django_celery_results安装的坑
前言
在Celery4.0之前的版本中,有一个专门供Django使用的Celery版本django-celery.但现在Celery已经统一为一个版本,所以直接安装原生的Celery即可。这里就暂时不说Celery的使用方法了,改天专门写。今天只说说django-celery-results。
作用
这个扩展允许您使用Django ORM存储Celery任务结果。
它定义了一个用于存储任务结果的模型(django_celery_results.models.TaskResult),您可以像查询其他Django模型一样查询这个数据库表。
安装
直接pip安装:
pip install django-celery-results```
源码安装:从[GitHub](http://pypi.python.org/pypi/django-celery-results)下载最新版本的django-celery-results,然后通过执行以下操作来安装它
$ tar xvfz django-celery-results-0.0.0.tar.gz
$ cd django-celery-results-0.0.0
$ python setup.py build```
迁移---坑王驾到
一般建议python manage.py migrate django_celery_results,但我个人建议还是先python manage.py makemigrations,然后再migrate。如果顺利的话,那肯定是美滋滋,但问题是不顺利(悲痛的表情)
我自己遇到的问题如下:

迁移文件有错,然后本人就习惯性的打开了百度。各种关键词搜索,发现竟然没有答案。然后就突然顿悟了,我还是自己盘他吧。然后又仔细的看了一遍这个错误,发现他告诉我的是依赖项引用不存在的父节点,然后我就打开了这个文件,我的路径是C:\Python27\Lib\site-packages\django_celery_results\migrations\出错的文件
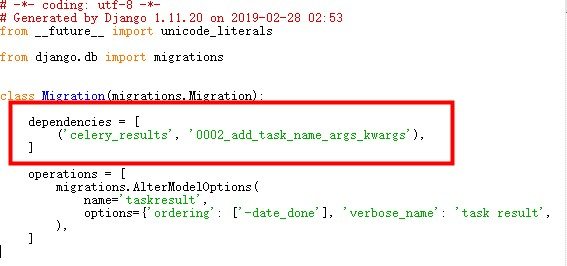
果不其然,与Error一样,然后我就好奇。。。然后我应该干啥呢(又一个悲痛的表情),突然我又顿悟了我还是去GitHub吧,真的发现了一个相似的问题,虽然她告诉的解决方法,对我没用,但她说明了原因。
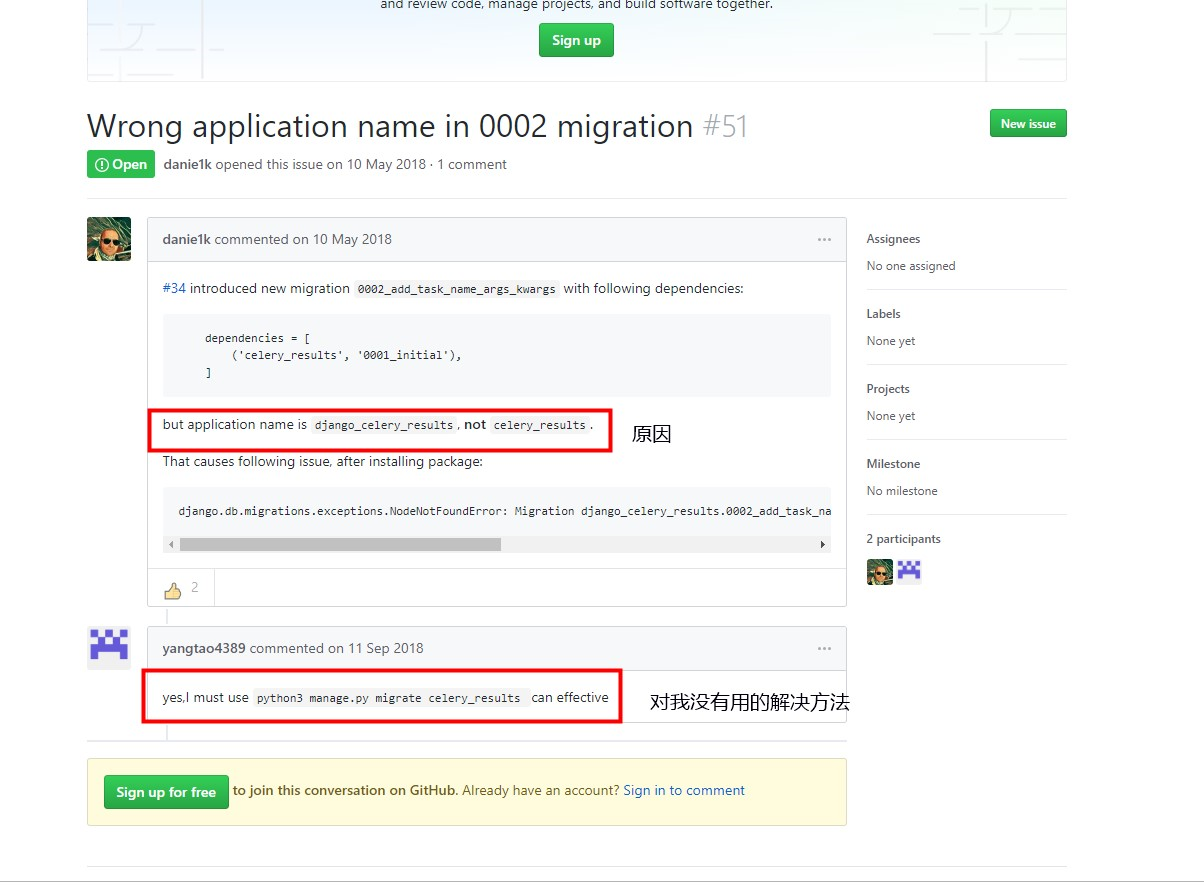
然后,我就尝试着吧,celery_results改成了django_celery_results,然后保存文件,重新执行python mange.py meigrate。这次竟然没报错,但给了一个非常有用的警告,给了一条命令。

然后,就将这条命令跑了一边,然后执行了一次migrate,就成功了,成功了。
问题很多,更多的问题,可以去GitHub公开的问题上看看有没有相似的。
总结
道路千万条, 零错第一条。 百度没答案, 想想别的法
django_celery_results安装的坑的更多相关文章
- Android Studio安装踩坑
title: Android Studio安装踩坑 date: 2018-09-07 19:31:32 updated: tags: [Android,Android Studio,坑] descri ...
