[Python爬虫] 之三十:Selenium +phantomjs 利用 pyquery抓取栏目
一、介绍
本例子用Selenium +phantomjs爬取栏目(http://tv.cctv.com/lm/)的信息
二、网站信息


三、数据抓取
首先抓取所有要抓取网页链接,共39页,保存到数据库里面
def getUrls(self):
urls = []
urls.append('http://tv.cctv.com/lm/')
for index in range(2,40):
urls.append("javascript:window.scroll(0,145);DataInteraction({0});showPageTitle_fenyei2('ELMT1413526954890942',{0});".format(index))
self.db.SaveCCTVColumnUrls(urls,'')
针对上面的网站信息,来进行抓取
1、首先抓取信息列表
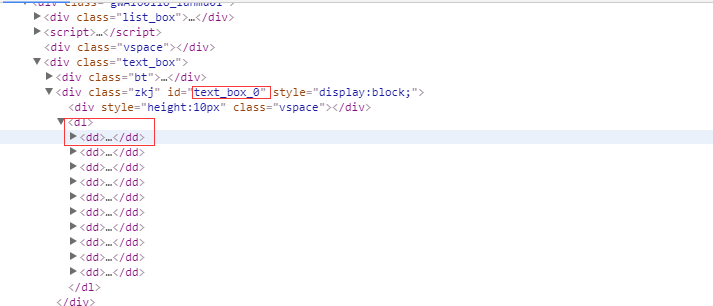
抓取代码:Elements = doc("div[id='text_box_0']").find('dl').find('dd')
2、栏目名称,链接
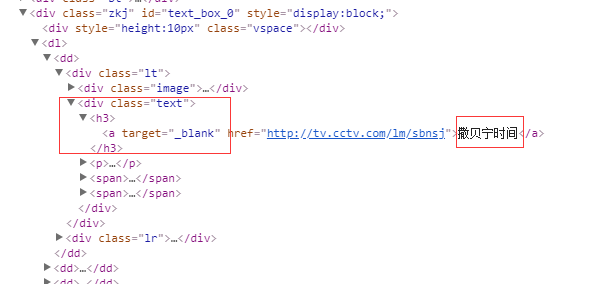
column1Element = element.find('div[class="text"]').find('h3').find('a')
columnName = column1Element.text().encode('utf8').replace(',', ',').replace('\n', '')
columnUrl = column1Element.attr('href')
四,实现代码
# coding=utf-8
import os
import re
from selenium import webdriver
from selenium.common.exceptions import TimeoutException
from datetime import datetime,timedelta
import selenium.webdriver.support.ui as ui
import time
from pyquery import PyQuery as pq
import columnData
import mongoDB
class cctvColumnInfo: def __init__(self):
#通过配置文件获取IEDriverServer.exe路径
# self.urls = self.getUrls()
# IEDriverServer ='C:\Program Files\Internet Explorer\IEDriverServer.exe'
# self.driver = webdriver.Ie(IEDriverServer)
# self.driver.maximize_window()
self.driver = webdriver.PhantomJS(service_args=['--load-images=false'])#service_args=['--load-images=false']
self.driver.set_page_load_timeout(10)
self.driver.maximize_window()
self.db = mongoDB.mongoDbBase() def WriteUrl(self,url):
fileName = os.path.join(os.getcwd(), 'cctvColumn/cctvColumn_url.txt')
with open(fileName, 'a') as f:
f.write('\n'+url) def getUrls(self):
urls = []
urls.append('http://tv.cctv.com/lm/')
for index in range(2,40):
urls.append("javascript:window.scroll(0,145);DataInteraction({0});showPageTitle_fenyei2('ELMT1413526954890942',{0});".format(index))
self.db.SaveCCTVColumnUrls(urls,'')
# return urls def WriteLog(self, message,date):
fileName = os.path.join(os.getcwd(), 'cctvColumn/cctvColumn-'+date + '.txt')
with open(fileName, 'a') as f:
f.write(message) def getColumnInfo(self, colInfo):
ts = colInfo.split('主持人')
firstBroadcastTime = ts[0]
ts1 = ts[1].split('播出频道')
columnHost = '主持人' + ts1[0]
broadcastChannel = '播出频道' + ts1[1]
return firstBroadcastTime, columnHost, broadcastChannel def CatchData(self): urlIndex = 0
urls = self.db.GetCCTVColumnUrls()
itemIndex = 0
for u in urls:
url = u['url']
try:
if url == 'http://tv.cctv.com/lm/':
self.driver.get(url)
else:
self.driver.execute_script(url)
urlIndex += 1
time.sleep(2)
selenium_html = self.driver.execute_script("return document.documentElement.outerHTML")
doc = pq(selenium_html)
# Elements = doc("div[@id='text_box_0']/dl/dd")
Elements = doc("div[id='text_box_0']").find('dl').find('dd')
message = '' # for element in Elements:
