浅谈深度学习中的激活函数 - The Activation Function in Deep Learning
原文地址:http://www.cnblogs.com/rgvb178/p/6055213.html
版权声明:本文为博主原创文章,未经博主允许不得转载。
激活函数的作用
首先,激活函数不是真的要去激活什么。在神经网络中,激活函数的作用是能够给神经网络加入一些非线性因素,使得神经网络可以更好地解决较为复杂的问题。
比如在下面的这个问题中: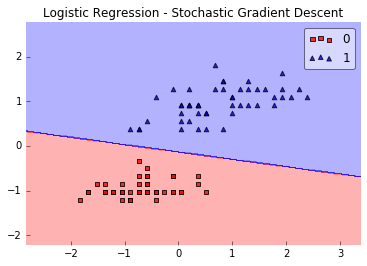
如上图(图片来源),在最简单的情况下,数据是线性可分的,只需要一条直线就已经能够对样本进行很好地分类。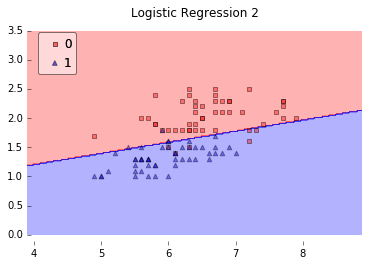
但如果情况变得复杂了一点呢?在上图中(图片来源),数据就变成了线性不可分的情况。在这种情况下,简单的一条直线就已经不能够对样本进行很好地分类了。
于是我们尝试引入非线性的因素,对样本进行分类。
在神经网络中也类似,我们需要引入一些非线性的因素,来更好地解决复杂的问题。而激活函数恰好就是那个能够帮助我们引入非线性因素的存在,使得我们的神经网络能够更好地解决较为复杂的问题。
激活函数的定义及其相关概念
在ICML2016的一篇论文Noisy Activation Functions中,作者将激活函数定义为一个几乎处处可微的 h : R → R 。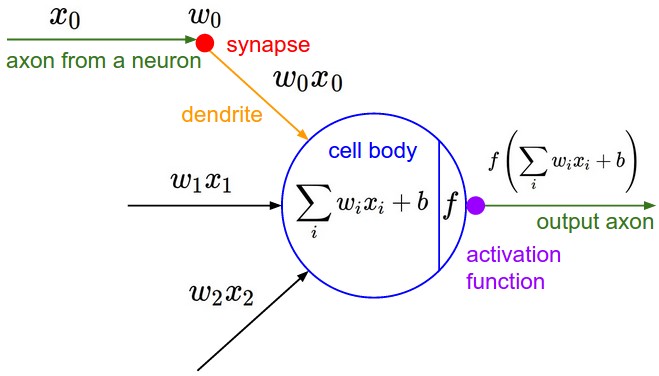
在实际应用中,我们还会涉及到以下的一些概念:
a.饱和
当一个激活函数h(x)满足
时我们称之为右饱和。
当一个激活函数h(x)满足
时我们称之为左饱和。当一个激活函数,既满足左饱和又满足又饱和时,我们称之为饱和。
b.硬饱和与软饱和
对任意的x" role="presentation" style="display: inline; line-height: normal; word-spacing: normal; word-wrap: normal; white-space: nowrap; float: none; direction: ltr; max-width: none; max-height: none; min-width: 0px; min-height: 0px; border: 0px; padding: 0px; margin: 0px; position: relative;">xx,如果存在常数c" role="presentation" style="display: inline; line-height: normal; word-spacing: normal; word-wrap: normal; white-space: nowrap; float: none; direction: ltr; max-width: none; max-height: none; min-width: 0px; min-height: 0px; border: 0px; padding: 0px; margin: 0px; position: relative;">cc,当x>c" role="presentation" style="display: inline; line-height: normal; word-spacing: normal; word-wrap: normal; white-space: nowrap; float: none; direction: ltr; max-width: none; max-height: none; min-width: 0px; min-height: 0px; border: 0px; padding: 0px; margin: 0px; position: relative;">x>cx>c时恒有 h′(x)=0" role="presentation" style="display: inline; line-height: normal; word-spacing: