吴裕雄--天生自然 python数据分析:葡萄酒分析
# import pandas
import pandas as pd # creating a DataFrame
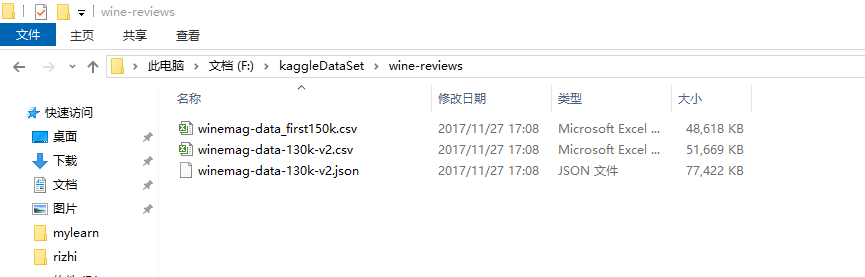
pd.DataFrame({'Yes': [50, 31], 'No': [101, 2]})
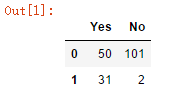
# another example of creating a dataframe
pd.DataFrame({'Bob': ['I liked it.', 'It was awful.'], 'Sue': ['Pretty good.', 'Bland']})
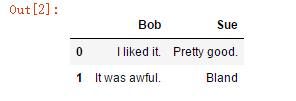
pd.DataFrame({'Bob': ['I liked it.', 'It was awful.'],
'Sue': ['Pretty good.', 'Bland.']},
index = ['Product A', 'Product B'])

# creating a pandas series
pd.Series([1, 2, 3, 4, 5])

# we can think of a Series as a column of a DataFrame.
# we can assign index values to Series in same way as pandas DataFrame
pd.Series([10, 20, 30], index=['2015 sales', '2016 sales', '2017 sales'], name='Product A')

