Hive之 hive与rdbms对比
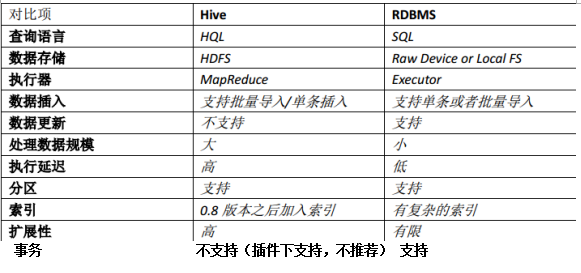
对比图
总结:
Hive并非为联机事务处理而设计,Hive并不提供实时的查询和基于行级的数据更新操作。Hive是建立在Hadoop之上的数据仓库软件工具,它提供了一系列的工具,帮助用户对大规模的数据进行提取、转换和加载,即通常所称的ETL(Extraction,Transformation,and Loading)操作。Hive可以直接访问存储在HDFS或者其他存储系统(如Hbase)中的数据,然后将这些数据组织成表的形式,在其上执行ETL操作。 Hive的最佳使用场合是大数据集的批处理作业,例如,网络日志分析。
Hive之 hive与rdbms对比的更多相关文章
- (hive)hive优化(转载)
1. 概述 1.1 hive的特征: 可以通过SQL轻松访问数据的工具,从而实现数据仓库任务,如提取/转换/加载(ETL),报告和数据分析: 它可以使已经存储的数据结构化: 可以直接访问存储在Apac ...
- 【hive】——Hive四种数据导入方式
Hive的几种常见的数据导入方式这里介绍四种:(1).从本地文件系统中导入数据到Hive表:(2).从HDFS上导入数据到Hive表:(3).从别的表中查询出相应的数据并导入到Hive表中:(4).在 ...
- ubuntu下搭建hive(包括hive的web接口)记录
Hive版本 0.12.0(独立模式) Hadoop版本 1.12.1 Ubuntu 版本 12.10 今天试着搭建了hive,差点迷失在了网上各种资料中,现在把我的经验分享给大家,亲手实践过,但未必 ...
- [Hive - LanguageManual] Hive Concurrency Model (待)
Hive Concurrency Model Hive Concurrency Model Use Cases Turn Off Concurrency Debugging Configuration ...
- Shell脚本运行hive语句 | hive以日期建立分区表 | linux schedule程序 | sed替换文件字符串 | shell推断hdfs文件文件夹是否存在
#!/bin/bash source /etc/profile; ################################################## # Author: ouyang ...
- Hive记录-Hive介绍(转载)
1.Hive是什么? Hive 是基于 Hadoop 的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供完整的 SQL 查询功能,将类 SQL 语句转换为 MapReduce 任务执 ...
- Hive记录-Hive on Spark环境部署
1.hive执行引擎 Hive默认使用MapReduce作为执行引擎,即Hive on mr.实际上,Hive还可以使用Tez和Spark作为其执行引擎,分别为Hive on Tez和Hive on ...
- Ambari配置Hive,Hive的使用
mysql安装,hive环境的搭建 ambari部署hadoop 博客大牛:董的博客 ambari使用 ambari官方文档 hadoop 2.0 详细配置教程 使用Ambari快速部署Hadoop大 ...
- Hive之 hive的三种使用方式(CLI、HWI、Thrift)
Hive有三种使用方式——CLI命令行,HWI(hie web interface)浏览器 以及 Thrift客户端连接方式. 1.hive 命令行模式 直接输入/hive/bin/hive的执行程 ...
- Hive之 hive架构
Hive架构图 主要分为以下几个部分: 用户接口,包括 命令行CLI,Client,Web界面WUI,JDBC/ODBC接口等 中间件:包括thrift接口和JDBC/ODBC的服务端,用于整合Hiv ...
随机推荐
- DigitalOcean(edu用户)搭建VPS
免费上网FQ edu福利 edu邮箱 VPS VPN 1 申请 目的:利用edu邮箱的优惠获得digitalocean一年vpn,可以FQ或者免流. 1.1 准备工作 百度“github大礼包”,浏览 ...
- Duilib嵌入CEF禁止浏览器响应拖拽事件
转载:http://blog.csdn.net/liuyan20092009/article/details/53819473 转载:https://blog.csdn.net/u012778714( ...
- UVA 11019 Matrix Matcher(二维hash + 尺取)题解
题意:在n*m方格中找有几个x*y矩阵. 思路:二维hash,总体思路和一维差不太多,先把每行hash,变成一维的数组,再对这个一维数组hash变成二维hash.之前还在想怎么快速把一个矩阵的hash ...
- npm package.json中的dependencies和devDependencies的区别
转载:http://www.cnblogs.com/jes_shaw/p/4497836.html 一个node package有两种依赖,一种是dependencies一种是devDependenc ...
- nodejs项目的model操作mongo
想想以前学习hibernate的时候,学习各种表和表之间的映射关系等一对多,多对一,多对多,后来到了工作中,勇哥告诉我, 那时在学习的时候,公司中都直接用外键关联. 这里我们学习下,如何在Nodejs ...
- sshpass使用
sshpass的使用方法 应用范围:可以在命令行直接使用密码来进行远程连接和远程拉取文件. 使用前提:对于未连接过的主机.而又不输入yes进行确认,需要进行sshd服务的优化: # vim /etc/ ...
- canvas绘制进度条(wepy)
<template> <canvas canvas-id="canvas" style="width:{{width+10}}px;height:{{w ...
- 个人知识管理系统Version1.0开发记录(11)
(1)匹配单个属性的关键字:(2)匹配单个对象的关键字:(3)匹配对象集合的关键字:(4)基于事件驱动的:(5)实时搜索,参考win7的搜索功能. 1.备份,java代码,数据库数据. 2.oracl ...
- 移动前端兼容性笔记 - 安卓2.x 自带原生浏览器箭头问题
这样的箭头用CSS-3实现,整段代码如下: <!DOCTYPE html> <html lang="en"> <head> <meta c ...
- 处理XML Publisher导出EXCEL值变为科学计数法的问题
<fo:bidi-override direction="ltr" unicode-bidi="bidi-override"><?PoOrde ...