WordCount程序(Java)
Github项目地址:https://github.com/softwareCQT/web_camp/tree/master/wordCount
一、题目描述
实现一个简单而完整的软件工具(源程序特征统计程序)。
进行单元测试、回归测试、效能测试,在实现上述程序的过程中使用相关的工具。
进行个人软件过程(PSP)的实践,逐步记录自己在每个软件工程环节花费的时间。
二、WC 项目要求
wc.exe 是一个常见的工具,它能统计文本文件的字符数、单词数和行数。这个项目要求写一个命令行程序,模仿已有wc.exe 的功能,并加以扩充,给出某程序设计语言源文件的字符数、单词数和行数。
实现一个统计程序,它能正确统计程序文件中的字符数、单词数、行数,以及还具备其他扩展功能,并能够快速地处理多个文件。
具体功能要求:程序处理用户需求的模式为:wc.exe [parameter] [file_name]
三、核心代码
文件处理(包括处理通配符*?和-s递归)
/**
* @author chenqiting
*/
public class FileUtil {
/***
* 判断文件是否合法 且 处理通配符并返回文件列表
* @return List<File>
*/
public static List<File> accessRegx(String fileName){
if (fileName.contains(CommandConstants.UNIVERSAL_CHAR_ONE)
|| fileName.contains(CommandConstants.UNIVERSAL_CHAR_TWO)) {
//判断是否存在通配符,统一换掉参数
fileName = fileName.
replace(CommandConstants.UNIVERSAL_CHAR_TWO, CommandConstants.UNIVERSAL_CHAR_ONE);
//如果是绝对路径,获取绝对路径的前半段,即获取到*号之前的路径
int index = fileName.indexOf("*");
//标志文件是否在文件后缀加的通配符
boolean flag = (index == fileName.length() - 1);
String parentDirectory;
String childFileName;
//如果是文件类型通配符,父路径需要重新处理
if (flag) {
index = fileName.lastIndexOf("\\");
index = index == -1 ? 0 : index;
}
parentDirectory = fileName.substring(0, index);
childFileName = fileName.substring(index);
//系统路径匹配器
PathMatcher pathMatcher;
File file;
//空字符串表示需要当前路径匹配
if ("".equals(parentDirectory)){
file = new File(".");
String string = file.getAbsolutePath().replace(".", "").replace("\\", "\\\\");
file = new File(string);
pathMatcher = FileSystems.getDefault().
getPathMatcher("regex:" + string + "\\\\" + childFileName);
}else {
parentDirectory = parentDirectory.replace("\\", "\\\\");
file = new File(parentDirectory);
//在parentDirectory目录下进行遍历
pathMatcher = FileSystems.getDefault().
getPathMatcher("glob:" + parentDirectory + childFileName);
}
return stackForFile(file, pathMatcher);
}else {
File file = new File(fileName);
//判断文件是否存在
if (file.exists()){
if (file.isDirectory()){
System.out.println(file.getName() + "不是文件,请重新输入");
}
}else {
System.out.println("找不到该文件");
}
ArrayList<File> arrayList = new ArrayList<>(1);
arrayList.add(file);
return arrayList;
}
}
/***
* 处理当前目录下的所有符合的文件
* @return 文件的集合
*/
public static List<File> getBlowFile(String fileName){
String newFileName = fileName.