normal; word-wrap: normal; white-space: nowrap; float: none; direction: ltr; max-width: none; max-height: none; min-width: 0px; min-height: 0px; border: 0px; padding: 0px; margin: 0px; position: relative;">h′(x)=0h′(x)=0则称其为右硬饱和,当x<c" role="presentation" style="display: inline; line-height: normal; word-spacing: normal; word-wrap: normal; white-space: nowrap; float: none; direction: ltr; max-width: none; max-height: none; min-width: 0px; min-height: 0px; border: 0px; padding: 0px; margin: 0px; position: relative;">x<cx<c时恒 有h′(x)=0" role="presentation" style="display: inline; line-height: normal; word-spacing: normal; word-wrap: normal; white-space: nowrap; float: none; direction: ltr; max-width: none; max-height: none; min-width: 0px; min-height: 0px; border: 0px; padding: 0px; margin: 0px; position: relative;">h′(x)=0h′(x)=0则称其为左硬饱和。若既满足左硬饱和,又满足右硬饱和,则称这种激活函数为硬饱和。但如果只有在极限状态下偏导数等于0的函数,称之为软饱和。
Sigmoid函数
Sigmoid函数曾被广泛地应用,但由于其自身的一些缺陷,现在很少被使用了。Sigmoid函数被定义为:
函数对应的图像是: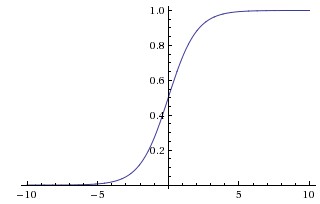
优点:
1.Sigmoid函数的输出映射在(0,1)" role="presentation" style="display: inline; line-height: normal; word-spacing: normal; word-wrap: normal; white-space: nowrap; float: none; direction: ltr; max-width: none; max-height: none; min-width: 0px; min-height: 0px; border: 0px; padding: 0px; margin: 0px; position: relative;">(0,1)(0,1)之间,单调连续,输出范围有限,优化稳定,可以用作输出层。
2.求导容易。
缺点:
1.由于其软饱和性,容易产生梯度消失,导致训练出现问题。
2.其输出并不是以0为中心的。
tanh函数
现在,比起Sigmoid函数我们通常更倾向于tanh函数。tanh函数被定义为
函数位于[-1, 1]区间上,对应的图像是: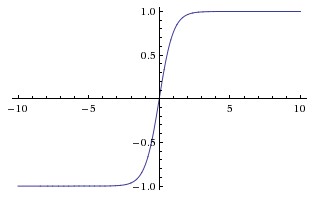
优点:
1.比Sigmoid函数收敛速度更快。
2.相比Sigmoid函数,其输出以0为中心。
缺点:
还是没有改变Sigmoid函数的最大问题——由于饱和性产生的梯度消失。
ReLU
ReLU是最近几年非常受欢迎的激活函数。被定义为
对应的图像是: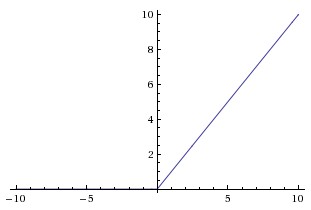
