[root@localhost kibana]# vim config/kibana.yml
如果配置了nginx代理还需要配置server.publicBaseUrl: "http://nginx地址"
如果配置了ES安全认证需要在配置里面加上连接ES的账号跟密码

后台启动kibana(跟es一样不能使用root账号启动,这里我就使用启动es的账号去启动kibana)
[root@localhost kibana]# chown -R es:es ../kibana/
[root@localhost kibana]# su es
[es@localhost kibana]$ nohup /opt/kibana/bin/kibana 1> /dev/null 2>&1 &访问kibana,如果加了认证使用elastic账号进行登录
安装单机logstash(192.168.113.130)测试
下载logstash
[root@localhost opt]# wget https://artifacts.elastic.co/downloads/logstash/logstash-7.16.2-linux-x86_64.tar.gz
[root@localhost opt]# tar xf logstash-7.16.2
[root@localhost opt]# mv logstash-7.16.2 logstash && cd logstash/创建一个测试logstash配置文件
[root@localhost logstash]# tash]# vim config/logstash-nginx.confinput {
stdin { }
}
output {
kafka {
bootstrap_servers => "192.168.113.130:9092,192.168.113.131:9092,192.168.113.130:9092"
topic_id => "nginx-log"
}
}
input {
kafka {
bootstrap_servers => "192.168.113.130:9092,192.168.113.131:9092,192.168.113.130:9092"
client_id => "test"
auto_offset_reset => "latest"
topics => ["nginx-log"]
decorate_events => true
consumer_threads => 5
}
}