column_name = url.encode('utf8')
print url
for element in Elements.items():
colobj = columnData.columnData()
itemIndex+=1
firstBroadcastTime = ''
ReplayBroadcastTime = ''
firstBroadcastChannel = ''
# column1Element = element.find('div[@class="text"]/h3/a')
# column1Element = element.find_element_by_xpath("//div[@class='ui-page-next']")
column1Element = element.find('div[class="text"]').find('h3').find('a')
columnName = column1Element.text().encode('utf8').replace(',', ',').replace('\n', '')
columnUrl = column1Element.attr('href') colobj.setColumnName(columnName)
colobj.setColumnUrl(columnUrl)
column_name += '\n' + columnName
# time.sleep(3)
print columnName # column2Element = element.find('div[@class="text"]/p/a')
column2Element = element.find('div[class="text"]').find('p').find('a')
columnTimeName = column2Element.text().encode('utf8').replace(',', ',').replace('\n', '')
columnTimeUrl = column2Element.attr('href')
colobj.setColumnTimeName(columnTimeName)
colobj.setColumnTimeUrl(columnTimeUrl)
# print columnTimeName + '; ' + columnTimeUrl # column34Elements = element.find('div[@class="text"]/span/a')
column34Elements = element.find('div[class="text"]').find('span').find('a') # for column34Element in column34Elements:
column34Index = 0
pastVideoUrl = ''
officialWebsiteUrl = ''
for column34Element in column34Elements.items():
if column34Index == 0:
pastVideoUrl = column34Element.attr('href')
colobj.setPastVideoUrl(pastVideoUrl)
else:
officialWebsiteUrl = column34Element.attr('href')
colobj.setOfficialWebsiteUrl(officialWebsiteUrl)
column34Index += 1 # columnImageElement = element.find('div[@class="img"]/a/img')
columnImageElement = element.find('div[class="img"]').find('a').find('img')
colImgUrl = columnImageElement.attr('src') if colImgUrl == None:
columnImageElement = element.find('div[class="image"]').find('a').find('img')
colImgUrl = columnImageElement.attr('src')
# print colImgUrl
colobj.setColImgUrl(colImgUrl)
# 首播时间
firstBroadcastTime1 = ''
# 主持人
columnHost = ''
# 播出频道
firstBroadcastChannel1 =''
# columnInfos = element.find('div[@class="lr"]/div')
columnInfos = element.find('div[class="lr"]').find('div')
if columnInfos:
for colInfo in columnInfos.items():
firstBroadcastTime1, columnHost, firstBroadcastChannel1 = self.getColumnInfo(
colInfo.text().encode('utf8').replace(',', ',').replace('\n', ''))
columnHost = columnHost.replace(',', ',')
if not firstBroadcastTime:
firstBroadcastTime = firstBroadcastTime1
if not firstBroadcastChannel:
firstBroadcastChannel = firstBroadcastChannel1
colobj.setColumnHost(columnHost)
colobj.setFirstBroadcastChannel(firstBroadcastChannel1)
colobj.setFirstBroadcastTime(firstBroadcastTime1)
# 栏目名称,首播时间,重播时间,播出频道,主持人,栏目url,栏目名称1(带时间的),栏目名称1url,往期视频url,栏目官网url,),栏目对应图片url
mess = '\n{0},{1},{2},{3},{4},{5},{6},{7},{8},{9},{10}'.format(columnName, firstBroadcastTime,
