Hadoop Federation联邦
背景概述
单 NameNode 的架构使得 HDFS 在集群扩展性和性能上都有潜在的问题,当集群大到一定程度后,NameNode 进程使用的内存可能会达到上百 G,NameNode 成为了性能的瓶颈。因
而提出了 namenode 水平扩展方案-- Federation。
Federation 中文意思为联邦,联盟,是 NameNode 的 Federation,也就是会有多个NameNode。多个 NameNode 的情况意味着有多个 namespace(命名空间),区别于 HA 模式下的多 NameNode,它们是拥有着同一个 namespace。既然说到了 NameNode 的命名空间的概念,这里就看一下现有的 HDFS 数据管理架构,如下图所示:
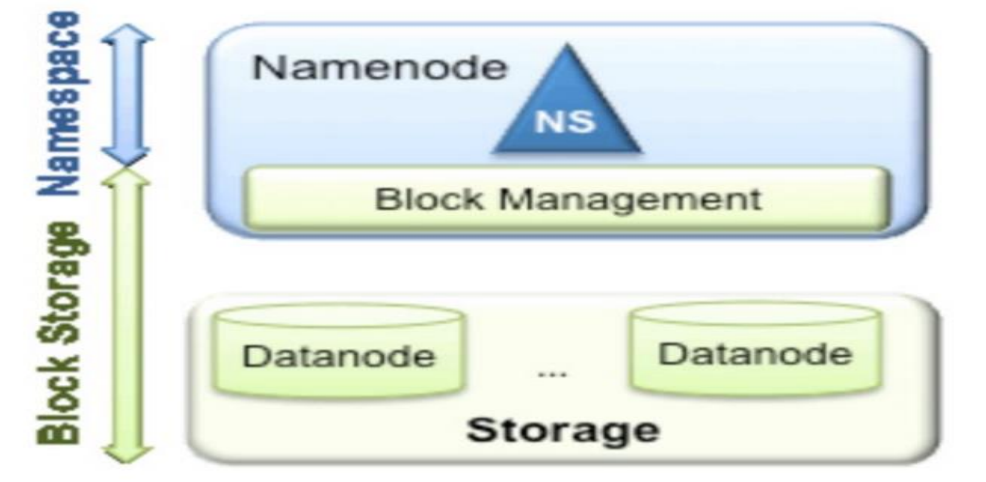
从上图中,我们可以很明显地看出现有的 HDFS 数据管理,数据存储 2 层分层的结构.也就是说,所有关于存储数据的信息和管理是放在 NameNode 这边,而真实数据的存储则是在各个 DataNode 下。而这些隶属于同一个 NameNode 所管理的数据都是在同一个命名空间下的。而一个 namespace 对应一个 block pool。Block Pool 是同一个 namespace 下的 block 的集合.当然这是我们最常见的单个 namespace 的情况,也就是一个 NameNode 管理集群中所有元数据信息的时候.如果我们遇到了之前提到的 NameNode 内存使用过高的问题,这时候怎么办?元数据空间依然还是在不断增大,一味调高 NameNode 的 jvm 大小绝对不是一个持久的办法.这时候就诞生了 HDFS Federation 的机制.
