PYTHON 爬虫笔记十:利用selenium+PyQuery实现淘宝美食数据搜集并保存至MongeDB(实战项目三)
利用selenium+PyQuery实现淘宝美食数据搜集并保存至MongeDB
目标站点分析
淘宝页面信息很复杂的,含有各种请求参数和加密参数,如果直接请求或者分析Ajax请求的话会很繁琐。所以我们可以用Selenium来驱动浏览器模拟点击来爬取淘宝的信息。这样我们只要关系操作,不用关心后台发生了怎样的请求。这样有个好处是:可以直接获取网页渲染后的源代码。输出 page_source 属性即可。
这样,我们就可以做到网页的动态爬取了。缺点是速度相比之下比较慢。
流程框架
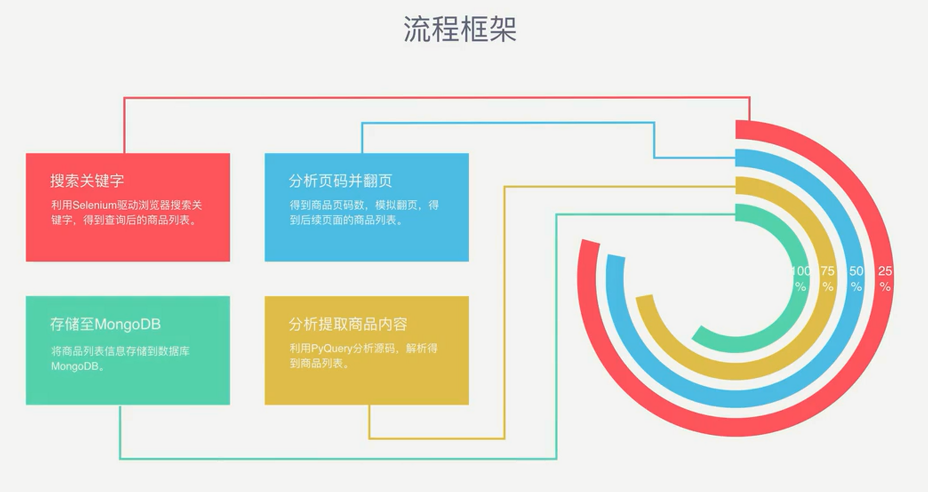
爬虫实战
spider详情页
import pymongo
import re from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from pyquery import PyQuery as pq
from config import *
import pymongo client = pymongo.MongoClient(MONGO_URL)
db = client[MONGO_DB] #browser = webdriver.Chrome()
browser = webdriver.PhantomJS(service_args=SERVICE_ARGS) #创建PhantomJS浏览器
wait = WebDriverWait(browser, 10) browser.set_window_size(1400,900)
def search(): #请求页面
print('正在搜索。。。')
try:
browser.get('https://world.taobao.com/') #请求淘宝首页
input = wait.until(
EC.presence_of_element_located((By.CSS_SELECTOR, '#mq'))
)
submit = wait.until(EC.element_to_be_clickable((By.CSS_SELECTOR,'#J_PopSearch > div.sb-search > div > form > input[type="submit"]:nth-child(2)')))
input.send_keys(KEYWORD)
submit.click()
total = wait.until(EC.presence_of_element_located((By.CSS_SELECTOR,'#mainsrp-pager > div > div > div > div.total')))
get_products()
return total.text
except TimeoutError:
total = search()
print(total) def next_page(page_number): #翻页操作
print('正在翻页。。。',page_number)
try:
input = wait.until(
EC.presence_of_element_located((By.CSS_SELECTOR, '#mainsrp-pager > div > div > div > div.form > input'))#判断页面是否加载出输入框
)
submit = wait.until(EC.element_to_be_clickable(
(By.CSS_SELECTOR, '#mainsrp-pager > div > div > div > div.form > span.btn.J_Submit'))) #判断是否加载出搜索按钮
input.clear()
input.send_keys(page_number)
submit.click()
wait.until(EC.text_to_be_present_in_element((By.CSS_SELECTOR,'#mainsrp-pager > div > div > div > ul > li.item.active > span'),str(page_number)))
#在做结果判断的时候,经常想判断某个元素中是否存在指定的文本,
get_products()
except TimeoutError:
next_page(page_number) def get_products():
wait.until(EC.presence_of_element_located((By.CSS_SELECTOR, '#mainsrp-itemlist .items .item')))
html = browser.page_source #获取详情页html代码
doc = pq(html) #创建一个Pyquery对象
items = doc('#mainsrp-itemlist .items .item').items() #css选择器获取所以items ,调用items方法取得所取的内容
for item in items:
producet = {
'title': item.find('.title').text(),
'location': item.find('.location').text(),
'price':item.find('.price').text(),
'deal':item.find('.deal-cnt').text()[:-3],
'shop':item.find('.shop').text(),
'image': item.find('.pic .img').attr('src'),
} print(producet)
save_to_monge(producet) def save_to_monge(result):
try:
if db[MONGO_TABLE].insert(result):
print('存储成功!',result)
except Exception:
print('存储失败!',result)
def main():
try:
total = search()
total = int(re.compile('(\d+)').search(total).group(1))
for i in range(2,total+1):
next_page(i)
except Exception:
print('出错啦')
browser.close() if __name__ == '__main__':
main()config配置页
MONGO_URL='localhost'
MONGO_DB='taobao'
MONGO_TABLE='taobao' SERVICE_ARGS = ['--load-images=false','--disk-cache=false'] KEYWORD ='美食'
PYTHON 爬虫笔记十:利用selenium+PyQuery实现淘宝美食数据搜集并保存至MongeDB(实战项目三)的更多相关文章
- Python爬虫实战八之利用Selenium抓取淘宝匿名旺旺
更新 其实本文的初衷是为了获取淘宝的非匿名旺旺,在淘宝详情页的最下方有相关评论,含有非匿名旺旺号,快一年了淘宝都没有修复这个. 可就在今天,淘宝把所有的账号设置成了匿名显示,SO,获取非匿名旺旺号已经 ...
