【Python】简单实现爬取小说《天龙八部》,并在页面本地访问
背景
很多人说学习爬虫是提升自己的一个非常好的方法,所以有了第一次使用爬虫,水平有限,依葫芦画瓢,主要作为学习的记录。
思路
- 使用python的requests模块获取页面信息
- 通过re模块(正则表达式)取出需要的内容(小说标题,正文)
- 通过MysqlDB模块入库
- 使用webpy模块生成访问页面
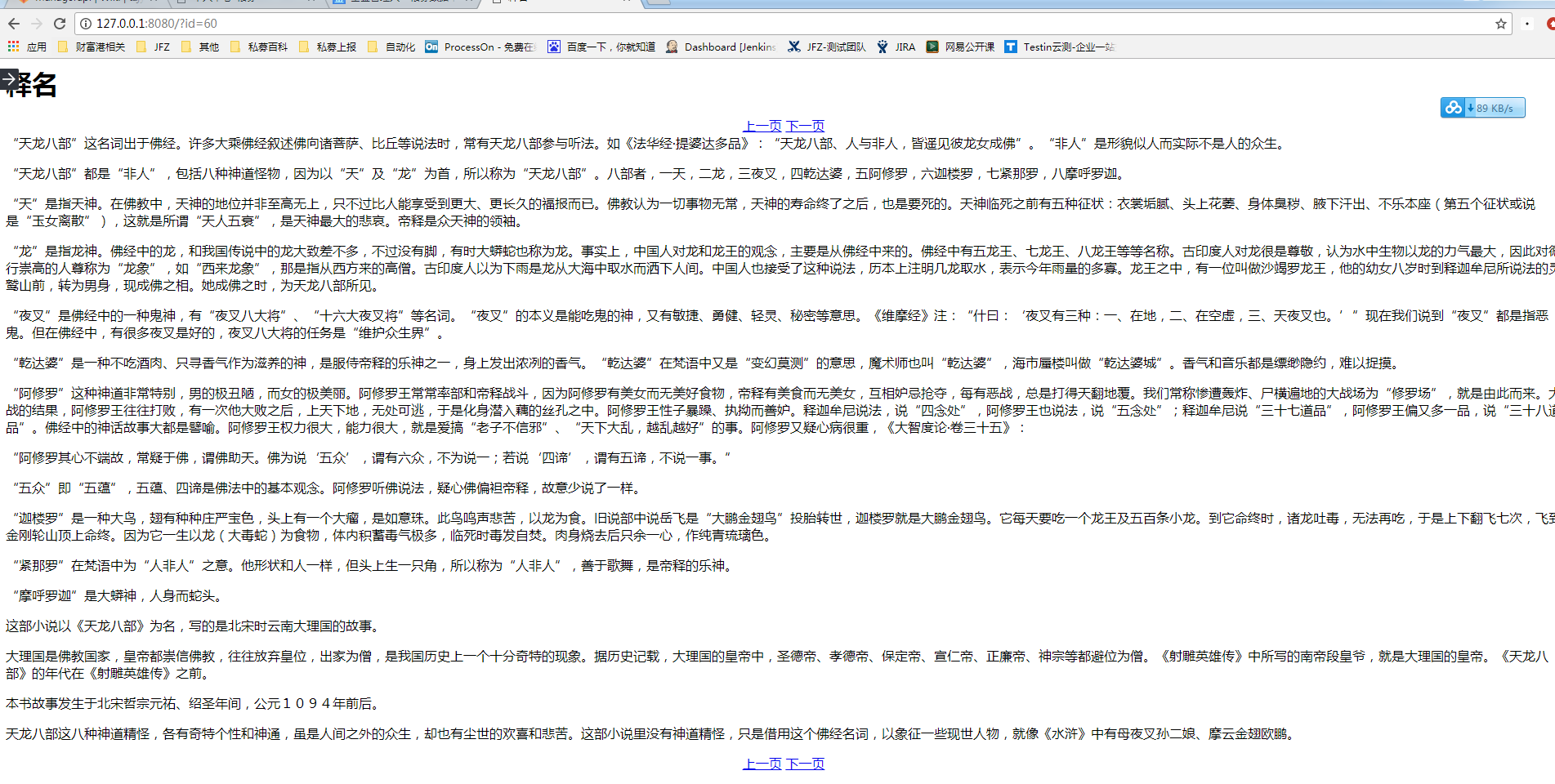
最终的效果图
下面是效果图,简单实现了点击上一页、下一页翻页的功能:
目录结构
目录结构如下:
D:\PROJECT\SPIDER
│ fiction_spider.py
│ webapp.py
│
└─template
index.html
爬取信息及入库示例代码
#coding:utf-8#fiction_spider.py
import requests
import re
import MySQLdb
def get_title():
html = requests.get('http://www.jinyongwang.com/tian/').content
rem = r'<li><a href="(.*?)">(.*?)</a>'
return re.findall(rem,html)
def get_content(url):
html = requests.get('http://www.jinyongwang.com/'+url).content
#print html
matchs_p = r'<p>(.*?)</p><script.*?'