filter {
grok {
match => {"message" => "%{LOGLEVEL:log_level}"}
}
}
output {
elasticsearch {
hosts => ["192.168.113.130:9200","192.168.113.131:9200","192.168.113.132:9200"]
#user => "elastic" #如果开启了认证需要配置这项
#password => "密码"
index => "nginx-log-%{+YYYY.MM.dd}"
}
#stdout{
# codec => rubydebug
#}
}后台启动logstash
[root@localhost logstash]# /opt/logstash/bin/logstash -f /opt/logstash/config/logstash-nginx.conf 1 > /dev/null 2>&1 &在192.168.113.130上面简单安装一个nginx并配置filebeat推送日志
安装ningx
[root@localhost ~]# yum -y epel-release #安装第三方源
[root@localhost ~]# yum install nginx -y
[root@localhost ~]# systemctl start nginx安装并配置filebeat
[root@localhost opt]# wget https://artifacts.elastic.co/downloads/beats/filebeat/filebeat-7.16.2-linux-x86_64.tar.gz
[root@localhost opt]# tar xf filebeat-7.16.2-linux-x86_64.tar.gz
[root@localhost opt]# mv filebeat-7.16.2-linux-x86_64 filebeat && cd filebeat修改配置文件
[root@localhost filebeat]# vim filebeat.yml
filebeat.inputs:
setup.template.settings:
index.number_of_shards: 3
filebeat.config.modules:
path: ${path.config}/modules.d/*.yml
reload.enabled: false
#processors:
