Python练习,网络小爬虫(初级)
最近还在看Python版的rcnn代码,附带练习Python编程写一个小的网络爬虫程序。
抓取网页的过程其实和读者平时使用IE浏览器浏览网页的道理是一样的。比如说你在浏览器的地址栏中输入 www.baidu.com 这个地址。打开网页的过程其实就是浏览器作为一个浏览的“客户端”,向服务器端发送了 一次请求,把服务器端的文件“抓”到本地,再进行解释、展现。HTML是一种标记语言,用标签标记内容并加以解析和区分。浏览器的功能是将获取到的HTML代码进行解析,然后将原始的代码转变成我们直接看到的网站页面。
统一资源标志符(Universal Resource Identifier, URI), 统一资源定位符(Uniform Resource Locator,URI),URL是URI的一个子集。
总的来说,网络爬虫的原理很简单,就是通过你事先给定的一个URL,从这个URL开始爬,下载每一个URL的HTML代码,根据你要抓取的内容,观察HTML代码的规律性,写出相应的正则表达式,将所需的内容的HTML代码抠出来,保存在列表中,并按具体要求处理扣出来的代码,这就是网络爬虫,其实就是一个对若干有规律的网页的HTML代码进行处理的程序。(当然,这只是简单的小爬虫,对于一些大型爬虫,可以设置有很多线程分别处理每一次获取到的URL地址)。其中要实现正则表达式的部分内容,应该导入re包,要实现URL的加载,阅读功能需要导入urllib2包。
显示网页代码:
import urllib2
response = urllib2.urlopen('http://www.baidu.com/')
html = response.read()
print html
当然,在请求服务器服务的过程中,也会产生异常:URLError在没有网络连接(没有路由到特定服务器),或者服务器不存在的情况下产生。
对网页的HTML代码进行处理:
import urllib2
import re
def getimg(html):
reg = r'src="(.+?\.jpg)" pic_ext'
imgre = re.compile(reg)
imglist = re.findall(imgre,html)
return imglist
上面代码找到参数HTML页面中所有图片的URL,并且分别保存在列表中,然后返回整个列表。程序执行结果如下:
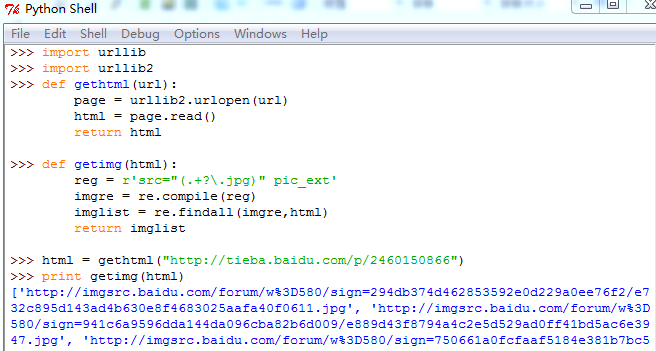
整篇文章比较低级,还望各位看官不吝赐教。除了程序中所用到了这些基本的方式,还有更强大的Python爬虫工具包Scrapy。
Python练习,网络小爬虫(初级)的更多相关文章
- Python 基于学习 网络小爬虫
<span style="font-size:18px;"># # 百度贴吧图片网络小爬虫 # import re import urllib def getHtml( ...
- 用Python写一个小爬虫吧!
学习了一段时间的web前端,感觉有点看不清前进的方向,于是就写了一个小爬虫,爬了51job上前端相关的岗位,看看招聘方对技术方面的需求,再有针对性的学习. 我在此之前接触过Python,也写过一些小脚 ...
- (数据科学学习手札31)基于Python的网络数据采集(初级篇)
一.简介 在实际的业务中,我们手头的数据往往难以满足需求,这时我们就需要利用互联网上的资源来获取更多的补充数据,但是很多情况下,有价值的数据往往是没有提供源文件的直接下载渠道的(即所谓的API),这时 ...
