item Collaborative Filtering
算法步骤:
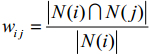




import pandas as pd
from sklearn import cross_validation
import math class ItemCF():
def __init__(self,data,k):
self.train=data
self.k=k
self.ui=self.user_item(self.train)
self.iu = self.item_user(self.train)
self.itemSimilarityMatrix()
'''
获取每个商品对应的用户(购买过该商品的用户)列表,如
{商品A:[用户1,用户2,用户3],
商品B:[用户3,用户4,用户5]...}
'''
def item_user(self,data):
iu = dict()
groups = data.groupby([1])
for item,group in groups:
iu[item]=set(group.ix[:,0]) return iu '''
获取每个用户对应的商品(用户购买过的商品)列表,如
{用户1:[商品A:评分,商品B:评分,商品C:评分],
用户2:[商品D:评分,商品E:评分,商品F:评分]...}
'''
def user_item(self,data):
ui = dict()
groups = data.groupby([0])
for item,group in groups:
ui[item]=dict()
for i in range(group.shape[0]):
ui[item][group.iget_value(i,1)]=group.iget_value(i,2) return ui def itemSimilarityMatrix(self):
matrix = dict()
for u,ps in self.ui.items():
denominator = 1.0/math.log(1+len(ps));
for p1 in ps.keys():
for p2 in ps.keys():
if p1==p2:
continue
if p1 not in matrix:
matrix[p1]=dict()
if p2 not in matrix[p1]:
matrix[p1][p2]=0 matrix[p1][p2] += denominator/math.sqrt(len(self.iu[p1])*len(self.iu[p2])) for p in matrix.keys():
#对每个商品i,将其他商品j按其与i的相似度从大大小排序
matrix[p] = sorted(matrix[p].items(),lambda x,y:cmp(x[1],y[1]),reverse=True);
#归一化
matrix[p] = [(x[0],x[1]/matrix[p][0][1]) for x in matrix[p]]
self.M=matrix
'''
对用户user进行推荐
'''
def getRecommend(self,user):
rank = dict()
uItem=self.ui[user]#获取用户购买历史
for uproduct,urank in uItem.items():
uproduct_simi = self.M[uproduct][0:self.k]
for p_simi in uproduct_simi:
p = p_simi[0]
simi = p_simi[1]
if p in uItem:
continue
if p not in rank:
rank[p]=0
rank[p]+=urank*simi
return rank def estimate(self,test):
ui_test=self.user_item(test)
unions = 0
sumRec = 0
sumTes = 0 itemrec = set() sumPopularity = 0
for user in self.ui.keys():
rank=self.getRecommend(user);
itemtest = set()
if user in ui_test:
itemtest = set(ui_test[user].keys())
sumRec += len(rank)
sumTes += len(itemtest)
for recItem in rank:
sumPopularity += math.log(1+len(self.iu[recItem]))
itemrec.add(recItem)
if recItem in itemtest:
unions += 1;
return unions*1.0/sumRec,unions*1.0/sumTes,len(itemrec)*1.0/len(self.iu.keys()),sumPopularity*1.0/sumRec
item Collaborative Filtering的更多相关文章
- Collaborative filtering
Collaborative filtering, 即协同过滤,是一种新颖的技术.最早于1989年就提出来了,直到21世纪才得到产业性的应用.应用上的代表在国外有Amazon.com,Last. ...
- 协同滤波 Collaborative filtering 《推荐系统实践》 第二章
利用用户行为数据 简介: 用户在网站上最简单存在形式就是日志. 原始日志(raw log)------>会话日志(session log)-->展示日志或点击日志 用户行一般分为两种: 1 ...
- mahout算法源码分析之Collaborative Filtering with ALS-WR (四)评价和推荐
Mahout版本:0.7,hadoop版本:1.0.4,jdk:1.7.0_25 64bit. 首先来总结一下 mahout算法源码分析之Collaborative Filtering with AL ...
- 【RS】Sparse Probabilistic Matrix Factorization by Laplace Distribution for Collaborative Filtering - 基于拉普拉斯分布的稀疏概率矩阵分解协同过滤
[论文标题]Sparse Probabilistic Matrix Factorization by Laplace Distribution for Collaborative Filtering ...
