keras训练实例-python实现
用keras训练模型并实时显示loss/acc曲线,(重要的事情说三遍:实时!实时!实时!)实时导出loss/acc数值(导出的方法就是实时把loss/acc等写到一个文本文件中,其他模块如前端调用时可直接读取文本文件),同时也涉及了plt画图方法
ps:以下代码基于网上的一段程序修改完成,如有侵权,请联系我哈!
上代码:
from keras import Sequential, initializers, optimizers
from keras.layers import Activation, Dense
import numpy as np
import pylab as pl
from IPython import display
from keras.callbacks import Callback
from keras.datasets import mnist
import keras
from keras.layers import Conv2D, MaxPooling2D
from keras.layers import Dense, Dropout, Flatten #定义回调函数的类,用于实时显示loss/acc曲线和导出loss/acc数值
class DrawCallback(Callback):
def __init__(self, runtime_plot=True): # 初始化 self.init_loss = None
self.init_val_loss = None
self.init_acc = None
self.init_val_acc = None
self.runtime_plot = runtime_plot self.xdata = []
self.ydata = []
self.ydata2 = []
self.ydata3 = []
self.ydata4 = []
def _plot(self, epoch=None):
epochs = self.params.get("epochs")
pl.subplot(121) #画第一个图,121表示纵向1个图,横向2个图,当前第1个图
pl.ylim(0, int(self.init_loss*1.2)) #限制坐标轴范围
pl.xlim(0, epochs)
pl.plot(self.xdata, self.ydata,'r', label='loss') #xdata/ydata均为不断增长的一维数组,同时定义了线段颜色/类型/图例
pl.plot(self.xdata, self.ydata2, 'b--', label='val_loss')
pl.xlabel('Epoch {}/{}'.format(epoch or epochs, epochs)) #坐标轴显示变化的标签
pl.ylabel('Loss {:.4f}'.format(self.ydata[-1]))
pl.legend() #显示图例,不加这个即便是定义图例了也没用
pl.title('loss') #显示标题 pl.subplot(122)
pl.ylim(0, 1.2)
pl.xlim(0, epochs)
pl.plot(self.xdata, self.ydata3,'r', label='acc')
pl.plot(self.xdata, self.ydata4, 'b--', label='val_acc')
pl.xlabel('Epoch {}/{}'.format(epoch or epochs, epochs))
pl.ylabel('Loss {:.4f}'.format(self.ydata[-1]))
pl.legend()
pl.title('acc') def _runtime_plot(self, epoch):
self._plot(epoch)
#不断的清图
display.clear_output(wait=True)
display.display(pl.gcf())
pl.gcf().clear() def plot(self):
self._plot()
pl.show() #显示窗口 def on_epoch_end(self, epoch, logs = None): #更新xdata/ydata
logs = logs or {}
# batch_size = self.params.get("batch_size")
epochs = self.params.get("epochs") #获取训练相关数据
loss = logs.get("loss")
val_loss = logs.get("val_loss")
acc = logs.get("acc")
val_acc = logs.get("val_acc") epochs_str = str(epochs)[0:6] #为了写入txt,必须转为字符型,为了美观只保留小数点后4位
loss_str = str(loss)[0:6]
val_loss_str = str(val_loss)[0:6]
acc_str = str(acc)[0:6]
val_acc_str = str(val_acc)[0:6] f = open('logs_r/record.txt','a') #要用追加方式‘a’写入txt,所在行数就是当前迭代次数
f.write('epochs:{}_loss:{}_val_loss:{}_acc:{}_val_acc{}'.format(epochs_str,loss_str,val_loss_str,acc_str,val_acc_str))
f.write('\n')
f.close() if self.init_loss is None: #增加xdata/ydata内容
self.init_loss = loss
self.init_val_loss = val_loss
self.xdata.append(epoch)
self.ydata.append(loss)
self.ydata2.append(val_loss)
self.ydata3.append(acc)
self.ydata4.append(val_acc)
if self.runtime_plot:
self._runtime_plot(epoch) # 下面开始构建keras需要的东西
def viz_keras_fit(runtime_plot=False):
d = DrawCallback(runtime_plot = runtime_plot) #实例化回调函数
(x_train, y_train), (x_test, y_test) = mnist.load_data()
x_train = x_train.reshape(-1,28,28,1)
x_test = x_test.reshape(-1,28,28,1)
input_shape = (28,28,1)
x_train = x_train/255
x_test = x_test/255
y_train = keras.utils.to_categorical(y_train,10)
y_test = keras.utils.to_categorical(y_test,10)
#为了减小计算量,减少了训练/测试数据
x_train = x_train[0:600,:,:,:]
x_test = x_test[0:100,:,:,:]
y_train = y_train[0:600,:]
y_test = y_test[0:100,:] model = Sequential() #实例化一个模型
#接下来一顿操作,就是搭建网络
model.add(Conv2D(filters=32, kernel_size=(3,3),
activation='relu', input_shape=input_shape,
name='conv1'))
model.add(Conv2D(64,(3,3),activation='relu',name='conv2'))
model.add(MaxPooling2D(pool_size=(2,2),name='pool2'))
model.add(Dropout(0.25,name='dropout1'))
model.add(Flatten(name='flat1'))
model.add(Dense(128,activation='relu'))
model.add(Dropout(0.5,name='dropout2'))
model.add(Dense(10,activation='softmax',name='output'))
#编译网络,同时定义了loss方法/优化方法/监测内容
model.compile(loss=keras.losses.categorical_crossentropy,
optimizer=keras.optimizers.Adadelta(),
metrics=['accuracy'])
#开始训练
model.fit(x = x_train,
y = y_train,
epochs=30,
verbose=0, #当值为1时,会打印训练过程
validation_data=(x_test, y_test), #加入测试数据,不然有些数据时看不到的
callbacks=[d]) #指定回调函数
return d
最后运行:
viz_keras_fit(runtime_plot=True) #调用函数
显示结果:
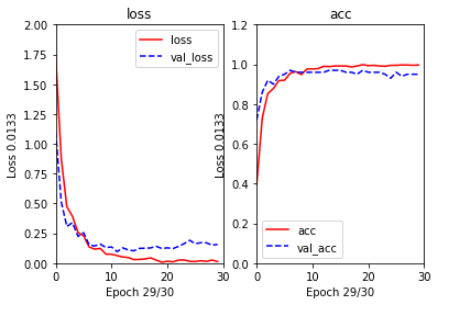
keras训练实例-python实现的更多相关文章
- keras训练cnn模型时loss为nan
keras训练cnn模型时loss为nan 1.首先记下来如何解决这个问题的:由于我代码中 model.compile(loss='categorical_crossentropy', optimiz ...