data = re.findall(matchs_p, html)
return data[0]
if __name__ == '__main__':
a = MySQLdb.connect(host='10.1.*.*', port=3306, user='user', passwd='passwd', db='testdb', charset='utf8')
for i in get_title():
cur = a.cursor()
print i[1]
print i[0]
sqli = 'INSERT INTO `fiction` (`title`, `content`) VALUES ("%s","%s" )'%(i[1],get_content(i[0]))
cur.execute(sqli)
cur.close()
a.commit()
a.close()
生成访问页面示例代码
#coding:utf-8#webapp.py
import web
import re
urls = ('/(.*)','Index')
db = web.database(dbn = 'mysql',host='10.1.*.*', port=3306, user='user', passwd='passwd', db='testdb', charset='utf8')
render = web.template.render('template')
class Index:
def GET(self,html):
id = re.findall('(.*?).html',html)[0]
print id
data = db.query("select * from fiction where id=%s"%id)
return render.index(data[0],id)
if __name__ == '__main__':
web.application(urls,globals()).run()
页面访问的index.html内容如下:
$def with(data,s) <meta charset="utf-8"/> <title>$:data.title</title> <h1>$:data.title</h1> <div style="margin:0px auto;text-align:center;"> <a href="$:(int(s)-1).html">上一页</a> <a href="$:(int(s)+1).html">下一页</a> </div> $:data.content <br> <div style="margin:0px auto;text-align:center;"> <a href="$:(int(s)-1).html">上一页</a> <a href="$:(int(s)+1).html">下一页</a> </div>
保存到txt:
if __name__ == '__main__':
a = open(u'射雕**传.txt','w')
m = 0
for i in get_title():
#print i[1], get_content(i[0])
time.sleep(2)
data = i[1] + '\n' + '\n' + get_content(i[0]).replace('</p><p>','\n\n') + '\n\n' #在标题和内容之间插入换行符,将html中的<p>参数变成换行符
a.writelines(data)
m += 1
print u'正在爬取第%s段内容' % m
# if m >2:
# print u'正在爬取第%s段内容' % m
# break
a.close()
【Python】简单实现爬取小说《天龙八部》,并在页面本地访问的更多相关文章
- 初次尝试python爬虫,爬取小说网站的小说。
本次是小阿鹏,第一次通过python爬虫去爬一个小说网站的小说. 下面直接上菜. 1.首先我需要导入相应的包,这里我采用了第三方模块的架包,requests.requests是python实现的简单易 ...
- Python简单程序爬取天气信息,定时发邮件给朋友【高薪必学】
前段时间看到了这个博客.https://blog.csdn.net/weixin_45081575/article/details/102886718.他用了request模块,这不巧了么,正好我刚用 ...
- python简单爬虫爬取百度百科python词条网页
目标分析:目标:百度百科python词条相关词条网页 - 标题和简介 入口页:https://baike.baidu.com/item/Python/407313 URL格式: - 词条页面URL:/ ...
- 04 Python网络爬虫 <<爬取get/post请求的页面数据>>之requests模块
一. urllib库 urllib是Python自带的一个用于爬虫的库,其主要作用就是可以通过代码模拟浏览器发送请求.其常被用到的子模块在Python3中的为urllib.request和urllib ...