- tensorflow 1.8, ubuntu 16.04, cuda 9.0, nvidia-390,安装踩坑指南。
被tensorflow 1.8, ubuntu 16.04, cuda 9.0, nvidia-390折磨了5天,终于上坑,留下指南,造福后人. 1.先把依赖搞清楚: tensorflow 1.8依赖 ...
- tensorflow安装排坑笔记
由于项目需求,得用tensorflow完成,只能将mxnet的学习先放在一边,开始用tensorflow,废话不多说 首先安装anaconda+vs2015+cuda8.0+cudnn6.0 首先安装 ...
- phalcon安装-遇坑php-config is not installed 解决方法
通过源码编译安装php环境,按照phalcon官方文档安装扩展,会遇到php-config is not installed的坑. 尝试通过下列命令可以解决: cd /opt/cphalcon-/bu ...
- Linux mint 安装踩坑记录
记得之前电脑上的那个Ubuntu是去年寒假的时候安装的,算下来自己用Linux也快一年了.虽然在去年暑假的时候我也曾经想过要把Ubuntu升级到18.04可是当时安装了几次都没有成功,自己也就放弃了. ...
- Elasticsearch插件head的安装(有坑)
http://blog.csdn.net/u012332735/article/details/56283932 Elasticsearch出了5.2.1版本之后,就去试试它的新版本的使用,为了以后的 ...
- MongoDB的安装避坑(踩坑)
下载 可以去官网下载:https://www.mongodb.com/download-center/community 安装 下载完了就可以使用安装包安装:我下载的mongodb版本是:v4.0.9 ...
- clickhouse源码Redhat系列机单机版安装踩坑笔记
前情概要 由于工作需要用到clickhouse, 这里暂不介绍概念,应用场景,谷歌,百度一大把. 将安装过程踩下的坑记录下来备用 ClickHouse源码 git clone安装(直接下载源码包安装失 ...
- sublime text less安装踩坑图文讲解(less无法生成css)
唉,怎么感觉做个前端几乎把所有的坑都踩遍了啊,别人按照网上安装了一遍就好使,我这里就死活不行. 先说一下我的问题:网上说的能安装的都按了,可是sublime就是不给我生成css文件,后来知道了,就是l ...
随机推荐
- day18 time、datetime、calendar、sys、os、os.path模块
今日内容 时间模块 time模块 datetime模块 calendar模块 系统模块 sys模块 os模块 os.path模块 time模块: 在 time 模块中使用最多的方法有: time() ...
- [转帖]shell中的特殊符号总结
http://www.embeddedlinux.org.cn/emb-linux/entry-level/201907/18-8747.html 在shell中常用的特殊符号罗列如下: # ; ...
- [转帖]国内拉取google kubernetes镜像
国内拉取google kubernetes镜像 2019年04月19日 01:19:03 willblog 阅读数 4231 标签: kubernetes 更多 个人分类: kubernetes ...
- GCD和LCM
GCD _ LCM 是给你两个数A B 的最大公约数, 以及最小公倍数 the greatest common divisor and the least common multiply ! 最大公约 ...
- hard or 9102 字符串DP---Educational Codeforces Round 57 (Rated for Div. 2)
题意:http://codeforces.com/problemset/problem/1096/D 思路:参考:https://blog.csdn.net/qq_41289920/article/d ...
- drf-更新四大接口-单改整体-单改局部-群改整体-群改局部-04
目录 复习 基于前一天序列化基础 整体单改 单与整体局部修改 复习 """ 1.ModelSerializer序列化类 models.py class BaseModel ...
- 单档——PK单号新增、修改时不允许编辑,PK单号自动生成
由系统自动生成单号(日期+流水),用户新增.修改时不允许编辑单号: 范例(cxmt631): 1)在#单头栏位开启设定#中,即 cxmt631_set_entry(p_cmd)下: #add-poin ...
- python项目内import其他内部package的模块的正确方法
转载 :https://blog.csdn.net/u011089523/article/details/52931844 本文主要介绍如何在一个Python项目中,优雅的实现项目内各个package ...
- 并不对劲的CF1237D&E:Balanced Playlist and Binary Search Trees
CF1237D Balanced Playlist 题意 有一个长度为\(n\)(\(n\leq 10^5\))的循环播放歌单,每首歌有一个优秀值\(a_i\)(\(a_i\leq 10^9\)). ...
- 怎样使用 v-bind 绑定 html 标签的属性值?
1. 在 Vue 中可是使用 v-bind 对 html 中的 属性 进行绑定, 如下所示, 我们想给这个 a 标签绑定一个 title 值: <!DOCTYPE html> <ht ...