- 利用Selenium爬取淘宝商品信息
一. Selenium和PhantomJS介绍 Selenium是一个用于Web应用程序测试的工具,Selenium直接运行在浏览器中,就像真正的用户在操作一样.由于这个性质,Selenium也是一 ...
- 爬虫实战4:用selenium爬取淘宝美食
方案1:一次性爬取全部淘宝美食信息 1. spider.py文件如下 __author__ = 'Administrator' from selenium import webdriver from ...
- 利用Selenium+java实现淘宝自动结算购物车商品(附源代码)
转载请声明原文地址! 本次的主题是利用selenium+java实现结算购买购物车中的商品. 话不多说,本次首先要注意的是谷歌浏览器的版本,浏览器使用的驱动版本,selenium的jar包版本. ...
- [Python爬虫] 之三十:Selenium +phantomjs 利用 pyquery抓取栏目
一.介绍 本例子用Selenium +phantomjs爬取栏目(http://tv.cctv.com/lm/)的信息 二.网站信息 三.数据抓取 首先抓取所有要抓取网页链接,共39页,保存到数据库里 ...
- [Python爬虫] 之十:Selenium +phantomjs抓取活动行中会议活动
一.介绍 本例子用Selenium +phantomjs爬取活动树(http://www.huodongshu.com/html/find_search.html?search_keyword=数字) ...
- PYTHON 爬虫笔记八:利用Requests+正则表达式爬取猫眼电影top100(实战项目一)
利用Requests+正则表达式爬取猫眼电影top100 目标站点分析 流程框架 爬虫实战 使用requests库获取top100首页: import requests def get_one_pag ...
- PYTHON 爬虫笔记九:利用Ajax+正则表达式+BeautifulSoup爬取今日头条街拍图集(实战项目二)
利用Ajax+正则表达式+BeautifulSoup爬取今日头条街拍图集 目标站点分析 今日头条这类的网站制作,从数据形式,CSS样式都是通过数据接口的样式来决定的,所以它的抓取方法和其他网页的抓取方 ...
- 利用selenium自动化登录淘宝
#encoding=utf-8 from selenium import webdriver from selenium.webdriver.common.action_chains import A ...
随机推荐
- POJ 3181 Dollar Dayz(全然背包+简单高精度加法)
POJ 3181 Dollar Dayz(全然背包+简单高精度加法) id=3181">http://poj.org/problem?id=3181 题意: 给你K种硬币,每种硬币各自 ...
- 搭建rocketMq环境
大体流程按照文章https://blog.csdn.net/wangmx1993328/article/details/81536168逐步搭建,下面列出踩过的一些坑 1,自己的阿里云服务器端口没开放 ...
- Win7如何自定义鼠标右键菜单 添加用记事本打开
鼠标右键用记事本打开.reg Windows Registry Editor Version 5.00 [HKEY_CLASSES_ROOT\*\shell\Notepad] @="用记事本 ...
- project 的用法
任务和子任务,树状结构: 点击一个绿色的箭头就可以实现. 时间的话:视图→甘特图→双击“开始时间”修改即可
- C语言数据类型的转换
C语言的类型转换,一个是强制类型进行转换,而在这里要介绍的是自动的数据类型的转换,自动的数据类型转换很多时候是发生在多种数据类型混合使用的时候就会进行类型的转换,这样就会带来不能控制的结果,所以必须进 ...
- iOS中UDP的使用
// // ViewController.m // UDPDemo // // Created by qianfeng01 on 15-8-13. // Copyright (c) 2015年 ...
- kernel&uboot学习笔记
uboot kernel uboot 1.Uboot编译流程分析: uboot是如何编译生成的? 2.根据include/configs/$(target).h可以生成include/autoconf ...
- 图像检测之sift and surf---sift中的DOG图 surf hessian
http://www.cnblogs.com/tornadomeet/archive/2012/08/17/2644903.html http://www.cnblogs.com/slysky/arc ...
- [Python]xlrd 读取excel 日期类型2种方式
有个excle表格须要做一些过滤然后写入数据库中,可是日期类型的cell取出来是个数字,于是查询了下解决的办法. 主要的代码结构 data = xlrd.open_workbook(EXCEL_PAT ...
- Oracle的循环和Corsor
这两天啊有一个心的业务,是须要假设我批量改动数据的话,那么还有一张表的数据也须要改动.也是多条的改动,发现这个问题的时候.自然而然的想到了触发器,可是曾经都是简单的单条语句的跟新,没有过整个表的去做一 ...