【Python3爬虫】你会怎么评价复仇者联盟4?
一、写在前面
最近复仇者联盟4正在热映中,很多人都去电影院观看了电影,那么对于这部电影,看过的人都是怎么评价的呢?这时候爬虫就可以派上用场了!
二、主要思路
首先打开豆瓣电影,然后进入复仇者联盟4的详情页面:https://movie.douban.com/subject/26100958/,下拉页面就可以找到这部电影的短评了:
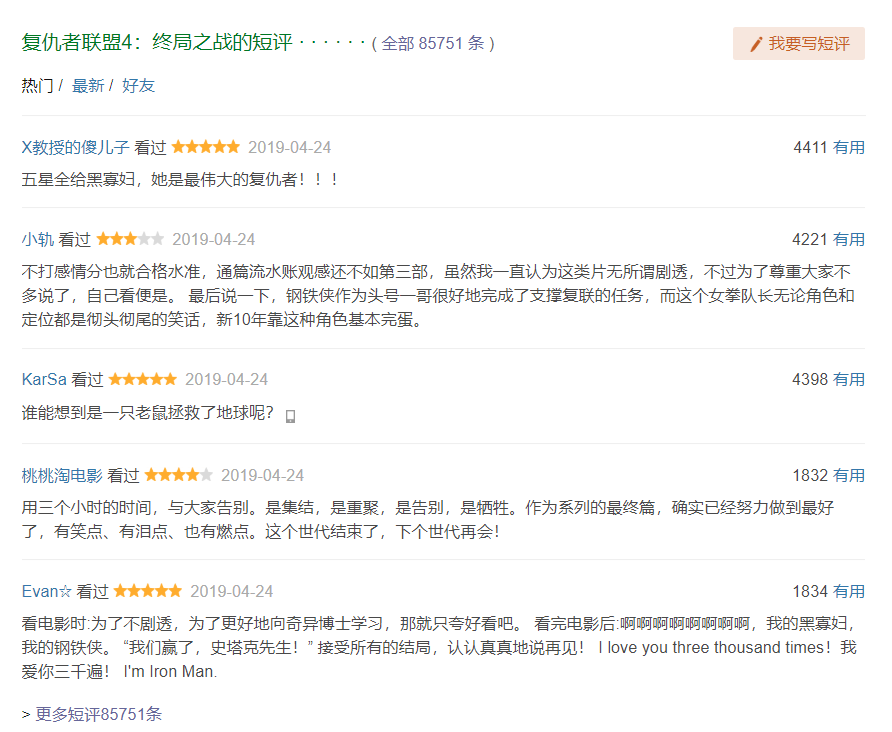
虽然它显示的短评有85751条,但是我们却没有办法获取所有的短评,在未登录的情况下只能看到200条短评,登录之后也只能得到500条短评,可是只有500条怎么够呢?所以我们得想办法得到尽量多的短评,思路为分别选择好评、一般、短评和最新,不过最新的短评只显示100条,所以我们能爬取的短评数量就是1600条。
当我们把短评爬取下来之后,可以先把短评数据保存到数据库中,然后再对这些短评进行分析。这里我选择用MongoDB数据库来保存数据,然后使用SnowNLP进行情感分析,再使用jieba分词和wordcloud生成词云。
三、主要代码
1.模拟登录
这一步是很重要的,我们需要带着登录之后的Cookie去发送请求才能得到数据,当然也可以打开浏览器登录之后复制Cookie,具体怎么做看个人喜好。登录豆瓣的url为:https://accounts.douban.com/passport/login?,抓一下包就知道怎么模拟登录了,并没有什么难度。代码如下:
def login(self):
"""
模拟登录
:return:
"""
url = "https://accounts.douban.com/j/mobile/login/basic"
data = {
"ck": "",
"name": self.username,
"password": self.password,
"remember": "false",
"ticket": ""
}
res = self.session.post(url, headers=self.headers, data=data)
print("登录成功!欢迎用户:", res.json()["payload"]["account_info"]["name"])
2.情感分析
