Mysql的驱动表 被驱动表 join buffer
1.为什么小表驱动大表:
for(int i=5;.......)
{
for(int j=1000;......)
{}
}
1.1如果小的循环在外层,对于数据库连接来说就只连接5次,进行5000次操作,如果1000在外,则需要进行1000次数据库连接,从而浪费资源,增加消耗。这就是为什么要小表驱动大表。
1.2驱动表(小表)的连接字段无论建立没建立索引都需要全表扫描的。被驱动表(大表)如果在连接字段建立了索引,则可以走索引。如果没有建立索引则也需要全表扫描。
1.3 两张表连接的情况
被驱动表的连接字段有索引:主键索引 对于驱动表中的每一条数据,到被驱动表的聚簇索引上寻找其对于的数据。 被驱动表的连接字段有索引:二级索引 对于驱动表上的每一条数据,到被驱动表的二次索引上寻找其对于的数据id,然后再根据数据id到聚簇索引上寻找对于的数据。 被驱动表的连接字段没有索引 对于驱动表上的每一条数据,都要到被驱动表上进行一次全表遍历,找到对应的数据。
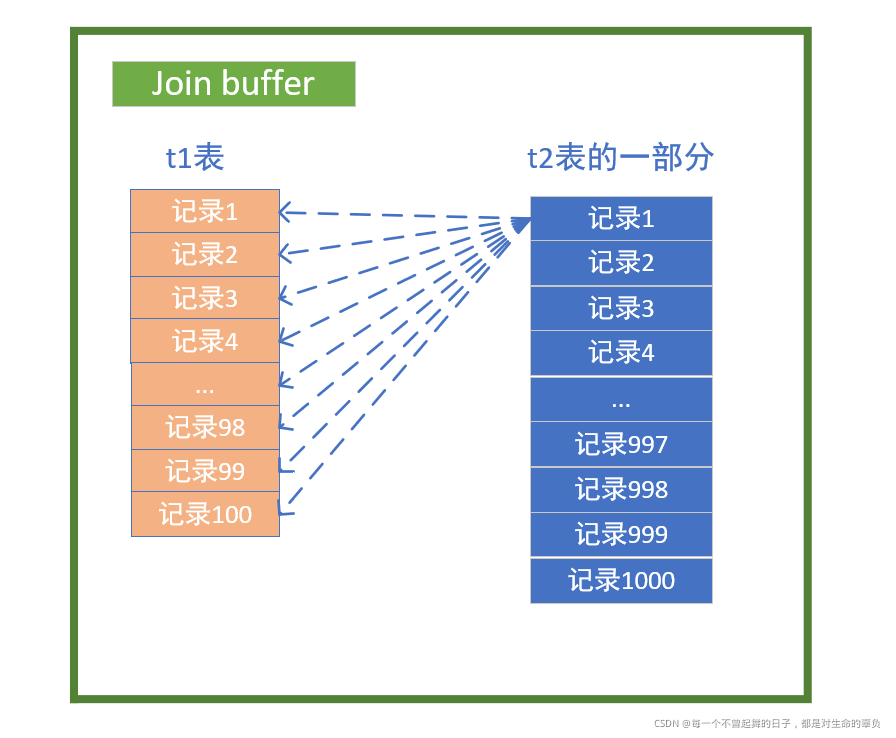
1.4 join buffer的作用
就是针对被驱动表的连接字段没有索引的情况下需要进行全表扫描,所以引入了join buffer内存缓冲区来对这个全表扫描过程进行优化。
在这个过程中,不再是每次从t1表中取1条记录。而是在开始时用内存缓冲区join buffer将t1表全部装入内存,每次取t2表的1000条记录调入内存。然后,让t1表与t2表在内存的这一部分(t2表在内存的这一部分作为外层循环,t1表作为内层循环)通过双重for循环进行匹配,然后循环这个过程,直到t2表的10000条数据都调入内存一次(即需要十次IO调入)。
2.判断驱动表与非驱动表
1 LEFT JOIN 左连接,左边为驱动表,右边为被驱动表.
2 RIGHT JOIN 右连接,右边为驱动表,左边为被驱动表.
3 INNER JOIN 内连接, mysql会选择数据量比较小的表作为驱动表,大表作为被驱动表.
4 可通过EXPLANIN查看SQL语句的执行计划,EXPLANIN分析的第一行的表即是驱动表.
3.in和exists
区分in和exists主要是造成了驱动顺序的改变(这是性能变化的关键)
in小 exists大
in后面跟的是小表,exists后面跟的是大表。
如果是exists,那么以外层表为驱动表,先被访问,如果是IN,那么先执行子查询。所以IN适合于外表大而内表小的情况;EXISTS适合于外表小而内表大的情况。
Mysql的驱动表 被驱动表 join buffer的更多相关文章
- MySQL连接查询驱动表被驱动表以及性能优化
准备我们需要的表结构和数据 两张表 studnet(学生)表和score(成绩)表, 创建表的SQL语句如下 CREATE TABLE `student` ( `id` int(11) NOT NUL ...