replace(CommandConstants.UNIVERSAL_CHAR_TWO, CommandConstants.UNIVERSAL_CHAR_ONE);
//路径匹配器
PathMatcher pathMatcher = FileSystems.getDefault().getPathMatcher("glob:" + "**/" + newFileName);
return stackForFile(new File("."), pathMatcher);
}
/***
* 把当前文件夹下的文件放进栈
* @param file
* @param stringDeque
*/
private static void addToStack(File file, Queue<File> stringDeque) {
File[] string = file.listFiles();
if (!Objects.isNull(string)) {
Collections.addAll(stringDeque, string);
}
}
/***
* 递归匹配查找函数
* @param parent 父目录
* @param pathMatcher 匹配器
* @return 文件
*/
private static List<File> stackForFile(File parent, PathMatcher pathMatcher){
//文件不存在
if (!parent.exists()) {
return null;
}
ArrayDeque<File> stringDeque = new ArrayDeque<>();
addToStack(parent, stringDeque);
//创建结果集合
List<File> strings = new ArrayList<>();
//用栈去处理文件
while (!stringDeque.isEmpty()) {
File newFile = stringDeque.pollLast();
if (newFile.isDirectory()) {
addToStack(newFile, stringDeque);
}else {
if (pathMatcher.matches(newFile.toPath())){
strings.add(newFile);
}
}
}
return strings;
}
获取文件流中的数据,用BufferedReader读取流,然后转换流为List
/***
* 打开文件流并执行命令操作
* @param files 文件
* @param commandString 命令字符串
* @throws NullPointerException 空指针防止有未知命令出现
*/
private static void invoke(List<File> files, List<String> commandString) throws NullPointerException{
//判空处理
if (Objects.isNull(files) || files.isEmpty()) {
System.out.println("文件参数使用错误或目录下没有匹配文件");
return;
}
//对文件进行命令操作
files.forEach(file -> {
try (BufferedReader bufferedReader = new BufferedReader(new FileReader(file))){
System.out.println("文件名称:" + file.getPath());
List<String> stringList = bufferedReader.lines().collect(Collectors.toList());
for (String string : commandString) {
BaseCommand baseCommand = CommandFactory.getValue(string);
baseCommand.fileLineList(stringList).invoke();
}
} catch (IOException e) {
System.out.println("文件错误");
}
});
}
-c 命令处理
/**
* @author chenqiting
*/
public class AllBaseCommand extends BaseCommand<AllBaseCommand> {
@Override
public void invoke() throws IOException {
//分别统计注释行、代码行、空行
int descriptionLine = 0;
int codeLine = 0;
int nullLine = 0;
//标注多行注释
boolean flag = false;
//用来引用处理过的string
String stringBuffer;
for (String string : fileLineList){
//去掉所有空白字符
stringBuffer = string.replaceAll("\\s+", "");
//先判断flag是否为真,优先处理
if (flag){
if (string.endsWith("*/")){
flag = false;
}
descriptionLine++;
continue;
}
//空行
if ("".equals(string)){
nullLine++;
} else if (stringBuffer.startsWith("/*") && stringBuffer.endsWith("*/")){
//同行注释同行结束,直接相加
descriptionLine++;
} else if (stringBuffer.startsWith("/*") && !stringBuffer.endsWith("*/")){