#- drop_fields:
# fields: ["beat","input","source","offset","topicname","timestamp","@metadata","%{host}"]
output.kafka:
hosts: ["192.168.113.130:9092","192.168.113.131:9092","192.168.113.132:9092"]
max_message_bytes: 10000000
topic: nginx-log #前面创建的topic配置nginx日志规则
[root@localhost filebeat]# vim modules.d/nginx.yml
- module: nginx
access:
var.paths: ["/var/log/nginx/*access.log"]
enabled: true
error:
var.paths: ["/var/log/nginx/*error.log"]
enabled: true
ingress_controller:
enabled: false后台运行filebeat
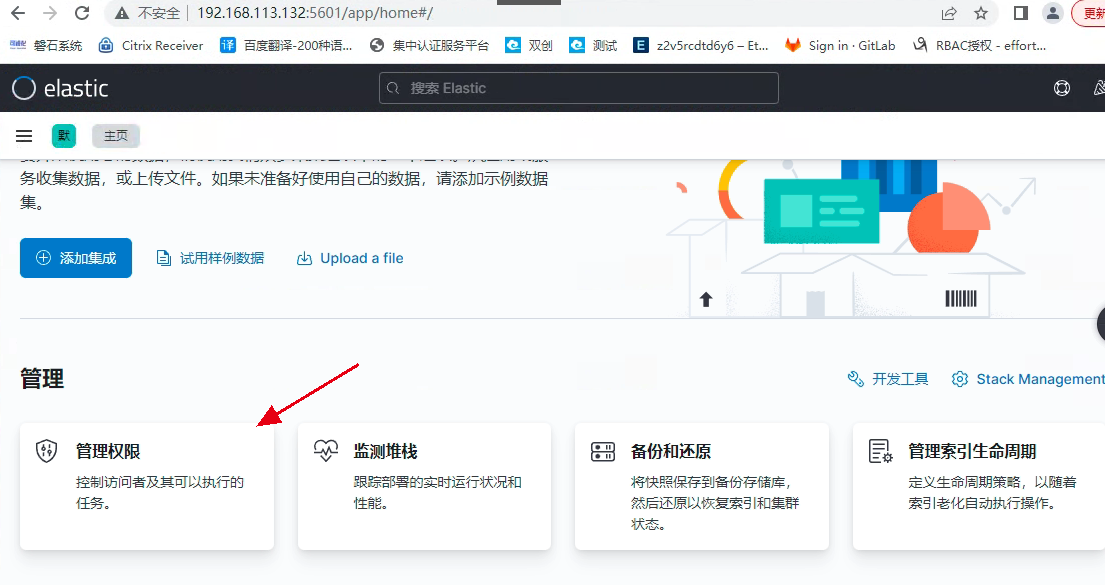
[root@localhost filebeat]# nohup /opt/filebeat/filebeat -e -c /opt/filebeat/filebeat.yml 1 > /dev/null 2>&1 &访问kibana进入权限管理并添加相应的es索引
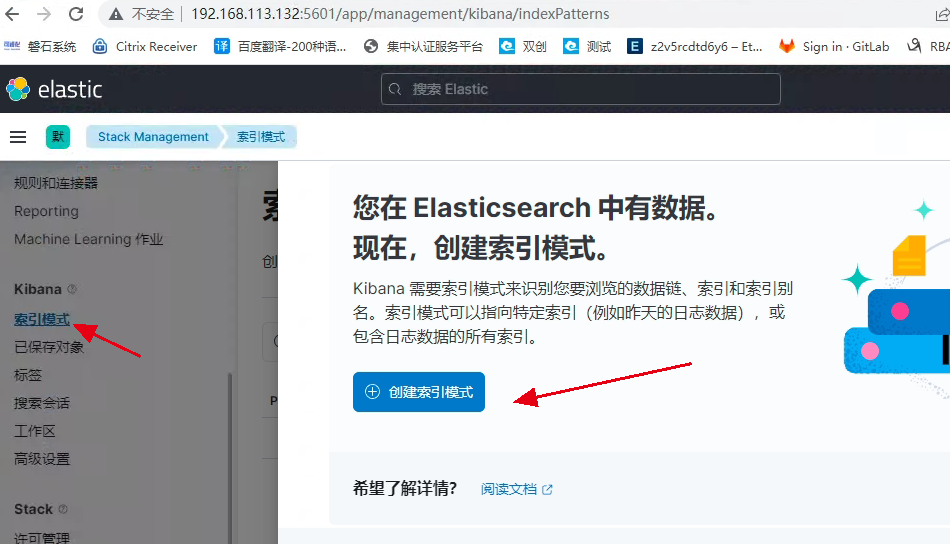
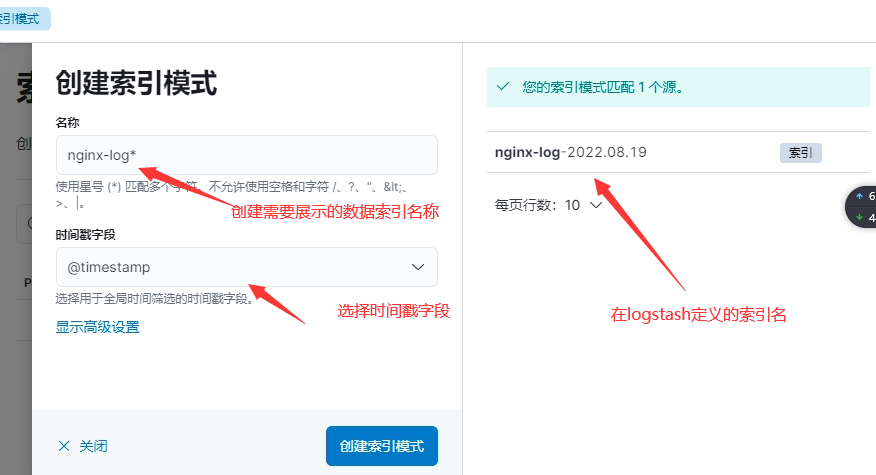
查看创建好的
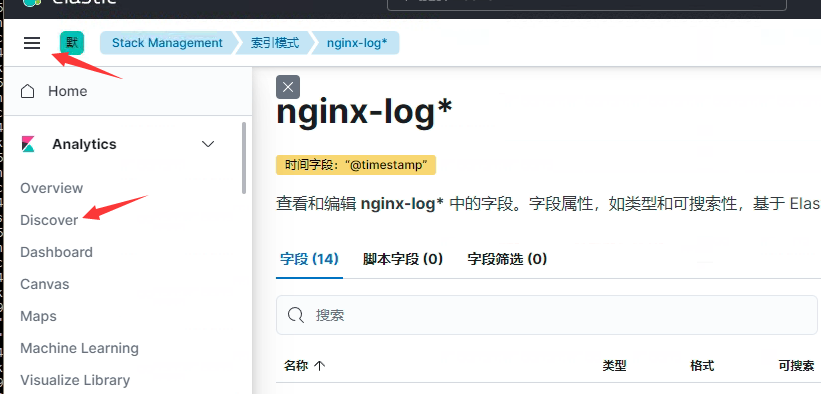
这里日志的数据就展示出来了
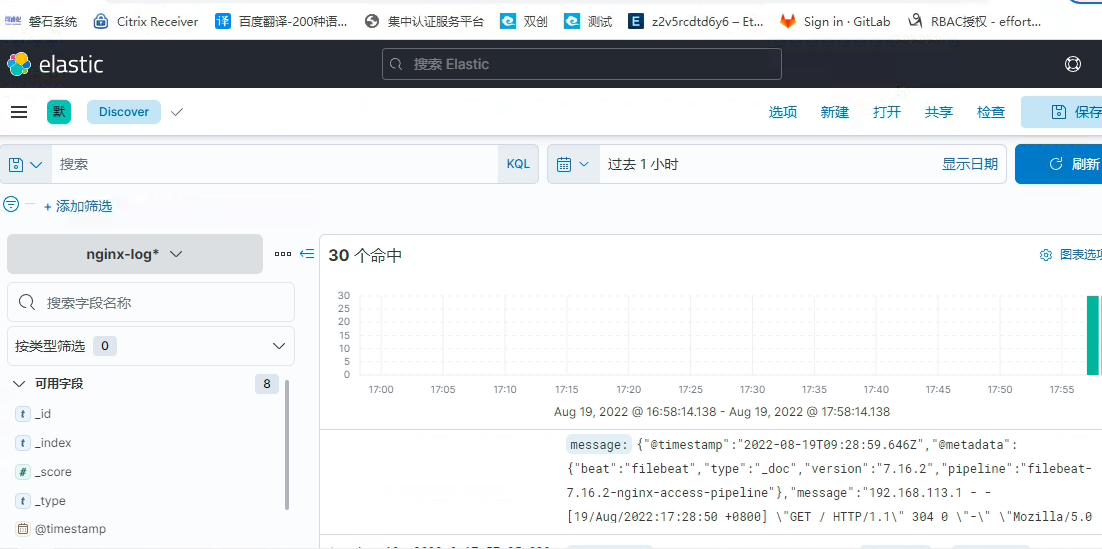
查看es上面索引的数据一切正常
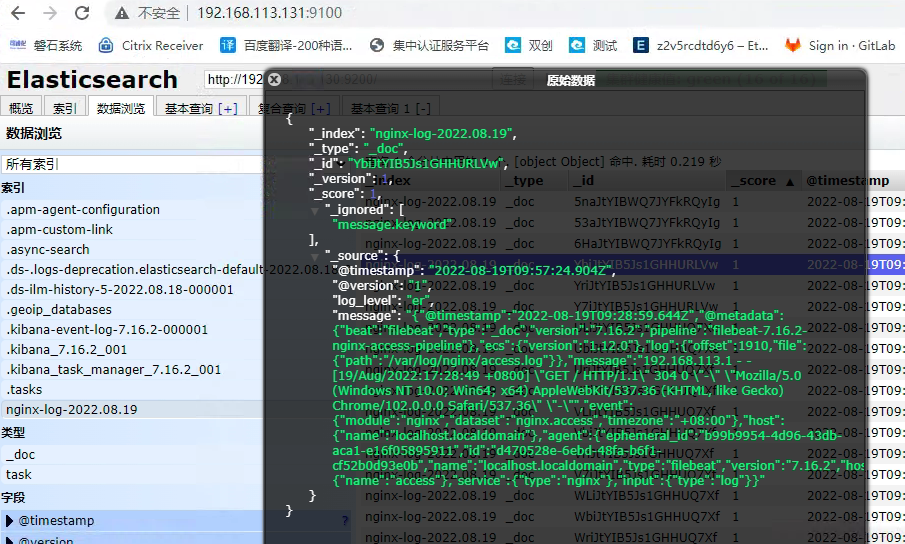
总结,需要推送其他的日志数据只需要在日志所在的服务器配置相应的filebeat就可以了
配置logstash将多个从filebeat将日志数据推送到kafka的多个topic案例
filebeat可以同上面的nginx配置同理,如果是微服务将filebeat继承到容器里面就可以
编辑logstash配置文件