但是除了ReLU本身的之外,TensorFlow还提供了一些相关的函数,比如定义为min(max(features, 0), 6)的tf.nn.relu6(features, name=None);或是CReLU,即tf.nn.crelu(features, name=None)。其中(CReLU部分可以参考这篇论文)。
优点:
1.相比起Sigmoid和tanh,ReLU(e.g. a factor of 6 in Krizhevsky et al.)在SGD中能够快速收敛。例如在下图的实验中,在一个四层的卷积神经网络中,实线代表了ReLU,虚线代表了tanh,ReLU比起tanh更快地到达了错误率0.25处。据称,这是因为它线性、非饱和的形式。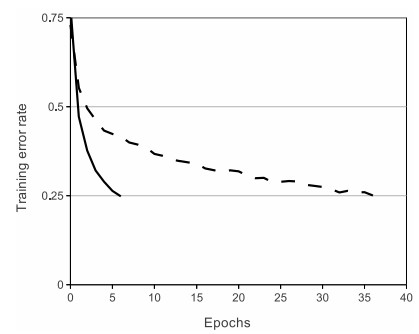
2.Sigmoid和tanh涉及了很多很expensive的操作(比如指数),ReLU可以更加简单的实现。
3.有效缓解了梯度消失的问题。
4.在没有无监督预训练的时候也能有较好的表现。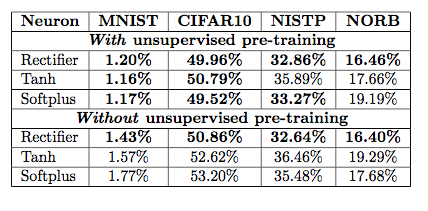
5.提供了神经网络的稀疏表达能力。
缺点:
随着训练的进行,可能会出现神经元死亡,权重无法更新的情况。如果发生这种情况,那么流经神经元的梯度从这一点开始将永远是0。也就是说,ReLU神经元在训练中不可逆地死亡了。
LReLU、PReLU与RReLU
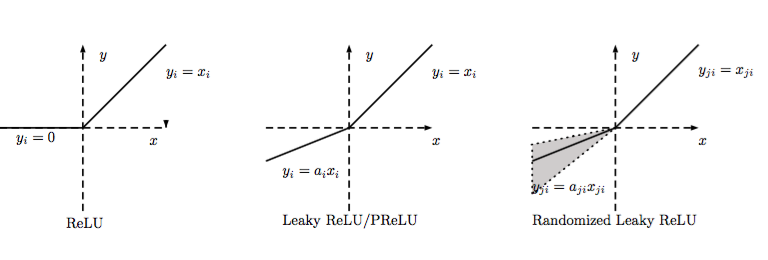
通常在LReLU和PReLU中,我们定义一个激活函数为
-LReLU
当ai" role="presentation" style="display: inline; line-height: normal; word-spacing: normal; word-wrap: normal; white-space: nowrap; float: none; direction: ltr; max-width: none; max-height: none; min-width: 0px; min-height: 0px; border: 0px; padding: 0px; margin: 0px; position: relative;">aiai比较小而且固定的时候,我们称之为LReLU。LReLU最初的目的是为了避免梯度消失。但在一些实验中,我们发现LReLU对准确率并没有太大的影响。很多时候,当我们想要应用LReLU时,我们必须要非常小心谨慎地重复训练,选取出合适的a" role="presentation" style="display: inline; line-height: normal; word-spacing: normal; word-wrap: normal; white-space: nowrap; float: none; direction: ltr; max-width: none; max-height: none; min-width: 0px; min-height: 0px; border: 0px; padding: 0px; margin: 0px; position: relative;">aa,LReLU的表现出的结果才比ReLU好。因此有人提出了一种自适应地从数据中学习参数的PReLU。
-PReLU
PReLU是LReLU的改进,可以自适应地从数据中学习参数。PReLU具有收敛速度快、错误率低的特点。PReLU可以用于反向传播的训练,可以与其他层同时优化。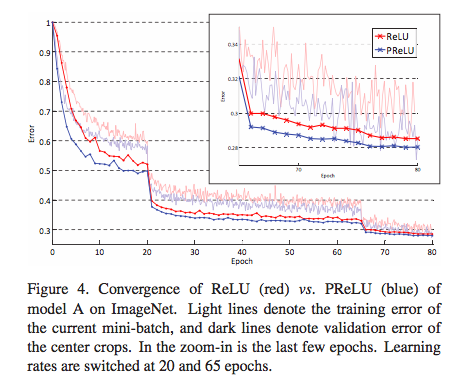
在论文Delving Deep into Rectifiers: Surpassing Human-Level Performance on ImageNet Classification中,作者就对比了PReLU和ReLU在ImageNet model A的训练效果。
值得一提的是,在tflearn中有现成的LReLU和PReLU可以直接用。
-RReLU
在RReLU中,我们有