- Keras 训练 inceptionV3 并移植到OpenCV4.0 in C++
1. 训练 # --coding:utf--- import os import sys import glob import argparse import matplotlib.pyplot as ...
- 使用Keras训练大规模数据集
官方提供的.flow_from_directory(directory)函数可以读取并训练大规模训练数据,基本可以满足大部分需求.但是在有些场合下,需要自己读取大规模数据以及对应标签,下面提供一种方法 ...
- keras训练和保存
https://cloud.tencent.com/developer/article/1010815 8.更科学地模型训练与模型保存 filepath = 'model-ep{epoch:03d}- ...
- Keras 训练一个单层全连接网络的线性回归模型
1.准备环境,探索数据 import numpy as np from keras.models import Sequential from keras.layers import Dense im ...
- Keras 入门实例
使用Keras构建神经网络的基本工作流程主要可以分为 4个部分.(而这个用法和思路,很像是在使用Scikit-learn中的机器学习方法) Model definition → Model compi ...
- 使用Keras训练神经网络备忘录
小书匠深度学习 文章太长,放个目录: 1.优化函数的选择 2.损失函数的选择 2.2常用的损失函数 2.2自定义函数 2.1实践 2.2将损失函数自定义为网络层 3.模型的保存 3.1同时保持结构和权 ...
- keras训练大量数据的办法
最近在做一个鉴黄的项目,数据量比较大,有几百个G,一次性加入内存再去训练模青型是不现实的. 查阅资料发现keras中可以用两种方法解决,一是将数据转为tfrecord,但转换后数据大小会方法不好:另外 ...
- 【机器学习实战学习笔记(1-2)】k-近邻算法应用实例python代码
文章目录 1.改进约会网站匹配效果 1.1 准备数据:从文本文件中解析数据 1.2 分析数据:使用Matplotlib创建散点图 1.3 准备数据:归一化特征 1.4 测试算法:作为完整程序验证分类器 ...
随机推荐
- Chisel3 - Chisel vs. Scala
https://mp.weixin.qq.com/s/mTmXXBzSizgiigFYVQXKpw 介绍Chisel与Scala的不同与关联. 一. 层次高低 Chisel是 ...
- (Java实现)洛谷 P1093 奖学金
题目描述 某小学最近得到了一笔赞助,打算拿出其中一部分为学习成绩优秀的前5名学生发奖学金.期末,每个学生都有3门课的成绩:语文.数学.英语.先按总分从高到低排序,如果两个同学总分相同,再按语文成绩从高 ...
- Java实现洛谷 P1873 砍树(StreamTokenizer+IO+二分)
P1873 砍树 输入输出样例 输入 5 20 4 42 40 26 46 输出 36 PS: get新知识,以前只知道STringTokenizer并没有了解过StreamTokenizer,这次才 ...
- Java实现 蓝桥杯VIP 算法提高 贪吃的大嘴
算法提高 贪吃的大嘴 时间限制:1.0s 内存限制:256.0MB 问题描述 有一只特别贪吃的大嘴,她很喜欢吃一种小蛋糕,而每一个小蛋糕有一个美味度,而大嘴是很傲娇的,一定要吃美味度和刚好为m的小蛋糕 ...
- java实现拼出漂亮的表格
/* * 在中文 Windows 环境下,控制台窗口中也可以用特殊符号拼出漂亮的表格来. 比如: ┌─┬─┐ │ │ │ ├─┼─┤ │ │ │ └─┴─┘ 其实,它是由如下的符号拼接的: 左上 = ...
- java实现第四届蓝桥杯危险系数
危险系数 抗日战争时期,冀中平原的地道战曾发挥重要作用. 地道的多个站点间有通道连接,形成了庞大的网络.但也有隐患,当敌人发现了某个站点后,其它站点间可能因此会失去联系. 我们来定义一个危险系数DF( ...
- Java 入门教程
Java 入门教程 Java 是由Sun Microsystems公司于1995年5月推出的高级程序设计语言. Java可运行于多个平台,如Windows, Mac OS,及其他多种UNIX版本的系统 ...
- session共享同步redis策略
关于session共享的文章,网上很多,可是最关键的点我没有看到一篇.也就是session对象到底是怎么同步到redis的. spring-session底层原理到底是怎么样的一个同步更新策略,我没有 ...
- @loj - 2106@ 「JLOI2015」有意义的字符串
目录 @description@ @solution@ @accepted code@ @details@ @description@ B 君有两个好朋友,他们叫宁宁和冉冉.有一天,冉冉遇到了一个有趣 ...
- Oracle VM VirtualBox 连接 Centos7 minimal版
概述: 本博客是系列博客,主要讲述在Windows环境下安装虚拟机,在虚拟机中安装lunix系统,在lunix下安装docker,在docker中安装并使用常用的开发软件,比如tomcat.redis ...