SnowNLP是python中用来处理文本内容的,可以用来分词、标注、文本情感分析等,情感分析是简单的将文本分为两类,积极和消极,返回值为情绪的概率,越接近1为积极,接近0为消极。代码如下:
def analyze(self):
"""
情感分析
:return:
"""
result = self.col.find()
comments = []
for i in result:
comments.append(i["评论"])
sentiments_list = []
for i in comments:
s = SnowNLP(i)
sentiments_list.append(s.sentiments)
plt.hist(sentiments_list, bins=np.arange(0, 1, 0.01), facecolor="g")
plt.xlabel('Sentiments Probability')
plt.ylabel('Quantity')
plt.title('Analysis of Sentiments')
plt.savefig("Sentiments.png")
print("情感分析完毕,生成图片Sentiments.png")
3.生成词云
首先要用jieba对评论进行分词,然后我们要设置一些停用词,比如标点符号、“你”、“我”、“一部”、“电影”等词语,最后使用wordcloud模块生成词云图片。代码如下:
def generate(self):
"""
生成词云
:return:
"""
result = self.col.find()
comments = []
for i in result:
comments.append(i["评论"])
text = jieba.cut("\n".join(comments)) # 文本清洗,去除标点符号和长度为1的词
with open("stopwords.txt", "r", encoding='utf-8') as f:
stopwords = set(f.read().split("\n"))
stopwords.update({"一部", "一场", "电影", "小时", "分钟"})
# 使用图片
mask = np.array(Image.open("Avengers.jpg")) # 生成词云
wc = WordCloud(
mask=mask,
stopwords=stopwords,