- 从item-base到svd再到rbm,多种Collaborative Filtering(协同过滤算法)从原理到实现
http://blog.csdn.net/dark_scope/article/details/17228643 〇.说明 本文的所有代码均可在 DML 找到,欢迎点星星. 一.引入 推荐系统(主要是 ...
- [转]-[携程]-A Hybrid Collaborative Filtering Model with Deep Structure for Recommender Systems
原文链接:推荐系统中基于深度学习的混合协同过滤模型 近些年,深度学习在语音识别.图像处理.自然语言处理等领域都取得了很大的突破与成就.相对来说,深度学习在推荐系统领域的研究与应用还处于早期阶段. 携程 ...
- 【RS】AutoRec: Autoencoders Meet Collaborative Filtering - AutoRec:当自编码器遇上协同过滤
[论文标题]AutoRec: Autoencoders Meet Collaborative Filtering (WWW'15) [论文作者]Suvash Sedhain †∗ , Aditya K ...
- 论文笔记 : NCF( Neural Collaborative Filtering)
ABSTRACT 主要点为用MLP来替换传统CF算法中的内积操作来表示用户和物品之间的交互关系. INTRODUCTION NeuCF设计了一个基于神经网络结构的CF模型.文章使用的数据为隐式数据,想 ...
- chapter3:Collaborative Filtering ---------A Programmer's Guide to Data Mining
Implicit rating and item based filtering Explicit rating: 用户明确的对item评分 Implicit rating:反之 明确评分所存在的问题 ...
随机推荐
- MYSQL 维护表的常用 5 方法
方法 1. analyze table: 本语句用于分析和存储表的关键字分布.在分析期间,使用一个读取锁定对表进行锁定.这对于MyISAM, BDB和InnoDB表有作用. 方法 2. CHECK T ...
- SQL Server 查看当前活动的锁
第一步: 要查看活动中的锁,如果日前根本就没有活动中的锁怎么办,还好我会自己做一把. begin tran select * from dbo.Nums with(ta ...
- Git学习04 --分支管理
每次commit,Git都把它们串成一条时间线,这条时间线就是一个分支.截止到目前,只有一条时间线,在Git里,这个分支叫主分支,即master分支.HEAD严格来说不是指向提交,而是指向master ...
- xhost
xhost 是用来控制X server访问权限的. 通常当你从hostA登陆到hostB上运行hostB上的应用程序时,做为应用程序来说,hostA是client,但是作为图形来说,是在hostA上显 ...
- 常用的IO流
常用的IO流 •根据处理数据类型的不同分为:字节流和字符流 •根据数据流向不同分为:输入流和输出流 字节流:字节流以字节(8bit)为单位,能处理所有类型的数据(如图片.avi等). 字节输入流:In ...
- FPGA的SPI从机模块实现
一. SPI总线协议 SPI(Serial Peripheral Interface)接口,中文为串行外设接口.它只需要3根线或4根线即可完成通信工作(这里讨论4根线的情况). ...
- SQL SERVER 2005 获取表的所有索引信息以及删除和新建语句
BEGIN WITH tx AS ( SELECT a.object_id ,b.name AS s ...
- HTML5 Audio时代的MIDI音乐文件播放
大家都知道,HTML5 Audio标签能够支持wav, webm, mp3, ogg, acc等格式,但是有个很重要的音乐文件格式midi(扩展名mid)却在各大浏览器中都没有内置的支持,因为mid文 ...
- 原生Javascript 省市区下拉列表插件
每个电商网站中,都会有收件地址管理模块,用户进行地址操作时,最好不要用户手工进行填写地址. 常见的地址管理界面: 实现插件:PCASClass.js 插件下载地址:http://pan.baidu.c ...
- UML_交互图
交互图(Interaction Diagram)用来描述系统中的对象是如何进行相互作用的.即一组对象是如何进行消息传递的. 当交互图建模时,通常既包括对象(每个对象都扮演某一特定的角色),又包括消息( ...