flag = true;
descriptionLine++;
} else if (stringBuffer.matches("^\\S(//)")){
//单字符后存在的注释情况//
descriptionLine++;
} else {
//其余全为代码行
codeLine++;
}
}
System.out.println("空行:" + nullLine);
System.out.println("注释行:" + descriptionLine);
System.out.println("代码行:" + codeLine);
}
}
-l命令处理
/**
* @author chenqiting
*/
public class AllBaseCommand extends BaseCommand<AllBaseCommand> {
@Override
public void invoke() throws IOException {
//分别统计注释行、代码行、空行
int descriptionLine = 0;
int codeLine = 0;
int nullLine = 0;
//标注多行注释
boolean flag = false;
//用来引用处理过的string
String stringBuffer;
for (String string : fileLineList){
//去掉所有空白字符
stringBuffer = string.replaceAll("\\s+", "");
//先判断flag是否为真,优先处理
if (flag){
if (string.endsWith("*/")){
flag = false;
}
descriptionLine++;
continue;
}
//空行
if ("".equals(string)){
nullLine++;
} else if (stringBuffer.startsWith("/*") && stringBuffer.endsWith("*/")){
//同行注释同行结束,直接相加
descriptionLine++;
} else if (stringBuffer.startsWith("/*") && !stringBuffer.endsWith("*/")){
flag = true;
descriptionLine++;
} else if (stringBuffer.matches("^\\S(//)")){
//单字符后存在的注释情况//
descriptionLine++;
} else {
//其余全为代码行
codeLine++;
}
}
System.out.println("空行:" + nullLine);
System.out.println("注释行:" + descriptionLine);
System.out.println("代码行:" + codeLine);
}
}
-l命令处理
/**
* @author chenqiting
*/
public class LineBaseCommand extends BaseCommand<LineBaseCommand> {
@Override
public void invoke() throws IOException {
System.out.println("文件行数:" + fileLineList.size());
}
}
-a命令处理
@Override
public void invoke() throws IOException {
//分别统计注释行、代码行、空行
int descriptionLine = 0;
int codeLine = 0;
int nullLine = 0;
//标注多行注释
boolean flag = false;
//用来引用处理过的string
String stringBuffer;
for (String string : fileLineList){
//去掉所有空白字符
stringBuffer = string.replaceAll("\\s+", "");
//先判断flag是否为真,优先处理
if (flag){
if (string.endsWith("*/")){
flag = false;
}
descriptionLine++;
continue;
}
//空行
if ("".equals(string)){
nullLine++;
} else if (stringBuffer.startsWith("/*") && stringBuffer.endsWith("*/")){
//同行注释同行结束,直接相加
descriptionLine++;
} else if (stringBuffer.startsWith("/*") && !stringBuffer.endsWith("*/")){
flag = true;
descriptionLine++;
} else if (stringBuffer.matches("^\\S(//)")){
//单字符后存在的注释情况//
descriptionLine++;
} else {
//其余全为代码行
codeLine++;
}
}
System.out.println("空行:" + nullLine);
System.out.println("注释行:" + descriptionLine);
System.out.println("代码行:" + codeLine);
}
}
主函数调用,工厂方法
public static void main(String[] args){
//获取参数
List<String> commandString = util.ArgsUtil.getCommand(args);
String fileName = util.ArgsUtil.getFileName(args);
try {
//验证参数是否存在问题