ReplayBroadcastTime,
firstBroadcastChannel, columnHost,
columnUrl, columnTimeName,
columnTimeUrl, pastVideoUrl,
officialWebsiteUrl, colImgUrl) # print mess
message += mess self.db.SaveCCTVColumnData(colobj,itemIndex)
self.db.SaveCCTVColumnUrl(columnUrl, '', columnName) date = time.strftime('%Y-%m-%d')
self.WriteLog(message, date)
self.WriteUrl(column_name)
self.db.SetCCTVColumnUrlCrawlState(url)
except TimeoutException,e:
print 'timeout url: '+url self.driver.close()
self.driver.quit() def getBroadCast(self):
urls = self.db.GetSubCCTVColumnUrls() for u in urls:
firstBroadcastTime = ''
ReplayBroadcastTime = ''
firstBroadcastChannel = ''
messsage = ''
url = u['url']
# url='http://tv.cctv.com/lm/xqds'
# url='http://tv.cctv.com/lm/24xiaoshi/'
columnName = u['columnName'] # u'http://tv.cctv.com/lm/kanjian'
try:
self.driver.get(url)
time.sleep(2)
selenium_html = self.driver.execute_script("return document.documentElement.outerHTML")
doc = pq(selenium_html)
Elements = doc("p[class='p_1']") index = 0
for element in Elements.items():
if index == 0:
firstBroadcastTime = element.text().encode('utf8').replace(',', ',').replace('\n', '')
elif index == 1:
ReplayBroadcastTime = element.text().encode('utf8').replace(',', ',').replace('\n', '')
elif index == 2:
firstBroadcastChannel = element.text().encode('utf8').replace(',', ',').replace('\n', '')
break
index += 1
if index == 0:
Elements = doc("div[class='head_msg']").find('table').find('tbody').find('tr') for element in Elements.items():
messsage+=element.text().encode('utf8').replace(',', ',').replace('\n', '') if messsage:
firstBroadcastTime, ReplayBroadcastTime, firstBroadcastChannel= self.getBroadInfo(columnName.encode('utf8'),messsage)
self.db.SetCCTVColumnUrlCrawlState(url) if firstBroadcastChannel:
colobj = columnData.columnData()
colobj.setColumnName(columnName)
colobj.setFirstBroadcastTime(firstBroadcastTime)
colobj.setFirstBroadcastChannel(firstBroadcastChannel)
colobj.setReplayBroadcastTime(ReplayBroadcastTime)
self.db.UpdateCCTVColumnData(colobj)
print '\n'
print url
print columnName
print firstBroadcastTime
print firstBroadcastChannel
print ReplayBroadcastTime except TimeoutException, e:
print 'TimeoutException:'+url def getBroadInfo(self,columnName,column):
# column ='首播频道: CCTV-14首播时间: 周三17:15'
firstBroadcastTime = ''
ReplayBroadcastTime = ''
firstBroadcastChannel = ''
column=column.replace('栏目大全','')
if '>>' in column:
index = column.index('>>')
column = column[0:index] if 'CCTV13' in column:
column = column.replace('CCTV13', 'CCTV-13')
if 'CCTV6' in column:
column = column.replace('CCTV6', 'CCTV-6')
if 'CCTV1' in column:
column = column.replace('CCTV1','CCTV-1') if '官方微信' in column:
index = column.index('官方微信')
column = column[0:index] # if '停播' in column or '关闭' in column:
# return firstBroadcastTime, ReplayBroadcastTime, firstBroadcastChannel
# elif '>>' in column:
# index = column.index('>>')
# column = column[0:index] if '首播时间' in column:
if '重播时间' in column:
cols = column.split('重播时间')
firstBroadcastTime = cols[0]
if '独播频道' in cols[1]:
ReplayBroadcastTime = '重播时间' + cols[1].split('独播频道')[0]
firstBroadcastChannel = '独播频道' + cols[1].split('独播频道')[1]
elif '首播频道' in cols[1]:
ReplayBroadcastTime = '重播时间' + cols[1].split('首播频道')[0]
firstBroadcastChannel = '首播频道' + cols[1].split('首播频道')[1] elif '播出频道' in cols[1]:
ReplayBroadcastTime = '重播时间' + cols[1].split('播出频道')[0]
firstBroadcastChannel = '播出频道' + cols[1].split('播出频道')[1]
elif '独播频道' in column:
cols = column.split('独播频道')
firstBroadcastTime = cols[0]
firstBroadcastChannel = '独播频道' + cols[1]
elif '播出频道' in column:
cols = column.split('播出频道')
firstBroadcastTime = cols[0]
firstBroadcastChannel = '播出频道' + cols[1] elif '首播频道' in column:
cols = column.split('首播频道')
index = column.index('首播频道')
if index==0:
cols = column.split('首播时间')
firstBroadcastChannel = cols[0]
firstBroadcastTime = '首播时间' + cols[1]
else:
firstBroadcastTime = cols[0]
firstBroadcastChannel = '首播频道' + cols[1]
else:
if '首播(' in column and '重播(' in column:
if '独播频道' in column:
cols = column.split('独播频道')
firstBroadcastChannel = '独播频道' + cols[1]
firstBroadcastTime = cols[0]
# '首播(生活): 一-六18:52 日18:42重播(生活): 一-五 日16:08首播(文史): 一-五22:43六日22:33/30重播(文史): 二-五06:46六日06:24'
if '(生活版)' in columnName:
if '首播(文史)' in firstBroadcastTime:
temp = firstBroadcastTime.split('首播(文史)')[0]
if '重播(生活)' in temp:
firstBroadcastTime = '首播时间: '+temp.split('重播(生活)')[0].replace('首播(生活): ','')
ReplayBroadcastTime = '重播时间: '+temp.split('重播(生活)')[1].replace(': ','') # 首播(文史): 一-五22:43六日22:33/30重播(文史): 二-五06:46六日06:24首播(生活): 一-六18:52 日18:42重播(生活): 一-五 日16:08
elif '(文史版)' in columnName:
if '首播(生活)' in firstBroadcastTime:
temp = firstBroadcastTime.split('首播(生活)')[0]
if '重播(文史)' in temp:
firstBroadcastTime = '首播时间: '+temp.split('重播(文史)')[0].replace('首播(文史): ','')
ReplayBroadcastTime = '重播时间: '+ temp.split('重播(文史)')[1].replace(': ','') elif '播出频道' in column:
cols = column.split('播出频道')
firstBroadcastTime = cols[0]
firstBroadcastChannel = '播出频道' + cols[1] elif '首播频道' in column:
cols = column.split('首播频道')
firstBroadcastTime = cols[0]
firstBroadcastChannel = '首播频道' + cols[1]
return firstBroadcastTime,ReplayBroadcastTime,firstBroadcastChannel def exportColumnInfo(self):
columns = self.db.GetCCTVColumnData() for col in columns:
columnName = col['columnName'].encode('utf8')
firstBroadcastTime = col['firstBroadcastTime'].encode('utf8')
firstBroadcastTime=firstBroadcastTime.replace('首播时间: ','') firstBroadcastChannel = col['firstBroadcastChannel'].encode('utf8').replace("播出频道:", "").replace("独播频道:", "").replace("首播频道:", "")
firstBroadcastChannel =firstBroadcastChannel.replace(")","").replace("(","").replace("CCTV-8电视剧","CCTV-8 电视剧")
firstBroadcastChannel = firstBroadcastChannel.replace("CCTV-1综合频道", "CCTV-1 综合频道")