font_path="font.ttf",
max_font_size=200,
min_font_size=20,
max_words=100,
width=1200,
height=800
)
wc.generate(' '.join(text))
wc.to_file('Avengers.png')
print("词云已生成,保存为Avengers.png。")
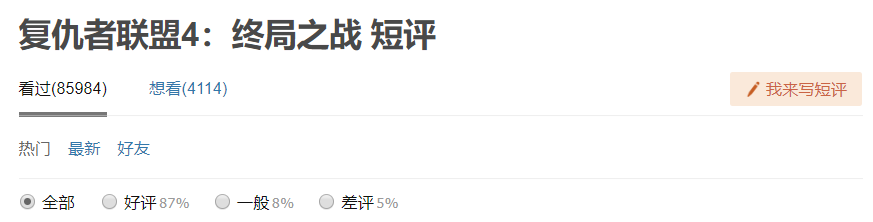
四、运行结果
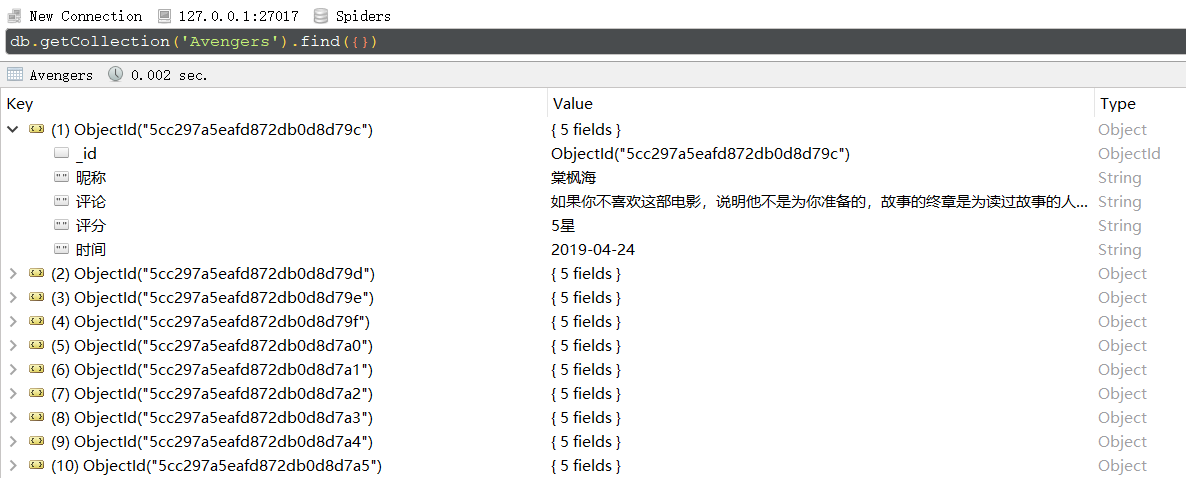
首先是进入MongoDB数据库查看数据:
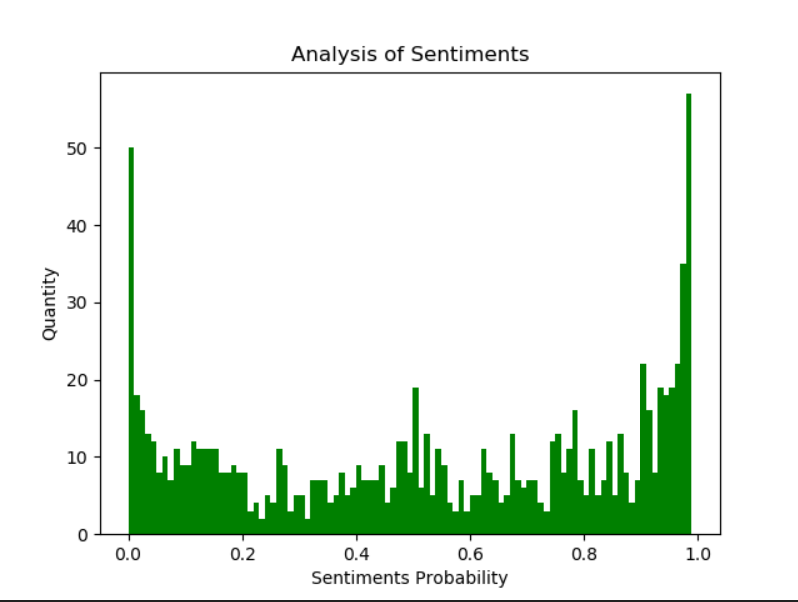
然后是使用SnowNLP进行情感分析得到的结果,可见很多人都是很喜欢复仇者联盟4的:
最后是生成的词云:

那么,对于看了电影的你,你会怎么评价这部电影呢?如果你没有看过,会不会想要买一张电影票去看看呢?
完整代码已上传到GitHub!
【Python3爬虫】你会怎么评价复仇者联盟4?的更多相关文章
- Python3爬虫系列:理论+实验+爬取妹子图实战
Github: https://github.com/wangy8961/python3-concurrency-pics-02 ,欢迎star 爬虫系列: (1) 理论 Python3爬虫系列01 ...
- python3爬虫中文乱码之请求头‘Accept-Encoding’:br 的问题
当用python3做爬虫的时候,一些网站为了防爬虫会设置一些检查机制,这时我们就需要添加请求头,伪装成浏览器正常访问. header的内容在浏览器的开发者工具中便可看到,将这些信息添加到我们的爬虫代码 ...
- Python3 爬虫之 Scrapy 核心功能实现(二)
博客地址:http://www.moonxy.com 基于 Python 3.6.2 的 Scrapy 爬虫框架使用,Scrapy 的搭建过程请参照本人的另一篇博客:Python3 爬虫之 Scrap ...
- Python3 爬虫之 Scrapy 框架安装配置(一)
博客地址:http://www.moonxy.com 基于 Python 3.6.2 的 Scrapy 爬虫框架使用,Scrapy 的爬虫实现过程请参照本人的另一篇博客:Python3 爬虫之 Scr ...
