十五 web爬虫讲解2—urllib库中使用xpath表达式—BeautifulSoup基础
在urllib中,我们一样可以使用xpath表达式进行信息提取,此时,你需要首先安装lxml模块,然后将网页数据通过lxml下的etree转化为treedata的形式
urllib库中使用xpath表达式
etree.HTML()将获取到的html字符串,转换成树形结构,也就是xpath表达式可以获取的格式

#!/usr/bin/env python
# -*- coding:utf8 -*-
import urllib.request
from lxml import etree #导入html树形结构转换模块 wye = urllib.request.urlopen('http://sh.qihoo.com/pc/home').read().decode("utf-8",'ignore')
zhuanh = etree.HTML(wye) #将获取到的html字符串,转换成树形结构,也就是xpath表达式可以获取的格式
print(zhuanh)
hqq = zhuanh.xpath('/html/head/title/text()') #通过xpath表达式获取标题 #注意,xpath表达式获取到数据,有时候是列表,有时候不是列表所以要做如下处理
if str(type(hqq)) == "<class 'list'>": #判断获取到的是否是列表
print(hqq)
else:
xh_hqq = [i for i in hqq] #如果不是列表,循环数据组合成列表
print(xh_hqq) #返回 :['【今日爆点】你的专属资讯平台']
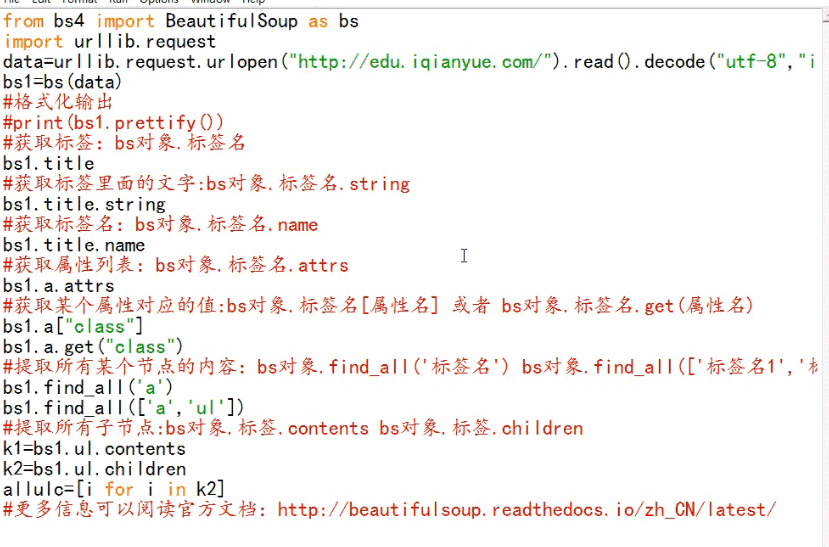
BeautifulSoup基础
BeautifulSoup是获取thml元素的模块
BeautifulSoup-3.2.1版本
十五 web爬虫讲解2—urllib库中使用xpath表达式—BeautifulSoup基础的更多相关文章
- 第三百三十六节,web爬虫讲解2—urllib库中使用xpath表达式—BeautifulSoup基础
第三百三十六节,web爬虫讲解2—urllib库中使用xpath表达式—BeautifulSoup基础 在urllib中,我们一样可以使用xpath表达式进行信息提取,此时,你需要首先安装lxml模块 ...
- 第三百三十节,web爬虫讲解2—urllib库爬虫—实战爬取搜狗微信公众号—抓包软件安装Fiddler4讲解
第三百三十节,web爬虫讲解2—urllib库爬虫—实战爬取搜狗微信公众号—抓包软件安装Fiddler4讲解 封装模块 #!/usr/bin/env python # -*- coding: utf- ...
- 第三百二十九节,web爬虫讲解2—urllib库爬虫—ip代理—用户代理和ip代理结合应用
第三百二十九节,web爬虫讲解2—urllib库爬虫—ip代理 使用IP代理 ProxyHandler()格式化IP,第一个参数,请求目标可能是http或者https,对应设置build_opener ...