# reading a csv file and storing it in a variable
wine_reviews = pd.read_csv("F:\\kaggleDataSet\\wine-reviews\\winemag-data-130k-v2.csv")
# we can use the 'shape' attribute to check size of dataset
wine_reviews.shape
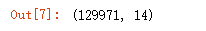
# To show first five rows of data, use 'head()' method
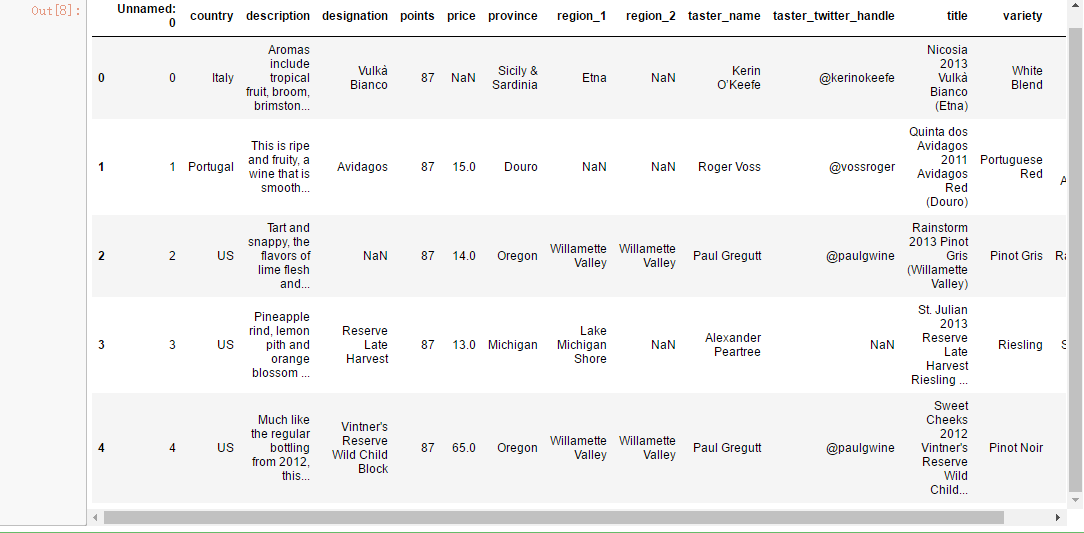
wine_reviews.head()
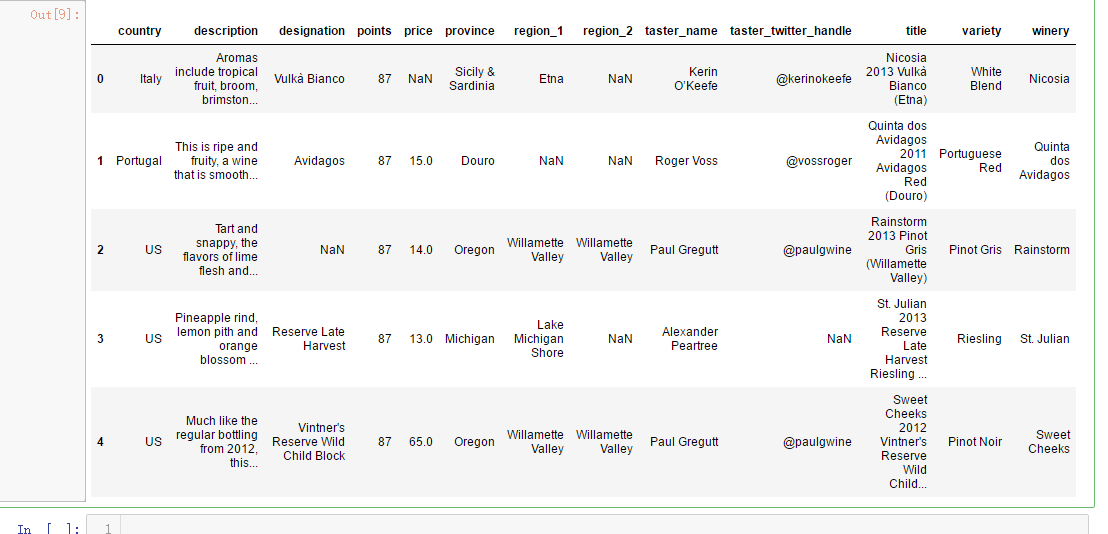
wine_reviews = pd.read_csv("F:\\kaggleDataSet\\wine-reviews\\winemag-data-130k-v2.csv", index_col=0)
wine_reviews.head()
wine_reviews.head().to_csv("F:\\wine_reviews.csv")
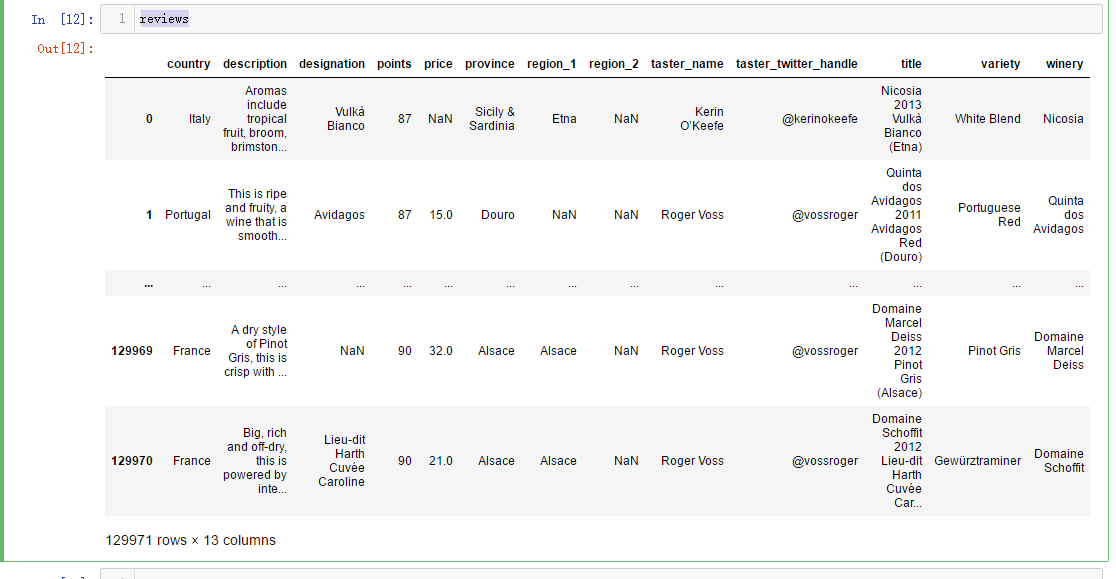
import pandas as pd
reviews = pd.read_csv("F:\\kaggleDataSet\\wine-reviews\\winemag-data-130k-v2.csv", index_col=0)
pd.set_option("display.max_rows", 5)
reviews
# access 'country' property (or column) of 'reviews'
reviews.country