firstBroadcastChannel = firstBroadcastChannel.replace("CCTV-1高清频道", "CCTV-1 高清频道")
firstBroadcastChannel = firstBroadcastChannel.replace("CCTV13", "CCTV-13")
firstBroadcastChannel = firstBroadcastChannel.replace("CCTV1", "CCTV-1")
firstBroadcastChannel = firstBroadcastChannel.replace("CCTV-少儿", "CCTV-14 少儿")
firstBroadcastChannel = firstBroadcastChannel.replace("CCTV6", "CCTV-6")
firstBroadcastChannel = firstBroadcastChannel.replace("CCTV-12社会与法", "CCTV-12 社会与法") replayBroadcastTime = col['replayBroadcastTime'].encode('utf8')
replayBroadcastTime = replayBroadcastTime.replace('重播时间:', '')
columnHost = col['columnHost'].encode('utf8')
columnUrl = col['columnUrl'].encode('utf8')
columnTimeName = col['columnTimeName'].encode('utf8')
columnTimeUrl = col['columnTimeUrl']
if columnTimeUrl:
columnTimeUrl = columnTimeUrl.encode('utf8')
officialWebsiteUrl = col['officialWebsiteUrl'].encode('utf8')
pastVideoUrl = col['pastVideoUrl'].encode('utf8')
colImgUrl = col['colImgUrl'].encode('utf8') # 栏目名称,首播时间,重播时间,播出频道,主持人,栏目url,栏目名称1(带时间的),栏目名称1url,往期视频url,栏目官网url,),栏目对应图片url
message = '\n{0},{1},{2},{3},{4},{5},{6},{7},{8},{9},{10}'.format(columnName, firstBroadcastTime,
replayBroadcastTime,
firstBroadcastChannel, columnHost,
columnUrl, columnTimeName,
columnTimeUrl, pastVideoUrl,
officialWebsiteUrl, colImgUrl) date = time.strftime('%Y-%m-%d')
self.WriteLog(message, date) obj = cctvColumnInfo()
# obj.getUrls()
# obj.CatchData()
# obj.getBroadCast()
obj.exportColumnInfo()
# coding=utf-8
import os
from pymongo import MongoClient
from pymongo import ASCENDING, DESCENDING
import codecs
import time
import columnData
import datetime
import re class mongoDbBase:
# def __init__(self, databaseIp = '127.0.0.1',databasePort = 27017,user = "ott",password= "ott", mongodbName='OTT_DB'):
def __init__(self, connstr='mongodb://ott:ott@127.0.0.1:27017/', mongodbName='OTT'):
# client = MongoClient(connstr)
# self.db = client[mongodbName]
client = MongoClient('127.0.0.1', 27017)
self.db = client.OTT
self.db.authenticate('ott', 'ott') def SaveCCTVColumnData(self,columnData,index):
count = self.db.column_data.find({'columnName': columnData.getColumnName()}).count()
if count == 0:
dictM ={'columnName':columnData.getColumnName(),
'firstBroadcastTime':columnData.getFirstBroadcastTime(),
'replayBroadcastTime':'',
'firstBroadcastChannel':columnData.getFirstBroadcastChannel(),
'columnHost':columnData.getColumnHost(),
'columnUrl':columnData.getColumnUrl(),
'columnTimeName':columnData.getColumnTimeName(),
'columnTimeUrl':columnData.getColumnTimeUrl(),
'officialWebsiteUrl':columnData.getOfficialWebsiteUrl(),
'pastVideoUrl': columnData.getPastVideoUrl(),
'colImgUrl':columnData.getColImgUrl(),
'index':index}
self.db.column_data.insert(dictM) def GetCCTVColumnData(self):
columns = self.db.column_data.find({},{'_id':0})