其中,aji" role="presentation" style="display: inline; line-height: normal; font-size: 14px; word-spacing: normal; word-wrap: normal; white-space: nowrap; float: none; direction: ltr; max-width: none; max-height: none; min-width: 0px; min-height: 0px; border: 0px; padding: 0px; margin: 0px; position: relative;">ajiaji是一个保持在给定范围内取样的随机变量,在测试中是固定的。RReLU在一定程度上能起到正则效果。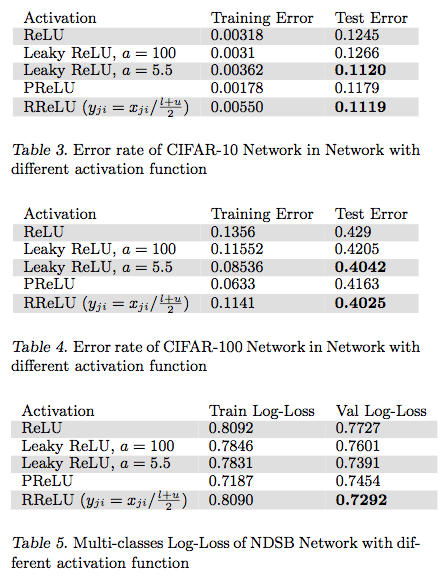
在论文Empirical Evaluation of Rectified Activations in Convolution Network中,作者对比了RReLU、LReLU、PReLU、ReLU 在CIFAR-10、CIFAR-100、NDSB网络中的效果。
ELU
ELU被定义为
其中a>0" role="presentation" style="display: inline; line-height: normal; font-size: 14px; word-spacing: normal; word-wrap: normal; white-space: nowrap; float: none; direction: ltr; max-width: none; max-height: none; min-width: 0px; min-height: 0px; border: 0px; padding: 0px; margin: 0px; position: relative;">a>0a>0。
优点:
1.ELU减少了正常梯度与单位自然梯度之间的差距,从而加快了学习。
2.在负的限制条件下能够更有鲁棒性。
ELU相关部分可以参考这篇论文。
Softplus与Softsign
Softplus被定义为
Softsign被定义为
目前使用的比较少,在这里就不详细讨论了。TensorFlow里也有现成的可供使用。激活函数相关TensorFlow的官方文档
总结
关于激活函数的选取,目前还不存在定论,实践过程中更多还是需要结合实际情况,考虑不同激活函数的优缺点综合使用。同时,也期待越来越多的新想法,改进目前存在的不足。
文章部分图片或内容参考自:
CS231n Convolutional Neural Networks for Visual Recognition
Quora - What is the role of the activation function in a neural network?
深度学习中的激活函数导引
Noisy Activation Functions-ICML2016
本文为作者的个人学习笔记,转载请先声明。如有疏漏,欢迎指出,不胜感谢。
浅谈深度学习中的激活函数 - The Activation Function in Deep Learning的更多相关文章
- The Activation Function in Deep Learning 浅谈深度学习中的激活函数
原文地址:http://www.cnblogs.com/rgvb178/p/6055213.html 版权声明:本文为博主原创文章,未经博主允许不得转载. 激活函数的作用 首先,激活函数不是真的要去激 ...
- 转:浅谈深度学习(Deep Learning)的基本思想和方法
浅谈深度学习(Deep Learning)的基本思想和方法 参考:http://blog.csdn.net/xianlingmao/article/details/8478562 深度学习(Deep ...
- TensorFlow从0到1之浅谈深度学习(10)
DNN(深度神经网络算法)现在是AI社区的流行词.最近,DNN 在许多数据科学竞赛/Kaggle 竞赛中获得了多次冠军. 自从 1962 年 Rosenblat 提出感知机(Perceptron)以来 ...