Federation 架构设计
HDFS Federation 是解决 namenode 内存瓶颈问题的水平横向扩展方案。
Federation 意味着在集群中将会有多个 namenode/namespace。这些 namenode 之间是联合的,也就是说,他们之间相互独立且不需要互相协调,各自分工,管理自己的区域。分布式的 datanode 被用作通用的数据块存储存储设备。每个 datanode 要向集群中所有的namenode 注册,且周期性地向所有 namenode 发送心跳和块报告,并执行来自所有 namenode的命令。

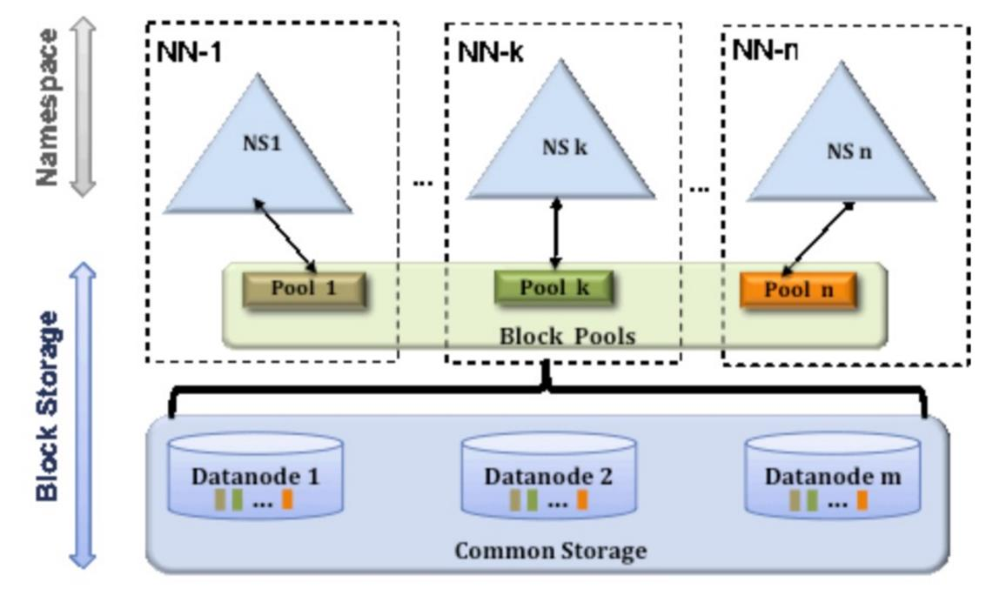
Federation 一个典型的例子就是上面提到的 NameNode 内存过高问题,我们完全可以将上面部分大的文件目录移到另外一个NameNode上做管理. 更重要的一点在于,, 这些 NameNode是共享集群中所有的 e DataNode 的 , 它们还是在同一个集群内的 。
这时候在DataNode上就不仅仅存储一个Block Pool下的数据了,而是多个(在DataNode的 datadir 所在目录里面查看 BP-xx.xx.xx.xx 打头的目录)。
概括起来:
多个 NN 共用一个集群里的存储资源,每个 NN 都可以单独对外提供服务。
每个 NN 都会定义一个存储池,有单独的 id,每个 DN 都为所有存储池提供存储。
DN 会按照存储池 id 向其对应的 NN 汇报块信息,同时,DN 会向所有 NN 汇报本地存储可用资源情况。
HDFS Federation不足
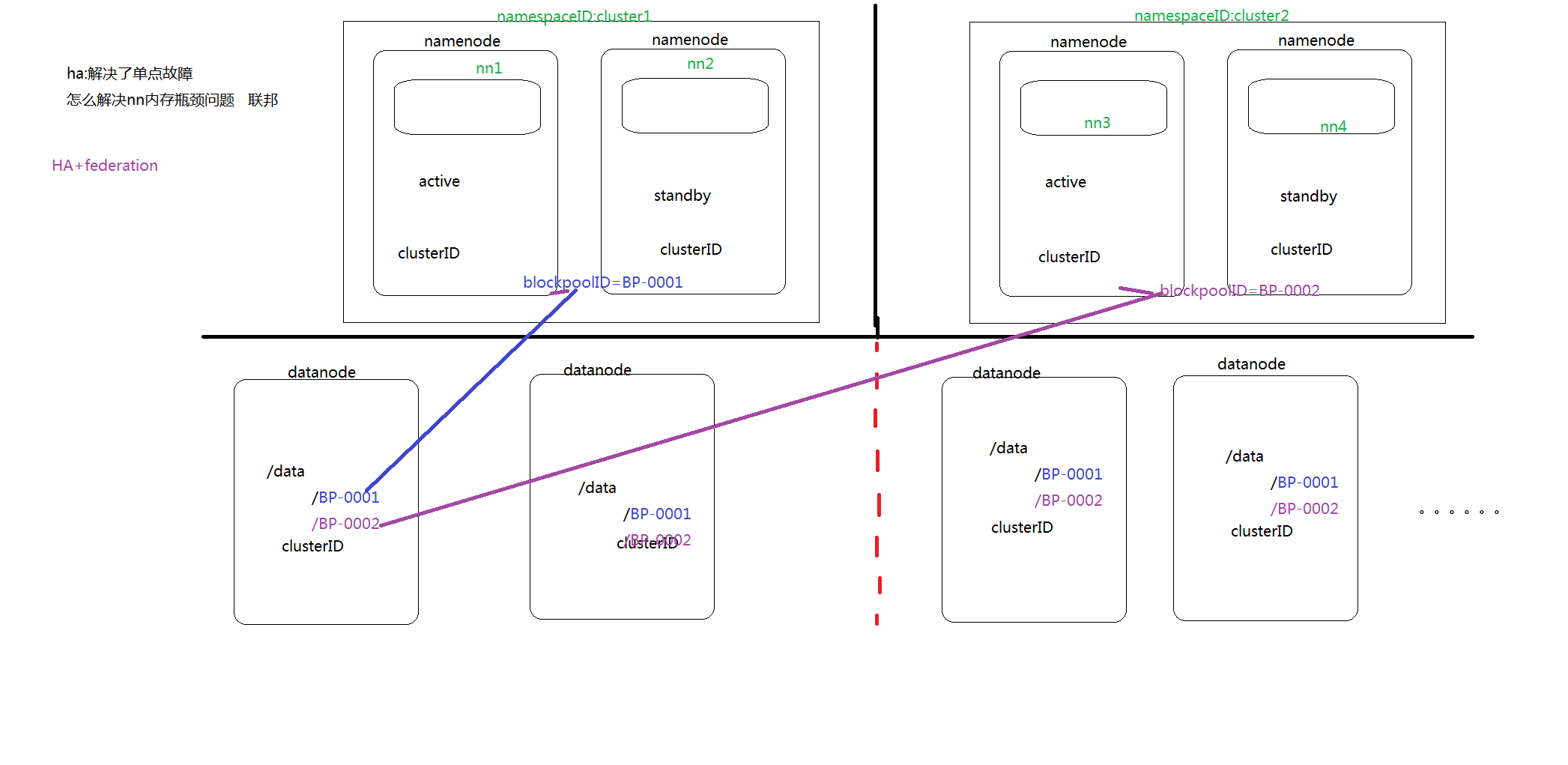
HDFS Federation 并没有完全解决单点故障问题。虽然 namenode/namespace 存在多个,但是从单个 namenode/namespace 看,仍然存在单点故障:如果某个 namenode 挂掉了,其管理的相应的文件便不可以访问。Federation中每个namenode仍然像之前HDFS上实现一样,配有一个 secondary namenode,以便主 namenode 挂掉一下,用于还原元数据信息。
所以一般集群规模真的很大的时候,会采用 HA+Federation 的部署方案。也就是每个联合的 namenodes 都是 ha 的。
Federation 示例配置
这是一个包含两个 Namenode 的 Federation 示例配置:
<configuration>
<property>
<name>dfs.nameservices</name>
<value>ns1,ns2</value>
