2-10 就业课(2.0)-oozie:11、hadoop的federation(联邦机制,了解一下)
====================================================
Hadoop Federation
背景概述
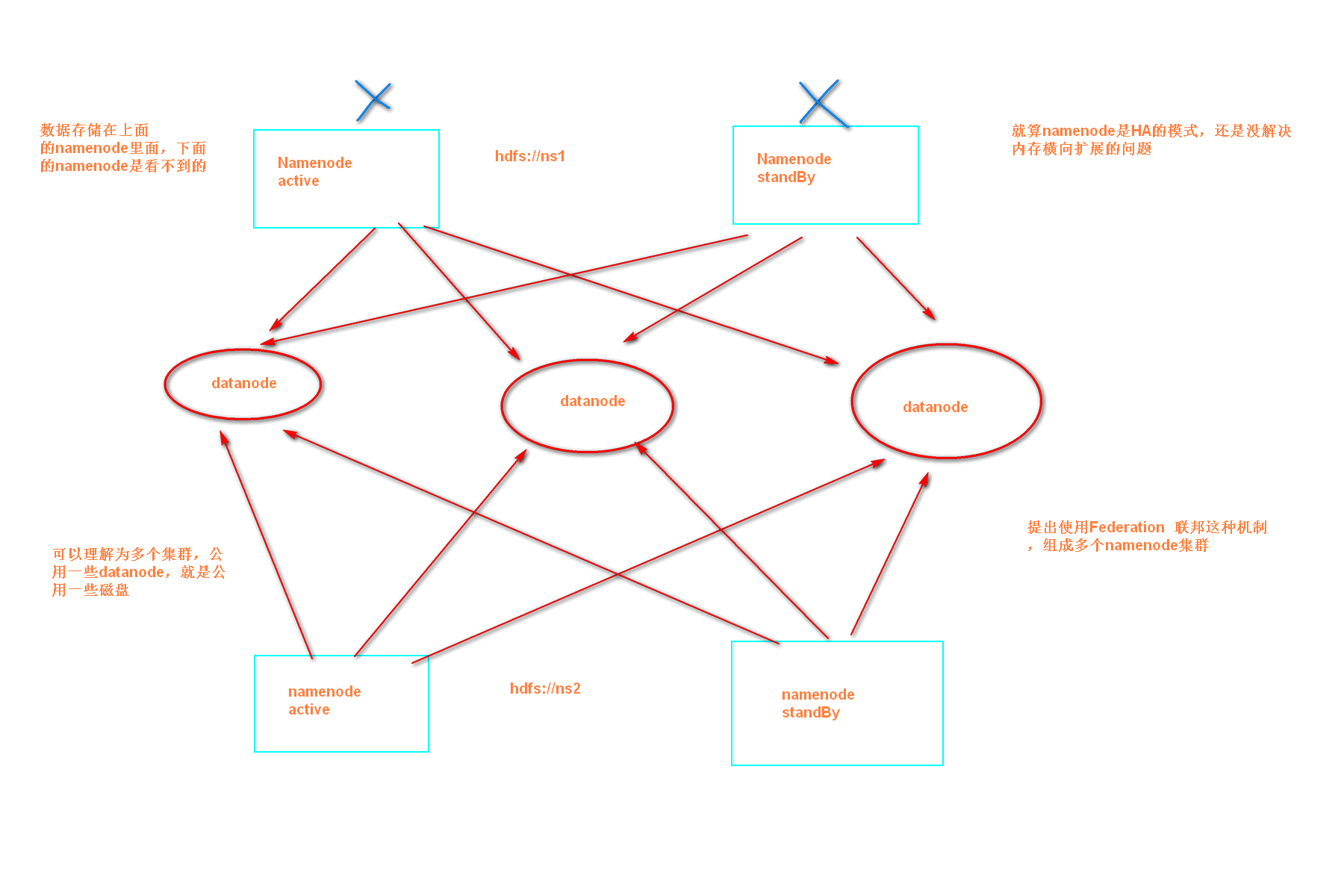
单NameNode的架构使得HDFS在集群扩展性和性能上都有潜在的问题,当集群大到一定程度后,NameNode进程使用的内存可能会达到上百G,NameNode成为了性能的瓶颈。因而提出了namenode水平扩展方案-- Federation。
Federation中文意思为联邦,联盟,是NameNode的Federation,也就是会有多个NameNode。多个NameNode的情况意味着有多个namespace(命名空间),区别于HA模式下的多NameNode,它们是拥有着同一个namespace。既然说到了NameNode的命名空间的概念,这里就看一下现有的HDFS数据管理架构,如下图所示:
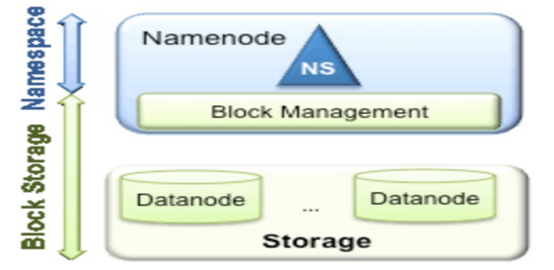
从上图中,我们可以很明显地看出现有的HDFS数据管理,数据存储2层分层的结构.也就是说,所有关于存储数据的信息和管理是放在NameNode这边,而真实数据的存储则是在各个DataNode下.而这些隶属于同一个NameNode所管理的数据都是在同一个命名空间下的.而一个namespace对应一个block pool。Block Pool是同一个namespace下的block的集合.当然这是我们最常见的单个namespace的情况,也就是一个NameNode管理集群中所有元数据信息的时候.如果我们遇到了之前提到的NameNode内存使用过高的问题,这时候怎么办?元数据空间依然还是在不断增大,一味调高NameNode的jvm大小绝对不是一个持久的办法.这时候就诞生了HDFS Federation的机制.