- Hash Join 一定是选择小表作为驱动表吗
原来自己也是一直认为oralce会选择小表作为驱动表,以前一直也没注意,今天看了落落大神的实验,才发现,oralce查询时不一定选择小表作为驱动表. 如果对大表增加了约束,大表也会作为驱动表. 实验见 ...
- MySql update inner join!MySql跨表更新 多表update sql语句?如何将select出来的部分数据update到另一个表里面?
项目中,评论数,关注数等数据,是实时更新的.+1,-1 这种. 有的时候,可能统计不准确. 需要写一个统计工具,更新校准下. 用Java写SQL和函数,代码很清晰,方便扩展,但是太慢了. 为了简单起见 ...
- Mysql 多表连接查询 inner join 和 outer join 的使用
JOIN的含义就如英文单词“join”一样,连接两张表,大致分为内连接,外连接,右连接,左连接,自然连接.这里描述先甩出一张用烂了的图,然后插入测试数据. 首先先列举本篇用到的分类(内连接,外连接,交 ...
- 从表单驱动到模型驱动,解读低代码开发平台的发展趋势 ZT
原文地址:https://www.grapecity.com.cn/blogs/read-the-trends-of-low-code-development-platforms 随着社会数字化进程的 ...
- mysql 常用命令 | 表间 弱关联 join
show databases; use mhxy; select database(); show tables; desc account_list_175; ),(); select from_u ...
- PostgreSQL EXPLAIN执行计划学习--多表连接几种Join方式比较
转了一部分.稍后再修改. 三种多表Join的算法: 一. NESTED LOOP: 对于被连接的数据子集较小的情况,嵌套循环连接是个较好的选择.在嵌套循环中,内表被外表驱动,外表返回的每一行都要在内表 ...
- Hive 文件格式 & Hive操作(外部表、内部表、区、桶、视图、索引、join用法、内置操作符与函数、复合类型、用户自定义函数UDF、查询优化和权限控制)
本博文的主要内容如下: Hive文件存储格式 Hive 操作之表操作:创建外.内部表 Hive操作之表操作:表查询 Hive操作之表操作:数据加载 Hive操作之表操作:插入单表.插入多表 Hive语 ...
- 【MySQL】数据库(分库分表)中间件对比
分区:对业务透明,分区只不过把存放数据的文件分成了许多小块,例如mysql中的一张表对应三个文件.MYD,MYI,frm. 根据一定的规则把数据文件(MYD)和索引文件(MYI)进行了分割,分区后的表 ...
- OLAP 大表和小表并行hash join
一个表50MB 一个表10GB 50M表做驱动表,放在PGA里 这时候慢在对对 10g 的全表扫描 对10个G扫描块 需要开并行 我有这样一个算法 一个进程 读 50mb 8进程 来 扫描 10gb ...
随机推荐
- jabc连接数据库
Java数据库连接,(Java Database Connectivity,简称JDBC)是Java语言中用来规范客户端程序如何来访问数据库的应用程序接口,提供了诸如查询和更新数据库中数据的方法.JD ...
- git log 的常用用法
1.最基本的 git log 2.简化版本 git log --oneline 3. 作者筛选 4.时间筛选 git log --since="2022.05.26" --unti ...
- nop调试-区域路由问题
1.在修改nop代码时,web项目里有一个namecontroller,然后区域Areas里也有一个namecontroller, 然后跳转时报错,提示有多个匹配项. 2.查看区域添加路由步骤:两步即 ...
- 图像bayer格式介绍
图像bayer格式介绍 https://zhuanlan.zhihu.com/p/72581663
- 【翻译】了解Flink-对DataStream API的介绍 -- Learn Flink-Intro to the DataStream API
目录 流式可以传输什么? Java元组和POJO 元组 POJO Scala元组和case classes 一个完整的例子 流执行环境 基本的stream sources 基本的stream sink ...
- Posggresql插件Multicorn安装问题总结
根据官网https://multicorn.readthedocs.io/en/latest/installation.html的安装指南下载安装,关键信息: Postgresql 9.1+ Post ...
- Pr视频软件主要知识点
1,选中某一个面板,点击"Tab键上的 '波浪号' 键"即可将这个面板全屏展示 . 2,新建序列项目:自定义,25帧/s,方形像素,无场(逐行扫描). 3,序列面板素材自动缩放适 ...
- ionic 架构
1.路由:rout,页面内容:html,页面css:scss,js脚本内容:ts 2.功能介绍 路由:负责组织每个页面. 页面css:scss,负责定制每个组件的内容,比如组件是iobag,那么在这个 ...
- 2019-2020-1 20199318《Linux内核原理与分析》第十三周作业
<Linux内核原理与分析> 第十三周作业 一.预备知识 缓冲区溢出是指程序试图向缓冲区写入超出预分配固定长度数据的情况.这一漏洞可以被恶意用户利用来改变程序的流控制,甚至执行代码的任意片 ...
- DB2日常维护操作
一. DB2日常维护操作 1.数据库的启动.停止.激活 db2 list active databases db2 active db 数据库名 db2start --启动 db2stop [forc ...