# Another way to do above operation
# when a column name contains space, we have to use this method
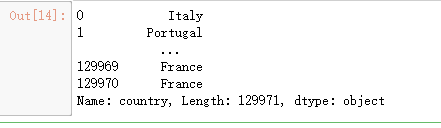
reviews['country']
# To access first row of country column
reviews['country'][0]

# returns first row
reviews.iloc[0]

# returns first column (country) (all rows due to ':')
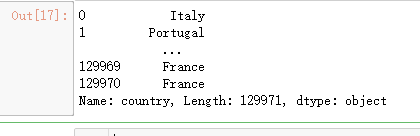
reviews.iloc[:, 0]
# retruns first 3 rows of first column
reviews.iloc[:3, 0]

# we can pass a list of indices of rows/columns to select
reviews.iloc[[0, 1, 2, 3], 0]

# We can also pass negative numbers as we do in Python
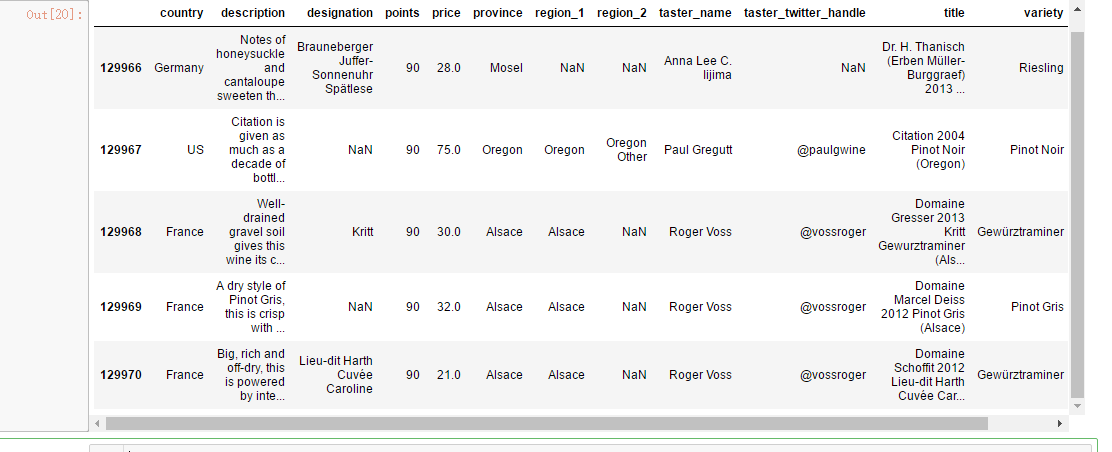
reviews.iloc[-5:]
# To select first entry in country column
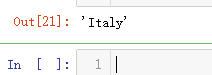
reviews.loc[0, 'country']
# select columns by name using 'loc'
reviews.loc[:, ['taster_name', 'taster_twitter_handle', 'points']]
# 'set_index' to the 'title' field
reviews.set_index('title')

# 1. Find out whether wine is produced in Italy
reviews.country == 'Italy'

# 2. Now select all wines produced in Italy
reviews.loc[reviews.country == 'Italy'] #reviews[reviews.country == 'Italy']
# Add one more condition for points to find better than average wines produced in Italy
reviews.loc[(reviews.country == 'Italy') & (reviews.points >= 90)] # use | for 'OR' condition
reviews.loc[reviews.country.isin(['Italy', 'France'])]
reviews.loc[reviews.price.notnull()]
reviews['critic'] = 'everyone'
reviews.critic