vim /opt/logstash/conf/logstash.conf (这里是新弄的一个测试配置,如果nginx还需要将这个配置添加到nginx的那个配置文件就行)
input{
kafka{
bootstrap_servers => "192.168.113.129:9002,192.168.113.130:9002,192.168.113.131:9002"
codec => "json"
client_id => "test1"
group_id => "test" //会将这个topic加入到这个组,如果没有启动logstash后会自动创建
auto_offset_reset => "latest" //从最新的偏移量开始消费
consumer_threads => 5
decorate_events => true //此属性会将当前topic、offset、group、partition等信息也带到message中
topics => ["test1"] //数组类型,可配置多个topic以逗号隔开:例 ["test1","test2"]如果kafka里面没有这个topic会自动创建,默认一个partitions
type => "test" //所有插件通用属性,尤其在input里面配置多个数据源时很有用
}
kafka{
bootstrap_servers => "192.168.113.129:9002,192.168.113.130:9002,192.168.113.131:9002"
codec => "json"
client_id => "test2"
group_id => "test"
auto_offset_reset => "latest"
consumer_threads => 5
decorate_events => true
topics => ["test2"]
type => "sms"
}
}
filter {
ruby {
code => "event.timestamp.time.localtime"
}
mutate {
remove_field => ["beat"]
}
grok {
match => {"message" => "[(?<time>d+-d+-d+sd+:d+:d+)] [(?<level>w+)] (?<thread>[w|-]+) (?<class>[w|.]+) (?<lineNum>d+):(?<msg>.+)"}
}
}
output {
if[type] == "test"{
elasticsearch{