return columns def UpdateCCTVColumnData(self, columnData):
dictM ={'$set':{'replayBroadcastTime':columnData.getReplayBroadcastTime(),
'firstBroadcastTime':columnData.getFirstBroadcastTime(),
'firstBroadcastChannel': columnData.getFirstBroadcastChannel()}}
self.db.column_data.update({"columnName":columnData.getColumnName()},dictM) def SaveCCTVColumnUrl(self, url,suburl,columnName):
dictM = {'url': url, 'iscrawl': '','suburl':suburl,'columnName':columnName}
# db.urls.find({iscrawl:'1'}).count()
count = self.db.columnurls.find({'url': url}).count()
if count == 0:
self.db.columnurls.insert(dictM) def SaveCCTVColumnUrls(self, urlList,suburl):
index = 0
for url in urlList: # db.urls.find({iscrawl:'1'}).count()
count = self.db.columnurls.find({'url': url}).count()
if count == 0:
dictM = {'url': url, 'iscrawl': '', 'suburl': suburl,'index':index}
self.db.columnurls.insert(dictM)
index += 1
# self.db.Meeting.update({'title': meet["title"],'date': meet["date"]}, {'$set': dictM}, {'upsert': True}) def GetCCTVColumnUrls(self):
urls = self.db.columnurls.find({'iscrawl': '','suburl':''}, {'_id': 0, 'url': 1})
# for url in urls:
# #http://top.chinaz.com/hangye/index_yule.html
# print urls['url']
# break
return urls def GetSubCCTVColumnUrls(self):
urls = self.db.columnurls.find({'iscrawl': '', 'suburl': ''}, {'_id': 0, 'url': 1,'columnName':1})
# urls = self.db.columnurls.find({'firstBroadcastChannel': re.compile('栏目'), 'suburl': '1'}, {'_id': 0, 'url': 1, 'columnName': 1})
return urls
# def SetUrlCrawlState(self,urlList):
# for url in urlList:
# self.db.urls.update({'url':url},{'$set':{'iscrawl':'1'}}) def SetCCTVColumnUrlCrawlState(self, url):
# db.urls.update({iscrawl:'1'},{'$set':{iscrawl:'0'}},false,true)
self.db.columnurls.update({'url': url}, {'$set': {'iscrawl': ''}}) # d = mongoDbBase() # urls = []
# urls.append('abc')
# # d.SaveUrls(urls)
# d.SetUrlCrawlState(urls)
def download(self, url, name):
try:
# url='http://pp.myapp.com/ma_icon/0/icon_10910_1523714409/96'
# name='D:\work\python_crawl\down\2019.jpg'
pic = requests.get(url, timeout=5)
with open(name, 'wb') as f:
f.write(pic.content)
except requests.exceptions.ConnectionError:
print('当前图片无法下载')
[Python爬虫] 之三十:Selenium +phantomjs 利用 pyquery抓取栏目的更多相关文章
- [Python爬虫] 之三十一:Selenium +phantomjs 利用 pyquery抓取消费主张信息
一.介绍 本例子用Selenium +phantomjs爬取央视栏目(http://search.cctv.com/search.php?qtext=消费主张&type=video)的信息(标 ...
- [Python爬虫] 之十六:Selenium +phantomjs 利用 pyquery抓取一点咨询数据
本篇主要是利用 pyquery来定位抓取数据,而不用xpath,通过和xpath比较,pyquery效率要高. 主要代码: # coding=utf-8 import os import re fro ...
- [Python爬虫] 之二十五:Selenium +phantomjs 利用 pyquery抓取今日头条网数据
一.介绍 本例子用Selenium +phantomjs爬取今日头条(http://www.toutiao.com/search/?keyword=电视)的资讯信息,输入给定关键字抓取资讯信息. 给定 ...
- [Python爬虫] 之二十二:Selenium +phantomjs 利用 pyquery抓取界面网站数据
一.介绍 本例子用Selenium +phantomjs爬取界面(https://a.jiemian.com/index.php?m=search&a=index&type=news& ...