# using iterable for assigning
reviews['index_backwards'] = range(len(reviews), 0, -1)
reviews['index_backwards']

吴裕雄--天生自然 python数据分析:葡萄酒分析的更多相关文章
- 吴裕雄--天生自然 PYTHON数据分析:所有美国股票和etf的历史日价格和成交量分析
# This Python 3 environment comes with many helpful analytics libraries installed # It is defined by ...
- 吴裕雄--天生自然 python数据分析:健康指标聚集分析(健康分析)
# This Python 3 environment comes with many helpful analytics libraries installed # It is defined by ...
- 吴裕雄--天生自然 PYTHON数据分析:基于Keras的CNN分析太空深处寻找系外行星数据
#We import libraries for linear algebra, graphs, and evaluation of results import numpy as np import ...
- 吴裕雄--天生自然 PYTHON数据分析:钦奈水资源管理分析
df = pd.read_csv("F:\\kaggleDataSet\\chennai-water\\chennai_reservoir_levels.csv") df[&quo ...
- 吴裕雄--天生自然 PYTHON数据分析:糖尿病视网膜病变数据分析(完整版)
# This Python 3 environment comes with many helpful analytics libraries installed # It is defined by ...
- 吴裕雄--天生自然 PYTHON数据分析:人类发展报告——HDI, GDI,健康,全球人口数据数据分析
import pandas as pd # Data analysis import numpy as np #Data analysis import seaborn as sns # Data v ...
- 吴裕雄--天生自然 python数据分析:医疗费数据分析
import numpy as np import pandas as pd import os import matplotlib.pyplot as pl import seaborn as sn ...
- 吴裕雄--天生自然 python数据分析:基于Keras使用CNN神经网络处理手写数据集
import pandas as pd import numpy as np import matplotlib.pyplot as plt import matplotlib.image as mp ...
- 吴裕雄--天生自然 PYTHON数据分析:医疗数据分析
import numpy as np # linear algebra import pandas as pd # data processing, CSV file I/O (e.g. pd.rea ...
随机推荐
- 漫谈设计模式(二):单例(Singleton)模式
1.前言 实际业务中,大多业务类只需要一个对象就能完成所有工作,另外再创建其他对象就显得浪费内存空间了,例如web开发中的servlet,这时便要用到单例模式,就如其名一样,此模式使某个类只能生成唯一 ...
- goweb-文本处理
文本处理 Web开发中对于文本处理是非常重要的一部分,我们往往需要对输出或者输入的内容进行处理,这里的文本包括字符串.数字.Json.XML等等.Go语言作为一门高性能的语言,对这些文本的处理都有官方 ...
- E. Delete a Segment(删除一个区间,让并区间最多)
题:https://codeforces.com/contest/1285/problem/E 题意:给定n个区间,最多删除一个区间,让最后的并区间个数最大 #include<bits/stdc ...
- BTree非递归
preorder void PreOrder(BTNode* b) { BTNode* p = b; SqStack* st; InitStack(st); if (b != NULL) { Push ...
- SaltStack事件驱动 – event reactor
Event是SaltStack里面的对每个事件的一个记录,它相比job更加底层,Event能记录更加详细的SaltStack事件,比如Minion服务启动后请求Master签发证书或者证书校验的过程, ...
- vue中axios的post请求使用form表单格式发送数据
vue使用插件qs实现 (qs 是一个增加了一些安全性的查询字符串解析和序列化字符串的库.) 在jquery中的ajax的方法已将此封装,所以不需要再次序列化 1. 安装 在项目中使用命令行工具输 ...
- Cesium 生成terrain地形数据----CTB方式及步骤
背景:项目前端使用Cesium,地形服务一直使用外网的,常常因为翻墙访问的问题,导致地形数据取不到,进而导致地球不能加载,故决定搭建自己的地形服务,彻底解决这个问题.博文包含以下几个过程: 下载原始地 ...
- Golang结构体值的交换
Golang结构体值的交换 一.添加结构体,多if暴力 最先遇到这个问题是在比编写PUT方法的接口时遇到. (我公司编写http put方法,是先解析json至StudentInput结构体中,通过i ...
- Python2 和 Python3的区别 更新中
py2和py3的区别 1.默认解释器编码 py2: ascii py3: utf-8 2.输入 输出 输入 py2: name = raw_input('请输入你的姓名:') py3: name = ...
- 树分治(挑战p360)
poj1741 题:http://poj.org/problem?id=1741 #include<iostream> #include<algorithm> #include ...