</property>
<property>
<name>dfs.namenode.rpc-address.ns1</name>
<value>nn-host1:rpc-port</value>
</property>
<property>
<name>dfs.namenode.http-address.ns1</name>
<value>nn-host1:http-port</value>
</property>
<property>
<name>dfs.namenode.secondaryhttp-address.ns1</name>
<value>snn-host1:http-port</value>
</property>
<property>
<name>dfs.namenode.rpc-address.ns2</name>
<value>nn-host2:rpc-port</value>
</property>
<property>
<name>dfs.namenode.http-address.ns2</name>
<value>nn-host2:http-port</value>
</property>
<property>
<name>dfs.namenode.secondaryhttp-address.ns2</name>
<value>snn-host2:http-port</value>
</property>
.... Other common configuration ...
</configuration>
Hadoop Federation联邦的更多相关文章
- CentOS7+Hadoop2.7.2(HA高可用+Federation联邦)+Hive1.2.1+Spark2.1.0 完全分布式集群安装
1 2 2.1 2.2 2.3 2.4 2.5 2.6 2.7 2.8 2.9 2.9.1 2.9.2 2.9.2.1 2.9.2.2 2.9.3 2.9.3.1 2.9.3.2 2.9.3.3 2. ...
- Hadoop federation配置
Hadoop federation配置 1.介绍 hadoop federation也称为联邦,主要是对namenode进行扩容.HA模式下只是实现了hadoop namenode的高可用,但是随着文 ...
- Hadoop记录-Federation联邦机制
在Hadoop2.0之前,HDFS的单NameNode设计带来诸多问题: 单点故障.内存受限,制约集群扩展性和缺乏隔离机制(不同业务使用同一个NameNode导致业务相互影响)等 为了解决这些问题, ...