hosts => ["192.168.113.129:9200,192.168.113.130:9200,192.168.113.131:9200"]
#user => "elastic"
#password => "密码" #开启了认证的需要配置这项
index => "test1-%{+YYYY-MM-dd}"
}
}
if[type] == "sms"{
elasticsearch{
hosts => ["192.168.113.129:9200,192.168.113.130:9200,192.168.113.131:9200"]
#user => "elastic"
#password => "密码"
index => "test2-%{+YYYY-MM-dd}"
}
}
stdout {
codec => rubydebug
}
}metricbeat 7.16.2实现主机和kafka应用指标监控
在一台机器上做测试,如果开启kafka监控在一台上面开启kafka监控就可以了,其它部署启动监控主机指标就好
1. 下载metricbeat地址
wget https://artifacts.elastic.co/downloads/beats/metricbeat/metricbeat-7.16.2-linux-x86_64.tar.gz2. 配置文件metricbeat.yml
该配置文件中,可以配置elasticsearch参数,如果都是按默认配置部署,可以不做修改。如果使用了安全认证开启用户和密码认证配置
output.elasticsearch:
# Array of hosts to connect to.
hosts: ["192.168.113.129:9200","192.168.113.130:9200","192.168.113.131:9200"]3. 开启kafka指标
执行命令:
./metricbeat modules enable kafka在modules.d/kafka.yml中进行kafka相关配置
- module: kafka
#metricsets:
# - partition
# - consumergroup
period: 10s
hosts: ["192.168.113.129:9092","192.168.113.130:9092","192.168.113.131:9092"]执行初始化并启动
# 初始化模板
./metricbeat setup --dashboards