- [Python爬虫] 之二十九:Selenium +phantomjs 利用 pyquery抓取节目信息信息
一.介绍 本例子用Selenium +phantomjs爬取节目(http://tv.cctv.com/epg/index.shtml?date=2018-03-25)的信息 二.网站信息 三.数据抓 ...
- [Python爬虫] 之二十八:Selenium +phantomjs 利用 pyquery抓取网站排名信息
一.介绍 本例子用Selenium +phantomjs爬取中文网站总排名(http://top.chinaz.com/all/index.html,http://top.chinaz.com/han ...
- [Python爬虫] 之二十四:Selenium +phantomjs 利用 pyquery抓取中广互联网数据
一.介绍 本例子用Selenium +phantomjs爬取中广互联网(http://www.tvoao.com/select.html)的资讯信息,输入给定关键字抓取资讯信息. 给定关键字:数字:融 ...
- [Python爬虫] 之十九:Selenium +phantomjs 利用 pyquery抓取超级TV网数据
一.介绍 本例子用Selenium +phantomjs爬取超级TV(http://www.chaojitv.com/news/index.html)的资讯信息,输入给定关键字抓取资讯信息. 给定关键 ...
- [Python爬虫] 之十八:Selenium +phantomjs 利用 pyquery抓取电视之家网数据
一.介绍 本例子用Selenium +phantomjs爬取电视之家(http://www.tvhome.com/news/)的资讯信息,输入给定关键字抓取资讯信息. 给定关键字:数字:融合:电视 抓 ...
随机推荐
- Java学习笔记(十三)——通过Netbeans开发环境生成oracle数据库中表的对应hibernate映射文件
[前面的话] 身体慢慢已经快好了,感觉真好,哈哈. 这篇文章要通过Hibernate对数据库进行操作,而Netbeans可以直接通过数据库逆向生成对应的映射文件.基础文章,选择性阅读. [步骤] 1. ...
- bzoj1597 斜率优化dp
思路:先把没有用的土地去掉,然后按照x轴排序,容易得到dp转移方程 dp[ i ] = min{ dp[ j ] + b[ j + 1 ] * a[ i ] } 0 <= j < i ...
- ZOJ 3279-Ants(线段树)
传送门:zoj 3279 Ants Ants Time Limit: 2 Seconds Memory Limit: 32768 KB echo is a curious and cleve ...
- HDU 4863 Centroid of a Tree
树的重心,树形$dp$,背包. 树的重心有两个充分必要条件: $1$.某树有两个重心$a$,$b$ $<=>$ $a$与$b$相邻,断开$a$与$b$之间的边之后,两个联通分量内的点的个数 ...
- MYSQL注入天书之基础知识
第一部分/page-1 Basic Challenges Background-1 基础知识 此处介绍一些mysql注入的一些基础知识. (1)注入的分类---仁者见仁,智者见智. 下面这个是阿德玛表 ...
- Flask实战第58天:发布帖子功能完成
发布帖子后台逻辑完成 首先给帖子设计个模型,编辑apps.models.py class PostModel(db.Model): __tablename__ = 'post' id = db.Col ...
- Windows命令远程执行工具Winexe
Windows命令远程执行工具Winexe 在对Windows系统执行渗透测试中,通过各种方式可以获取目标主机的用户名和密码.这时,只要对方主机开启文件共享服务,就可以借助Winexe工具远程执行 ...
- Arduino可穿戴开发入门教程LilyPad介绍
Arduino可穿戴开发入门教程LilyPad介绍 Arduino输出模块 LilyPad官方共提供了4种输出模块,他们分别是单色LED模块(图1.5).三色LED模块(图1.6).蜂鸣器模块(图1. ...
- Knockout.js(一):简介
Knockout是一款很优秀的JavaScript库,通过应用MVVM模式使JavaScript前端UI简单化.任何时候你的局部UI内容需要自动更新,KO都可以很简单的帮你实现,并且非常易于维护. K ...
- ES5 的 Array
1: Array.isArray判断是否为数组 Array.isArray([1, 2, 3]); // true Array.isArray({foo: 123}); // false // Pol ...