- python3爬虫--反爬虫应对机制
python3爬虫--反爬虫应对机制 内容来源于: Python3网络爬虫开发实战: 网络爬虫教程(python2): 前言: 反爬虫更多是一种攻防战,针对网站的反爬虫处理来采取对应的应对机制,一般需 ...
- python3爬虫系列19之反爬随机 User-Agent 和 ip代理池的使用
站长资讯平台:python3爬虫系列19之随机User-Agent 和ip代理池的使用我们前面几篇讲了爬虫增速多进程,进程池的用法之类的,爬虫速度加快呢,也会带来一些坏事. 1. 前言比如随着我们爬虫 ...
- python3爬虫(4)各种网站视频下载方法
python3爬虫(4)各种网站视频下载方法原创H-KING 最后发布于2019-01-09 11:06:23 阅读数 13608 收藏展开理论上来讲只要是网上(浏览器)能看到图片,音频,视频,都能够 ...
- Python3爬虫:(一)爬取拉勾网公司列表
人生苦短,我用Python 爬取原因:了解一下Python工程师在北上广等大中城市的薪资水平与入职前要求. Python3基础知识 requests,pyquery,openpyxl库的使用 爬取前的 ...
- 笔趣看小说Python3爬虫抓取
笔趣看小说Python3爬虫抓取 获取HTML信息 解析HTML信息 整合代码 获取HTML信息 # -*- coding:UTF-8 -*- import requests if __name__ ...
随机推荐
- python 定时服务模块
python定时任务使用方法如下: import sched shelder = sched.scheduler(time.time, time.sleep) shelder.enter(2, 0, ...
- sharesdk for android集成调试的几个问题
1.一定要下载最新版,这个东西目前版本升级很频繁,证明产品本身还不稳定,最新版bug会少一点 2.下载最新版SDK的时候,跟随下载最新Sample,官网文档的示例代码及时性很差. 3.调试的几个Key ...
- UE4学习心得:蓝图间信息通信的几种方法
蓝图间通信是一个复杂关卡能否正常运行的关键,笔者在这里提供几种蓝图类之间的信息交互方法,希望能对读者有所帮助. 1.类引用 这是最直接的一种蓝图类之间的信息交互方式.首先在Editor中创建2个Act ...
- springboot数据库连接池使用策略
springboot官方文档介绍数据库连接池的使用策略如下: Production database connections can also be auto-configured using a p ...
- 主成分分析PCA详解
转载请声明出处:http://blog.csdn.net/zhongkelee/article/details/44064401 一.PCA简介 1. 相关背景 上完陈恩红老师的<机器学习与知识 ...
- SSM-Spring-22:Spring+Mybatis+JavaWeb的整合
------------吾亦无他,唯手熟尔,谦卑若愚,好学若饥------------- 众所周知,框架Spring来整合别的框架,但是Mybatis出现的晚,Spring就没有给他提供支持,那怎么办 ...
- 使用Spring Session实现Spring Boot水平扩展
小编说:本文使用Spring Session实现了Spring Boot水平扩展,每个Spring Boot应用与其他水平扩展的Spring Boot一样,都能处理用户请求.如果宕机,Nginx会将请 ...
- webpack + vue 在dev和production模式下的小小区别
上周的某一天,和一位同样是前端技术极度爱好的开发者朋友聊天,他在提出了一个问题,他写的vue程序为什么在dev模式运行良好,而在production模式就直接报错了.这让我感到惊讶,还有这么神奇的事情 ...
- React从入门到放弃之前奏(2):React简介
本系列将尽可能使用ES6(ES2015)语法.所以均在上节webpack的基础上做开发. React是Facebook开发的一款JS库,因为基于Virtual DOM,所以响应速度快,以及支持跨平台. ...
- Python简介之输入和输出
输出 输入 输出 用print()在括号中加上字符串就可以向屏幕上输出指定的文字.比如输出'hello,world!',用代码实现如下:print('hello world!'). print()函数 ...