# 查看启用的模块
./metricbeat modules list
# 执行启动并输出控制台日志
./metricbeat -e
#后台启动
nohup ./metricbeat -e 1>/dev/null 2>&1 &kibana查看主机metrics
从kibana的metrics菜单可以看到监控信息。

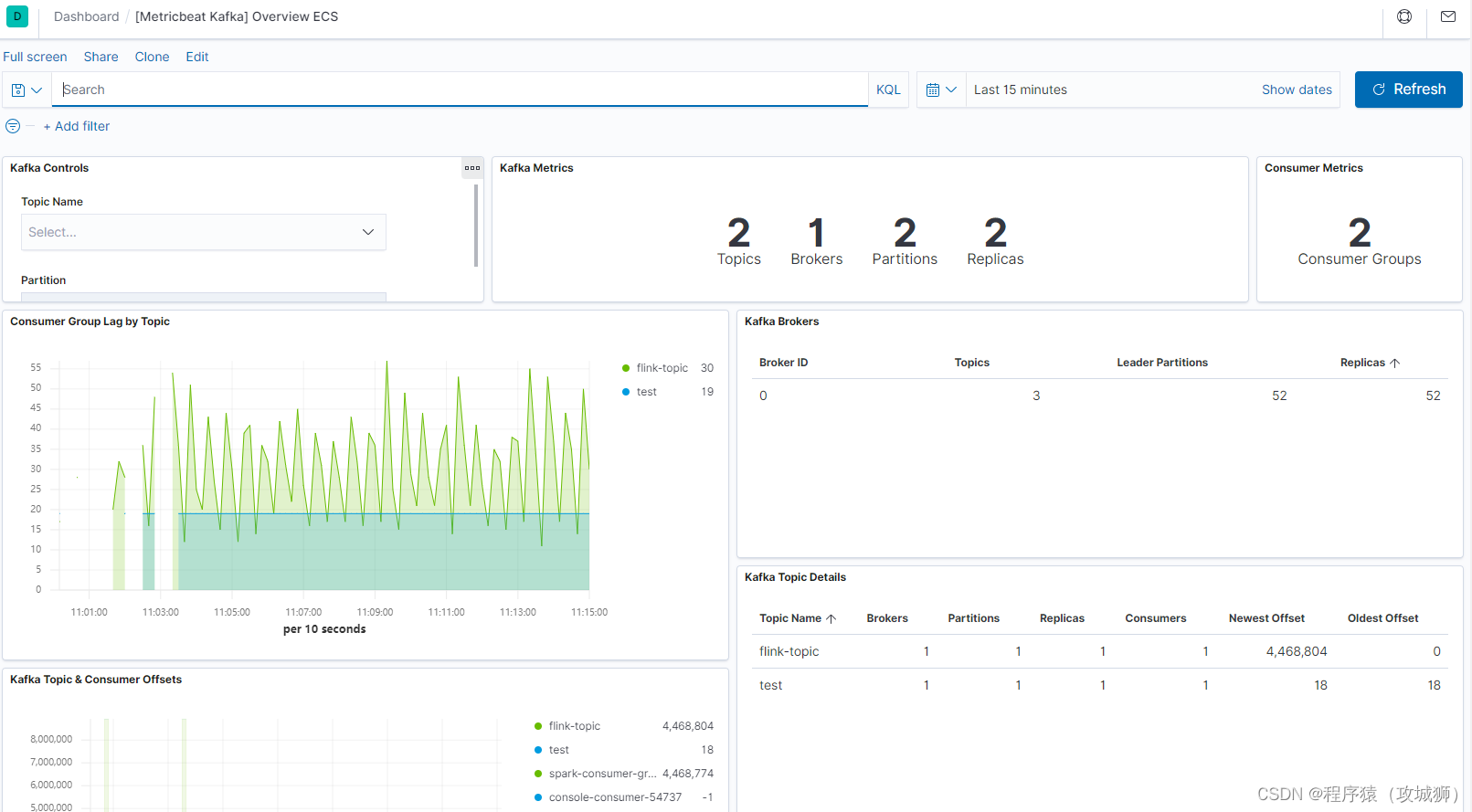
5. kibana查看kafka指标
kafka指标在dashboard中进行查看,选择kafka后,可以看到kafka的监控信息:
filebeat+Elk实现日志收集并使用kibana展示的更多相关文章
- Kafka+Zookeeper+Filebeat+ELK 搭建日志收集系统
ELK ELK目前主流的一种日志系统,过多的就不多介绍了 Filebeat收集日志,将收集的日志输出到kafka,避免网络问题丢失信息 kafka接收到日志消息后直接消费到Logstash Logst ...
- StringBoot整合ELK实现日志收集和搜索自动补全功能(详细图文教程)
@ 目录 StringBoot整合ELK实现日志收集和搜索自动补全功能(详细图文教程) 一.下载ELK的安装包上传并解压 1.Elasticsearch下载 2.Logstash下载 3.Kibana ...
- ELK分布式日志收集搭建和使用
大型系统分布式日志采集系统ELK全框架 SpringBootSecurity1.传统系统日志收集的问题2.Logstash操作工作原理3.分布式日志收集ELK原理4.Elasticsearch+Log ...
- 日志分析平台ELK之日志收集器filebeat
前面我们了解了elk集群中的logstash的用法,使用logstash处理日志挺好的,但是有一个缺陷,就是太慢了:当然logstash慢的原因是它依赖jruby虚拟机,jruby虚拟机就是用java ...
- SpringBoot+kafka+ELK分布式日志收集
一.背景 随着业务复杂度的提升以及微服务的兴起,传统单一项目会被按照业务规则进行垂直拆分,另外为了防止单点故障我们也会将重要的服务模块进行集群部署,通过负载均衡进行服务的调用.那么随着节点的增多,各个 ...
- ELK+kafka日志收集
一.服务器信息 版本 部署服务器 用途 备注 JDK jdk1.8.0_102 使用ELK5的服务器 Logstash 5.1.1 安装Tomcat的服务器 发送日志 Kafka降插件版本 Log ...