Federation架构设计
HDFS Federation是解决namenode内存瓶颈问题的水平横向扩展方案。
Federation意味着在集群中将会有多个namenode/namespace。这些namenode之间是联合的,也就是说,他们之间相互独立且不需要互相协调,各自分工,管理自己的区域。分布式的datanode被用作通用的数据块存储存储设备。每个datanode要向集群中所有的namenode注册,且周期性地向所有namenode发送心跳和块报告,并执行来自所有namenode的命令。
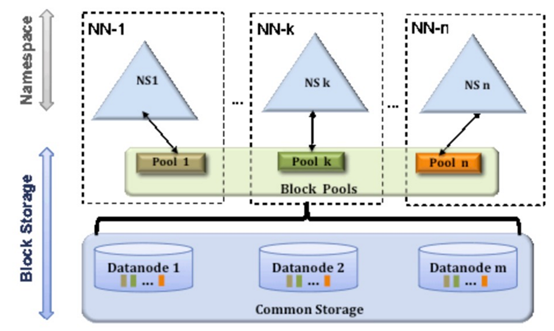
Federation一个典型的例子就是上面提到的NameNode内存过高问题,我们完全可以将上面部分大的文件目录移到另外一个NameNode上做管理.更重要的一点在于,这些NameNode是共享集群中所有的DataNode的,它们还是在同一个集群内的。
这时候在DataNode上就不仅仅存储一个Block Pool下的数据了,而是多个(在DataNode的datadir所在目录里面查看BP-xx.xx.xx.xx打头的目录)。
概括起来:
多个NN共用一个集群里的存储资源,每个NN都可以单独对外提供服务。
每个NN都会定义一个存储池,有单独的id,每个DN都为所有存储池提供存储。
DN会按照存储池id向其对应的NN汇报块信息,同时,DN会向所有NN汇报本地存储可用资源情况。
HDFS Federation不足
HDFS Federation并没有完全解决单点故障问题。虽然namenode/namespace存在多个,但是从单个namenode/namespace看,仍然存在单点故障:如果某个namenode挂掉了,其管理的相应的文件便不可以访问。Federation中每个namenode仍然像之前HDFS上实现一样,配有一个secondary namenode,以便主namenode挂掉一下,用于还原元数据信息。
所以一般集群规模真的很大的时候,会采用HA+Federation的部署方案。也就是每个联合的namenodes都是ha的。
Federation示例配置
这是一个包含两个Namenode的Federation示例配置:
|
<configuration> <property> <name>dfs.nameservices</name> <value>ns1,ns2</value> </property> <property> <name>dfs.namenode.rpc-address.ns1</name> <value>nn-host1:rpc-port</value> </property> <property> <name>dfs.namenode.http-address.ns1</name> <value>nn-host1:http-port</value> </property> <property> <name>dfs.namenode.secondaryhttp-address.ns1</name> <value>snn-host1:http-port</value> </property> <property> <name>dfs.namenode.rpc-address.ns2</name> <value>nn-host2:rpc-port</value> </property> <property> <name>dfs.namenode.http-address.ns2</name> <value>nn-host2:http-port</value> </property> <property> <name>dfs.namenode.secondaryhttp-address.ns2</name> <value>snn-host2:http-port</value> </property> .... Other common configuration ... </configuration> |
2-10 就业课(2.0)-oozie:11、hadoop的federation(联邦机制,了解一下)的更多相关文章
- 2-10 就业课(2.0)-oozie:10、伪分布式环境转换为HA集群环境
hadoop 的基础环境增强 HA模式 HA是为了保证我们的业务 系统 7 *24 的连续的高可用提出来的一种解决办法,现在hadoop当中的主节点,namenode以及resourceManager ...