- 2-10 就业课(2.0)-oozie:11、hadoop的federation(联邦机制,了解一下)
==================================================== Hadoop Federation 背景概述 单NameNode的架构使得HDFS在集群扩展性 ...
- hadoop多机安装HA+YARN
HA 相比于Hadoop1.0,Hadoop 2.0中的HDFS增加了两个重大特性,HA(热备)和Federation(联邦).HA即为High Availability,用于解决NameNode单点 ...
- hadoop多机安装YARN
hadoop伪分布安装称为测试环境安装,多机分布称为生成环境安装.以下安装没有进行HA(热备)和Federation(联邦).除非是性能需要,否则没必要安装Federation,HA可以一试,涉及到Z ...
- Hadoop HDFS 设计随想
目录 引言 HDFS 数据块的设计 数据块应该设置成多大? 抽象成数据块有哪些好处? 操作块信息的命令 HDFS 中节点的设计 有几种节点类型? 用户如何访问 HDFS? 如何对 namenode 容 ...
- Hadoop 2.x简介
Hadoop 2.0产生背景 Hadoop1.0中HDFS和MapReduce在高可用.扩展性等方面存在问题 HDFS存在的问题 NameNode单点故障,难以应用于在线场景 NameNode压力过大 ...
- Hadoop入门学习笔记-第二天 (HDFS:NodeName高可用集群配置)
说明:hdfs:nn单点故障,压力过大,内存受限,扩展受阻.hdfs ha :主备切换方式解决单点故障hdfs Federation联邦:解决鸭梨过大.支持水平扩展,每个nn分管一部分目录,所有nn共 ...
随机推荐
- Java 的多态
1 多态的概念 多态(?) 可以理解为多种状态/多种形态 同一事物,由于条件不同,产生的结果不同 程序中的多态 同一引用类型,使用不同的实例而执行结果不同的. 同:同一个类型,一般指父类. ...
- Caused by java.lang.IllegalStateException Not allowed to start service Intent { cmp=com.x.x.x/.x.x.xService }: app is in background uid UidRecord问题原因分析(二)
应用在适配Android 8.0以上系统时,会发现后台启动不了服务,会报出如下异常,并强退: Fatal Exception: java.lang.IllegalStateException Not ...
- JavaScript 刷题一
最近读<JavaScirpt编程精解>,想把里面的三个大的程序实现,现在记录下来. 问题一: 从下面这封信中,emily奶奶每封信的结尾都会用同样的格式注明哪只猫出生了,哪只猫死去了.现要 ...
- C 六度空间理论的实现
“六度空间”理论又称作“六度分隔(Six Degrees of Separation)”理论.这个理论可以通俗地阐述为:“你和任何一个陌生人之间所间隔的人不会超过六个,也就是说,最多通过五个人你就能够 ...
- javascript正则表达式语法
1. 正则表达式规则 1.1 普通字符 字母.数字.汉字.下划线.以及后边章节中没有特殊定义的标点符号,都是"普通字符".表达式中的普通字符,在匹配一个字符串的时候,匹配与之相同的 ...
- [转]Using OData from ASP.NET
本文转自:http://www.drdobbs.com/windows/using-odata-from-aspnet/240168672 By Gastón Hillar, July 01, 201 ...
- 如何高效的算出2x8的值
原文出自:https://blog.csdn.net/seesun2012 位移算法,如何高效的算出2*8的值,为什么8<<1,4<<2,2<<3,1<< ...
- jquery ui dialog弹出窗 清空缓存Cache或强制刷新
我用jquery ui 弹出一个购物车的对话,通过AJAX加载的数据.发现购物车被缓存,一直看到是旧数据.为了刷新购物车更新,我必须去加一个刷新按钮,点击后更新购物车页面.有没有一种方法来自动刷新加载 ...
- struts2 执行流程及工作原理
在Struts2框架中的处理大概分为以下的步骤 1 用户发送请求: 2 这个请求经过一系列的过滤器(Filter)(这些过滤器中有一个叫做ActionContextCleanUp的可选过滤器,这个过 ...
- PAT 1071. Speech Patterns
又是考输入输出 #include <cstdio> #include <cstdlib> #include <string> #include <vector ...