- ELK:日志收集分析平台
简介 ELK是一个日志收集分析的平台,它能收集海量的日志,并将其根据字段切割.一来方便供开发查看日志,定位问题:二来可以根据日志进行统计分析,通过其强大的呈现能力,挖掘数据的潜在价值,分析重要指标的趋 ...
- ELK/EFK——日志收集分析平台
ELK——日志收集分析平台 ELK简介:在开源的日志管理方案之中,最出名的莫过于ELK了,ELK由ElasticSearch.Logstash和Kiabana三个开源工具组成.1)ElasticSea ...
- ELK之方便的日志收集、搜索、展示工具
大家在做分部署系统开发的时候是不是经常因为查找日志而头疼,因为各服务器各应用都有自己日志,但比较分散,查找起来也比较麻烦,今天就给大家推荐一整套方便的工具ELK,ELK是Elastic公司开发的一整套 ...
- 微服务下,使用ELK做日志收集及分析
一.使用背景 目前项目中,采用的是微服务框架,对于日志,采用的是logback的配置,每个微服务的日志,都是通过File的方式存储在部署的机器上,但是由于日志比较分散,想要检查各个微服务是否有报错信息 ...
随机推荐
- 包子类&包子铺类-吃货类&测试类
包子类&包子铺类 资源类:包子类设置包子的属性皮陷包子的状态:有true,没有false package Demo01.WaitAndNotify; /** * 资源类:包子类设置包子的属性 ...
- 【学习日志】MySQL分表与索引的关系
什么情况下需要分表呢?分表又能解决什么问题呢? 一般情况下分表的直接原因是数据量太大了,比如一张表一共只有1w条数据,确实没必要分表.为什么数据量大了就需要分表呢?首先得看看数量量过大后会带来什么问题 ...
- 艰难的 debug 经历,vscode 无法获取远程环境 ssh 报错,windows 11 ssh
背景介绍 要做系统结构实验,学校和华为云合作使用华为云的 aarch64 裸机,需要使用 ssh 远程开发,笔者为了追求良好的开发体验,决定使用 vscode 开发,实验环境配置过程中遇到了两个问题, ...
- 【rust】rsut基础:模块的使用一、mod 关键字、mod.rs 文件的含义等
本文内容 这篇文章是实战性质的,也就是说原理部分较少,属于经验总结,rust对于模块的例子太少了.rust特性比较多(悲),本文的内容可能只是一部分,实现方式也不一定是这一种. 关于 rust 模块的 ...
- 5步带你入门GaussDB(DWS)的GDS导入导出
摘要:本篇文档为使用GDS导入示例的具体简单步骤和示例. 本文分享自华为云社区<带你快速入门GDS导入导出,玩转PB级数仓GaussDB(DWS)>,作者: yd_220527686. 1 ...
- 【KAWAKO】从mac上定时将腾讯云的数据备份到本地
目录 前言 需求 宝塔面板 备份网站 备份数据库 mac端 创建工程文件夹 rua.py rua stdout plist Reference 前言 不信任一切云端平台,把数据牢牢握在自己手中才是最安 ...
- JZOJ 3252. 【GDOI三校联考】炸弹
思路 注:上图只是个例子,其实建图时 \(5\) 是不会连向 \(6\) 的 \(Code\) #include<cstdio> #include<cstring> #incl ...
- JZOJ 2934. 【NOIP2012模拟8.7】字符串函数
题目大意 个等长的由大写英文字母构成的字符串 \(a\) 和 \(b\),从 \(a\) 中选择连续子串 \(x\),从 \(b\) 中选出连续子串y. 定义函数 \(f_{x,y}\) 为满足条件 ...
- Ubuntu18.04安装教程
转载csdn: Ubuntu18.04安装教程_Sunshine的博客-CSDN博客_ubuntu安装教程
- JavaSE 对象与类(二)
6.对象构造 重载:如果有多个方法(比如,StringBuilder构造器方法)有相同的名字.不同的参数.便产生了重载. 重载解析:编译器通过用各个方法给出的参数类型与特定方法调用所使用的值类型进行匹 ...