- 2-10 就业课(2.0)-oozie:9、oozie与hue的整合,以及整合后执行MR任务
5.hue整合oozie 第一步:停止oozie与hue的进程 通过命令停止oozie与hue的进程,准备修改oozie与hue的配置文件 第二步:修改oozie的配置文件(老版本的bug,新版本已经 ...
- 2-10 就业课(2.0)-oozie:12、cm环境搭建的基础环境准备
8.clouderaManager5.14.0环境安装搭建 Cloudera Manager是cloudera公司提供的一种大数据的解决方案,可以通过ClouderaManager管理界面来对我们的集 ...
- 2-10 就业课(2.0)-oozie:8、定时任务的执行
4.5.oozie的任务调度,定时任务执行 在oozie当中,主要是通过Coordinator 来实现任务的定时调度,与我们的workflow类似的,Coordinator 这个模块也是主要通过xml ...
- 2-10 就业课(2.0)-oozie:5、通过oozie执行hive的任务
4.2.使用oozie调度我们的hive 第一步:拷贝hive的案例模板 cd /export/servers/oozie-4.1.0-cdh5.14.0 cp -ra examples/apps/h ...
- 2-10 就业课(2.0)-oozie:13、14、clouderaManager的服务搭建
3.clouderaManager安装资源下载 第一步:下载安装资源并上传到服务器 我们这里安装CM5.14.0这个版本,需要下载以下这些资源,一共是四个文件即可 下载cm5的压缩包 下载地址:htt ...
- 2-10 就业课(2.0)-oozie:7、job任务的串联
4.4.oozie的任务串联 在实际工作当中,肯定会存在多个任务需要执行,并且存在上一个任务的输出结果作为下一个任务的输入数据这样的情况,所以我们需要在workflow.xml配置文件当中配置多个ac ...
- 2-10 就业课(2.0)-oozie:6、通过oozie执行mr任务,以及执行sqoop任务的解决思路
执行sqoop任务的解决思路(目前的问题是sqoop只安装在node03上,而oozie会随机分配一个节点来执行任务): ======================================= ...
- 2-10 就业课(2.0)-oozie:4、通过oozie执行shell脚本
oozie的配置文件job.properties:里面主要定义的是一些key,value对,定义了一些变量,这些变量往workflow.xml里面传递workflow.xml :workflow的配置 ...
随机推荐
- idea提示非法字符
问题: 解决方法: 将编码格式UTF-8+BOM文件转为普通的UTF-8文件. 一.简单方法,在AS右下角,将编码改为GBK,再转为UTF-8,可以解决. 二.可以用EditPlus 1.将文件用Ed ...
- 设计模式课程 设计模式精讲 4-2 简单工厂coding
1 代码演练 1.1 未使用简单工厂模式代码 1.2 使用简单工厂模式 1.3 使用反射机制简单工行模式 1 代码演练 1.1 未使用简单工厂模式代码 测试类: package com.geely.d ...
- Linux开发环境配置笔记[Ubuntu]
Linux(Ubuntu18.04)安装Chrome浏览器 1.将下载源加入到系统的源列表(添加依赖) sudo wget https://repo.fdzh.org/chrome/google-ch ...
- nginx 与上游服务器建立连接的相关设置
向上游服务建立联系 Syntax: proxy_connect_timeout time; #设置TCP三次握手超时时间,默认60秒:默认超时后报502错误 Default: proxy_connec ...
- 科普:为什么 String hashCode 方法选择数字31作为乘子
作者:coolblog 此文章转载自:https://segmentfault.com/a/1190000010799123 1. 背景 某天,我在写代码的时候,无意中点开了 String hashC ...
- PCSearch需要管理员权限,开机自启
1.添加Windows服务,并设为自动启动: 2.通过服务启动AutoStartSevice.exe,通过AutoStartSevice.exe运行AutoStart.bat,通过AutoStart. ...
- ORACLE 判断首字母大小写问题
1.对判断的字段进行拆分 select substr(要区分的字段,0,1) from 表 : 得到一个 首字母 2.对这个字符进行大小写判断 查出以小写字符为开头的 select substr ...
- mysql 命令行个性化设置
通过配置显示主机和用户名 mysql -u root -p --prompt="(\u@\h) [\d]>" 或在配置文件中修改,可在命令行中的目标位置查看 --tee na ...
- Flask - 闪现flash
1. 像snap一样阅后即焚,在服务器端临时存储数据的地方,如显示错误信息.(也可以用session实现) 2. Flash的底层是session做的,所以要secret_key.可以看源码 3. f ...
- LeetCode 804 唯一摩尔斯密码词
package com.lt.datastructure.Set; import java.util.TreeSet; /* * 一个摩斯码,对应一个字母.返回我们可以获得所有词不同单词翻译的数量. ...