- 第三百二十八节,web爬虫讲解2—urllib库爬虫—状态吗—异常处理—浏览器伪装技术、设置用户代理
第三百二十八节,web爬虫讲解2—urllib库爬虫—状态吗—异常处理—浏览器伪装技术.设置用户代理 如果爬虫没有异常处理,那么爬行中一旦出现错误,程序将崩溃停止工作,有异常处理即使出现错误也能继续执 ...
- 第三百二十七节,web爬虫讲解2—urllib库爬虫—基础使用—超时设置—自动模拟http请求
第三百二十七节,web爬虫讲解2—urllib库爬虫 利用python系统自带的urllib库写简单爬虫 urlopen()获取一个URL的html源码read()读出html源码内容decode(& ...
- 六 web爬虫讲解2—urllib库爬虫—基础使用—超时设置—自动模拟http请求
利用python系统自带的urllib库写简单爬虫 urlopen()获取一个URL的html源码read()读出html源码内容decode("utf-8")将字节转化成字符串 ...
- 九 web爬虫讲解2—urllib库爬虫—实战爬取搜狗微信公众号—抓包软件安装Fiddler4讲解
封装模块 #!/usr/bin/env python # -*- coding: utf-8 -*- import urllib from urllib import request import j ...
- 八 web爬虫讲解2—urllib库爬虫—ip代理—用户代理和ip代理结合应用
使用IP代理 ProxyHandler()格式化IP,第一个参数,请求目标可能是http或者https,对应设置build_opener()初始化IPinstall_opener()将代理IP设置成全 ...
- 七 web爬虫讲解2—urllib库爬虫—状态吗—异常处理—浏览器伪装技术、设置用户代理
如果爬虫没有异常处理,那么爬行中一旦出现错误,程序将崩溃停止工作,有异常处理即使出现错误也能继续执行下去 1.常见状态吗 301:重定向到新的URL,永久性302:重定向到临时URL,非永久性304: ...
随机推荐
- python subplot 合并子图的方法
- golang在线手册汇总
1. golang官网 https://golang.org/ 2. golang中国 http://www.golangtc.com/ http://godoc.golangtc.com/pkg/ ...
- STL vector 内存释放
最近在论坛看到一个提问帖子,问题是vector中存储了对象的指针,调用clear后这些指针如何删除? class Test { public: Test() {} ~Test() { cout < ...
- jmeter接口测试实战
请求方法:get/post 接口请求地址:http://172.22.24.26:8080/fundhouse/external/getdata?name=xxxx &fund_udid=35 ...
- linux怎样使用top命令查看系统状态
有时候有很多问题只有在线上或者预发环境才能发现,而线上又不能Debug,所以线上问题定位就只能看日志,系统状态和Dump线程. Linux系统可以通过top命令查看系统的CPU.内存.运行时间.交换分 ...
- spring boot 引导
链接:https://www.zhihu.com/question/39483566/answer/243413600 Spring Boot 的优点快速开发,特别适合构建微服务系统,另外给我们封装了 ...
- iOS 绘制一个表盘时钟,秒针效果可以“扫秒/游走”
最近自己 也尝试写了一个表盘时钟,初衷源于等车时候一个老奶奶问时间,我打开手机,时间数字对我来说相对敏感,但是老奶奶是看不清的,我想识别 还是看表盘 老远 看时针分针角度就可以识别当前时间. 于是我想 ...
- 用74HC165读8个按键状态
源:用74HC165读8个按键状态 源:74LV165与74HC595 使用 74LV165说明: 74LV165是8位并行负载或串行输入移位寄存器,末级提供互补串行输出(Q7和Q7).并行负载(PL ...
- SQL学习笔记之B+树的几点总结
本文主要以列表形式将B+树的特点以及注意点等列出来,主要参考<算法导论>.维基百科.各大博客的内容,结合自己的理解写的,如内容有不当之处,请各位雅正. 0x00 前言 B树是为磁盘或其他直 ...
- CSS Margin(外边距)
CSS Margin(外边距) 一.简介 CSS margin(外边距)属性定义元素周围的空间. margin 清除周围的(外边框)元素区域.margin 没有背景颜色,是完全透明的. margin ...