- 吴恩达《深度学习》-第一门课 (Neural Networks and Deep Learning)-第三周:浅层神经网络(Shallow neural networks) -课程笔记
第三周:浅层神经网络(Shallow neural networks) 3.1 神经网络概述(Neural Network Overview) 使用符号$ ^{[
- 吴恩达《深度学习》-第一门课 (Neural Networks and Deep Learning)-第二周:(Basics of Neural Network programming)-课程笔记
第二周:神经网络的编程基础 (Basics of Neural Network programming) 2.1.二分类(Binary Classification) 二分类问题的目标就是习得一个分类 ...
- 吴恩达《深度学习》-第一门课 (Neural Networks and Deep Learning)-第四周:深层神经网络(Deep Neural Networks)-课程笔记
第四周:深层神经网络(Deep Neural Networks) 4.1 深层神经网络(Deep L-layer neural network) 有一些函数,只有非常深的神经网络能学会,而更浅的模型则 ...
- 开始学习深度学习和循环神经网络Some starting points for deep learning and RNNs
Bengio, LeCun, Jordan, Hinton, Schmidhuber, Ng, de Freitas and OpenAI have done reddit AMA's. These ...
- 深度学习图像配准 Image Registration: From SIFT to Deep Learning
Image Registration is a fundamental step in Computer Vision. In this article, we present OpenCV feat ...
- Deep Learning 8_深度学习UFLDL教程:Stacked Autocoders and Implement deep networks for digit classification_Exercise(斯坦福大学深度学习教程)
前言 1.理论知识:UFLDL教程.Deep learning:十六(deep networks) 2.实验环境:win7, matlab2015b,16G内存,2T硬盘 3.实验内容:Exercis ...
随机推荐
- 0ctf2017-pages-choices
Pages 题目来自于CCS 2016 <Prefetch Side-Channel Attacks: Bypassing SMAP and Kernel ASLR>,利用intel pr ...
- node实现rar格式压缩
背景 由于公司的CMS系统里,只接受rar格式压缩的文件,所以没法直接使用nodejs里提供的zip压缩组件.只能从winRar软件入手了,但网上没有多少这方面相关的东西,所以下面也是自己尝试着在做. ...
- vim寄存器与复制粘贴的实现
对于大多数在Ubuntu下使用vim作为常用编辑器的同学来讲,他们遇到的第一个比较大的麻烦来自于vim与外部应用的复制粘贴. 当然,愿意选择ubuntu以及vim的同学肯定是google好手.不幸的是 ...
- 【bzoj4976】宝石镶嵌(思维dp)
题目传送门:bzoj4976 不得不说这是道脑洞dp,思路真的清奇. 我们可以发现,虽然n很大,但是k只有100,这里面似乎隐藏了什么玄机. 我们可以发现,设总共有$ tot $个二进制位在这n个数中 ...
- c# iText 生成PDF 有文字,图片,表格,文字样式,对齐方式,页眉页脚,等等等,
#region 下载说明书PDF protected void lbtnDownPDF_Click(object sender, EventArgs e) { int pid = ConvertHel ...
- spark SQL学习(案例-统计每日uv)
需求:统计每日uv package wujiadong_sparkSQL import org.apache.spark.sql.{Row, SQLContext} import org.apache ...
- PAT1070. Mooncake (25)
#include #include #include <stdio.h> #include <math.h> using namespace std; struct SS{ d ...
- Docker 坑点记录
1 关于 Docker Windows 文件夹问题 C:\Users Docker Machine tries to auto-share your /Users (OS X) or C:\Users ...
- nginx的坑-org.apache.http.TruncatedChunkException: Truncated chunk( expected size: 7752; actual size: 4077)
org.apache.http.TruncatedChunkException: Truncated chunk 项目中使用请求远程接口报错 ,项目是Spring-boot的,两个项目(A和B) , ...
- VS2012 QT5.2.0 无法解析的外部符号
背景:在新建QT工程时,可能没有选择一些库,虽然在头文件中引用了,但是程序依然无法识别 现象:一般出现"LNK2019"错误. 解决:以网络为例,在VS2012中加入网络库,分为两 ...