- 利用nodeJS实现的网络小爬虫
var http=require("http");var cheerio=require('cheerio');var url="http://www.imooc.com ...
- Python编程-一个小爬虫工具的实现过程
需求描述: 1,打开网站: 2,获取网站的文件内容: 3,返回保存到文件中: 这里的就用到了多线程的方法 import requests,threading,time def write_html(u ...
- (数据科学学习手札50)基于Python的网络数据采集-selenium篇(上)
一.简介 接着几个月之前的(数据科学学习手札31)基于Python的网络数据采集(初级篇),在那篇文章中,我们介绍了关于网络爬虫的基础知识(基本的请求库,基本的解析库,CSS,正则表达式等),在那篇文 ...
- 放养的小爬虫--京东定向爬虫(AJAX获取价格数据)
放养的小爬虫--京东定向爬虫(AJAX获取价格数据) 笔者声明:只用于学习交流,不用于其他途径.源代码已上传github.githu地址:https://github.com/Erma-Wang/Sp ...
- Python即时网络爬虫项目启动说明
作为酷爱编程的老程序员,实在按耐不下这个冲动,Python真的是太火了,不断撩拨我的心. 我是对Python存有戒备之心的,想当年我基于Drupal做的系统,使用php语言,当语言升级了,推翻了老版本 ...
- 【现学现卖】python小爬虫
1.给小表弟汇总一个院校列表,想来想去可以写一个小爬虫爬下来方便些,所以就看了看怎么用python写,到了基本能用的程度,没有什么特别的技巧,大多都是百度搜的,遇事不决问百度啦 2.基本流程就是: 用 ...
随机推荐
- 转:ibatis的cacheModel
转:ibatis的cacheModel cachemodel是ibatis里面自带的缓存机制,正确的应用能很好提升我们系统的性能. 使用方法:在sqlmap的配置文件中加入 <cacheMode ...
- 天猫登录源码 POST C#
HttpHelper 请从网络中搜索: public partial class LoginTMall : Form { public LoginTMall() { InitializeCompone ...
- uva10375 Choose and Divide(唯一分解定理)
uva10375 Choose and Divide(唯一分解定理) 题意: 已知C(m,n)=m! / (n!*(m-n!)),输入整数p,q,r,s(p>=q,r>=s,p,q,r,s ...
- jQuery插件入门
一:导言 有些WEB开发者,会引用一个JQuery类库,然后在网页上写一写("#"),("#"),("."),写了几年就对别人说非常熟悉JQ ...
- Simplify Path
Given an absolute path for a file (Unix-style), simplify it. For example, path = "/home/", ...
- Self-Host Web API 学习笔记
ASP.NET Web API 不需要 IIS,直接使用控制台程序可以实现. 一.创建一个新的控制台程序,项目名为 HostApi 二.设置目标框架为.NET Framework 4 三.NuGet添 ...
- 源码网站(msdn.itellyou.cn) good
verysource 100万源码http://www.verysource.com/category/delphi-vcl/ MSDN DOWNLOADhttp://msdn.itellyou.cn ...
- ORM系列之二:EF(2)Code First
目录 1. Code First是什么? 2. Code First 简单示例 3. 数据存储 4. 迁移 Code First是什么 Code First 顾名思义就是先写代码,当然不是乱写,而是按 ...
- Magento table rates表运费设置
在magento中集成了Table rate表运费,这种运输方式.表运费就是我们自己写个运费表,根据距离和商品重量设置运费,制做成一张csv格式的表,导入到magento中,来实现运费的控制. 在我的 ...
- CS193P - 2016年秋 第三讲 Swift 语言及 Foundation 框架
这一讲介绍一些 Swift 的重点概念.特别是一些有别于其它语言的地方.但本质上还都是语法糖. 想充分理解这一讲的内容,最好的方式就是 打开 playgound,亲自动手来实验. 1,Optional ...