if (!commandString.isEmpty() && Objects.nonNull(fileName)) {
//判断是否存在-s递归
boolean flag = commandString.contains(CommandConstants.COUNT_SOME_FILE);
List<File> files;
//递归则获取文件目录
if (flag) {
//递归获取当前路径
files = FileUtil.getBlowFile(fileName);
// 因为-s命令比其他命令优先级高,且作用不同,所以要提前剔除
commandString.remove(CommandConstants.COUNT_SOME_FILE);
} else {
//TODO 处理通配符的问题
files = FileUtil.accessRegx(fileName);
}
invoke(files, commandString);
} else if (commandString.size() == 1 && commandString.get(0).equals(CommandConstants.COUNT_HELP) ){
//需要对参数进行判断,然后实现CountHelp
CommandFactory.getValue(CommandConstants.COUNT_HELP).invoke();
} else {
//参数错误
CommandFactory.getValue(CommandConstants.COUNT_ERROR).invoke();
}
} catch (NullPointerException e) {
//对未知参数进行捕获
System.out.println("命令出现未知参数");
} catch (Exception e){
System.out.println("系统错误");
}
}四、项目测试
java并没有不可以直接实现exe程序,需要使用工具转换,且与wc.exe文件相协同的文件目录下必须存在jre
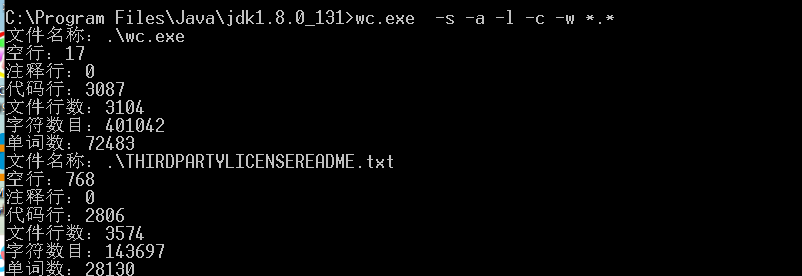

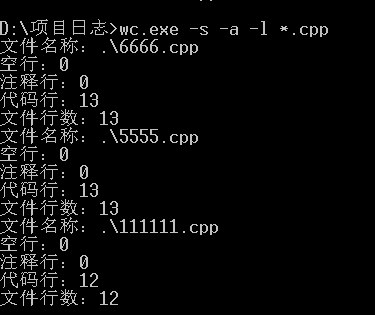
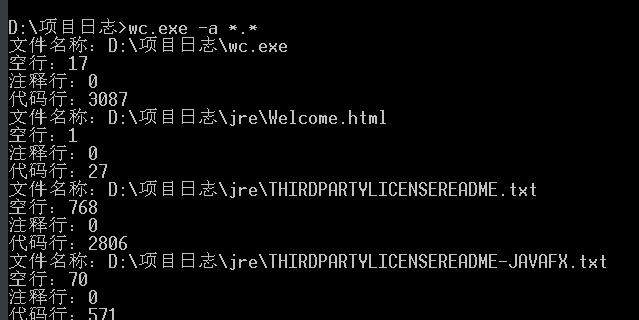
五、PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 10 | 15 |
| · Estimate | · 估计这个任务需要多少时间 | 250 | 300 |
| Development | 开发 | 300 | 350 |
| · Analysis | · 需求分析 (包括学习新技术) | 10 | 10 |
| · Design Spec | · 生成设计文档 | 10 | 10 |
| · Design Review | · 设计复审 (和同事审核设计文档) | 10 | 10 |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 5 | 5 |
| · Design | · 具体设计 | 30 | 25 |
| · Coding | · 具体编码 | 150 | 250 |
| · Code Review | · 代码复审 | 10 | 15 |
| · Test | · 测试(自我测试,修改代码,提交修改) | 10 | 30 |
| Reporting | 报告 | 15 | 20 |
| · Test Report | · 测试报告 | 10 | 30 |
| · Size Measurement | · 计算工作量 | 15 | 20 |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 15 | 30 |
| 合计 | 850 | 1020 |
六、总结
学习了一下Java对正则表达式的PatternAPI的支持,以及正则表达式的内容。整体来说Java可以用BufferedReader流直接通过Stream流来转换成集合存储每一行,导致文件内容可重用,而不用持续地进行IO。编码过程中也在思考设计模式可以在里面充当什么角色,所以根据命令的不同,我使用了工厂模式,程序可扩展性算中等。
WordCount程序(Java)的更多相关文章
- Spark练习之通过Spark Streaming实时计算wordcount程序
Spark练习之通过Spark Streaming实时计算wordcount程序 Java版本 Scala版本 pom.xml Java版本 import org.apache.spark.Spark ...
- 编写Spark的WordCount程序并提交到集群运行[含scala和java两个版本]
编写Spark的WordCount程序并提交到集群运行[含scala和java两个版本] 1. 开发环境 Jdk 1.7.0_72 Maven 3.2.1 Scala 2.10.6 Spark 1.6 ...
- 将java开发的wordcount程序提交到spark集群上运行
今天来分享下将java开发的wordcount程序提交到spark集群上运行的步骤. 第一个步骤之前,先上传文本文件,spark.txt,然用命令hadoop fs -put spark.txt /s ...
- 大数据之路week07--day03(Hadoop深入理解,JAVA代码编写WordCount程序,以及扩展升级)
什么是MapReduce 你想数出一摞牌中有多少张黑桃.直观方式是一张一张检查并且数出有多少张是黑桃. MapReduce方法则是: 1.给在座的所有玩家中分配这摞牌 2.让每个玩家数自己手中的牌有几 ...
- Hadoop入门实践之从WordCount程序说起
这段时间需要学习Hadoop了,以前一直听说Hadoop,但是从来没有研究过,这几天粗略看完了<Hadoop实战>这本书,对Hadoop编程有了大致的了解.接下来就是多看多写了.以Hado ...