- python爬虫——爬取小说 | 探索白子画和花千骨的爱恨情仇(转载)
转载出处:药少敏 ,感谢原作者清晰的讲解思路! 下述代码是我通过自己互联网搜索和拜读完此篇文章之后写出的具有同样效果的爬虫代码: from bs4 import BeautifulSoup imp ...
- Scrapy爬取小说简单逻辑
Scrapy爬取小说简单逻辑 一 准备工作 1)安装Python 2)安装PIP 3)安装scrapy 4)安装pywin32 5)安装VCForPython27.exe ........... 具体 ...
- Python实战项目网络爬虫 之 爬取小说吧小说正文
本次实战项目适合,有一定Python语法知识的小白学员.本人也是根据一些网上的资料,自己摸索编写的内容.有不明白的童鞋,欢迎提问. 目的:爬取百度小说吧中的原创小说<猎奇师>部分小说内容 ...
- Golang 简单爬虫实现,爬取小说
为什么要使用Go写爬虫呢? 对于我而言,这仅仅是练习Golang的一种方式. 所以,我没有使用爬虫框架,虽然其很高效. 为什么我要写这篇文章? 将我在写爬虫时找到资料做一个总结,希望对于想使用Gola ...
- python之爬取小说
继上一篇爬取小说一念之间的第一章,这里将进一步展示如何爬取整篇小说 # -*- coding: utf- -*- import urllib.request import bs4 import re ...
随机推荐
- 如何制作一款HTML5 RPG游戏引擎——第三篇,利用幕布切换场景
开言: 在RPG游戏中,如果有地图切换的地方,通常就会使用幕布效果.所谓的幕布其实就是将两个矩形合拢,直到把屏幕遮住,然后再展开直到两个矩形全部移出屏幕. 为了大家做游戏方便,于是我给这个引擎加了这么 ...
- 【HTML5游戏开发】简单的《找不同汉字版》,来考考你的眼力吧
一,准备工作 本次游戏开发需要用到lufylegend.js开源游戏引擎,版本我用的是1.5.2(现在最新的版本是1.6.0). 引擎下载的位置:http://lufylegend.googlecod ...
- 百度NLP一面
C++ : 1.拷贝构造函数和重载=符分别在什么情况下被调用,实现有什么区别 2.虚函数的目的,虚函数和模板类的区别,如何找到虚函数 常规算法: 1. 如何输出一个集合的所有真子集,递归和非递 ...
- 如何使用别人的代码 (特指在MFC里面 或者推广为C++里面)
别人写了一堆代码,给了你源代码.在C++里面 应该是 头文件(.h)和源文件(.cpp). 那么我们如何使用他们呢?? 第一步:将其包含进来 如下图 ,不论是头文件还是源文件都如此 第二步:告诉 ...
- __all__方法的作用
在__all__里面写了谁,到时候就只能用谁,其他的用不了,from 模块 import *时就只能用__all__里的 __all__=['test1','Test'] def test1(): p ...
- Git在Githib和Github上的使用
本文使用的环境是linux里 一.git的常用命令解释: 1.基础命令: git init #创建版本库 git add <file> #将文件修改添加到暂存区 git commit -m ...
- Centos 6.5 Install Mysql 8.0.0
依赖包 yum install numactl libaio perl-Time-HiRes per-devel -y 下载对应系统版本下载 wget http://cdn.mysql.com//Do ...
- The 15th UESTC Programming Contest Preliminary B - B0n0 Path cdoj1559
地址:http://acm.uestc.edu.cn/#/problem/show/1559 题目: B0n0 Path Time Limit: 1500/500MS (Java/Others) ...
- HDU - 4871 Shortest-path tree (最短路径树+ 树分治)
题意:给你一张带权无向图,先求出这张图从点1出发的最短路树,再求在树上经过k个节点最长的路径值,以及个数. 分析:首先求最短路树,跑一遍最短路之后dfs一遍即可建出最短路树. 第二个问题,树分治解决. ...
- QML中的state 状态
QML中的状态其实很好理解,任何事物在某一事件都是有一个状态的. 比如你看到的一个窗口,这个时候里面的文字和图片正处于某个状态中.比如一个超链接,你点击了,发现颜色变了,你按了Ctrl+A,整个窗体好 ...