- [转] 用SBT编译Spark的WordCount程序
问题导读: 1.什么是sbt? 2.sbt项目环境如何建立? 3.如何使用sbt编译打包scala? [sbt介绍 sbt是一个代码编译工具,是scala界的mvn,可以编译scala,java等,需 ...
- WordCount程序代码解
package com.bigdata.hadoop.wordcount; import java.io.IOException; import org.apache.hadoop.conf.Conf ...
- Hadoop集群测试wordcount程序
一.集群环境搭好了,我们来测试一下吧 1.在java下创建一个wordcount文件夹:mkdir wordcount 2.在此文件夹下创建两个文件,比如file1.txt和file2.txt 在fi ...
- Eclipse环境搭建并且运行wordcount程序
一.安装Hadoop插件 1. 所需环境 hadoop2.0伪分布式环境平台正常运行 所需压缩包:eclipse-jee-luna-SR2-linux-gtk-x86_64.tar.gz 在Linu ...
- 在IDEA中编写Spark的WordCount程序
1:spark shell仅在测试和验证我们的程序时使用的较多,在生产环境中,通常会在IDE中编制程序,然后打成jar包,然后提交到集群,最常用的是创建一个Maven项目,利用Maven来管理jar包 ...
随机推荐
- Handler机制中的消息队列
--> 学习自蘑菇街大佬 Handler机制可以看成是一个消息阻塞队列,当有消息时立即处理消息,没有消息时则阻塞.在Android系统中APP启动后很快进入死循环,不断读取MessageQueu ...
- Shell的特殊字符
# 有意义的“#”符合 echo ${PATH#*:} # 参数替换,不是一个注释 echo $(( 2#101011 )) # 进制转换,可以是任意进制,不是一个注释 “.” .字符匹配,这是作为正 ...
- linux下光标操作
Ctrl+左右键 单词间跳转 Ctrl+a 跳到行首 Ctrl+e 跳到行尾 Ctrl+u 删除当前光标前的文字 Ctrl+k 删除当前光标后的文字 Ctrl+w ...
- ERROR 1176 (42000): Key 'XXX' doesn't exist in table 'XXX'报错处理
MySQL5.7对sql语句强制使用索引查询时报错如下: 解决:这里的id字段是表的主键,查看别人的经验贴得知是语法错误,参考链接https://stackoverflow.com/questions ...
- Turn and Stun server · J
本文简介了Turnserver(Turn + Stun)服务器的搭建.Turnserver主要提供了stun服务,支撑NAT.防火墙穿透,turn服务器,支撑打洞失败时的数据中转.使用场景上类似于前端 ...
- javascript中变量命名规则
前言 变量的命名相对而言没有太多的技术含量,今天整理有关于变量命名相关的规则,主要是想告诉大家,虽然命名没有技术含量,但对于个人编码,或者说一个团队的再次开发及阅读是相当有用的.良好的书写规范可以让你 ...
- 移动端使用mint-ui组件loadmore填坑
链接地址为 https://mint-ui.github.io/docs/#/en2/loadmore ,这里需要注意引入的方式,我这里是用cdn的方式引入的.请结合官方API阅读本文章. 2.在 ...
- 2——PHP defined()函数
*/ * Copyright (c) 2016,烟台大学计算机与控制工程学院 * All rights reserved. * 文件名:text.cpp * 作者:常轩 * 微信公众号:Worldhe ...
- Typecho 主题制作记录
模板制作快速入门 模板的制作并非难事,只要你写好了HTML和CSS,嵌套模板就非常简单了,你无需了解标签的内部结构,你只要会使用,模板就能迅速完成.这篇文章只简单的介绍了常用标签的使用方法,希望能带你 ...
- [面试专题]Web缓存详解
Web缓存详解 标签(空格分隔): 缓存 缓存之于性能优化 请求更快:通过将内容缓存在本地浏览器或距离最近的缓存服务器(如CDN),在不影响网站交互的前提下可以大大加快网站加载速度. 降低服务器压力: ...