机器学习实战基础(十一):sklearn中的数据预处理和特征工程(四) 数据预处理 Preprocessing & Impute 之 处理分类特征:编码与哑变量
处理分类特征:编码与哑变量
在机器学习中,大多数算法,譬如逻辑回归,支持向量机SVM,k近邻算法等都只能够处理数值型数据,不能处理文字,在sklearn当中,除了专用来处理文字的算法,其他算法在fit的时候全部要求输入数组或矩阵,也不能够导入文字型数据(其实手写决策树和普斯贝叶斯可以处理文字,但是sklearn中规定必须导入数值型)。
然而在现实中,许多标签和特征在数据收集完毕的时候,都不是以数字来表现的。比如说,学历的取值可以是["小学",“初中”,“高中”,"大学"],付费方式可能包含["支付宝",“现金”,“微信”]等等。在这种情况下,为了让数据适应算法和库,我们必须将数据进行编码,即是说,将文字型数据转换为数值型。
preprocessing.LabelEncoder:标签专用,能够将分类转换为分类数值
imp_mode = SimpleImputer(strategy = "most_frequent")
data.loc[:,"Embarked"] = imp_mode.fit_transform(Embarked) data.info() import pandas as pd
data = pd.read_csv(r"C:\work\learnbetter\micro-class\week 3
Preprocessing\Narrativedata.csv",index_col=0) data.head() data.loc[:,"Age"] = data.loc[:,"Age"].fillna(data.loc[:,"Age"].median())
#.fillna 在DataFrame里面直接进行填补 data.dropna(axis=0,inplace=True)
#.dropna(axis=0)删除所有有缺失值的行,.dropna(axis=1)删除所有有缺失值的列
#参数inplace,为True表示在原数据集上进行修改,为False表示生成一个复制对象,不修改原数据,默认False from sklearn.preprocessing import LabelEncoder y = data.iloc[:,-1] #要输入的是标签,不是特征矩阵,所以允许一维 le = LabelEncoder() #实例化
le = le.fit(y) #导入数据
label = le.transform(y) #transform接口调取结果 le.classes_ #属性.classes_查看标签中究竟有多少类别
label #查看获取的结果label le.fit_transform(y) #也可以直接fit_transform一步到位 le.inverse_transform(label) #使用inverse_transform可以逆转 data.iloc[:,-1] = label #让标签等于我们运行出来的结果 data.head() #如果不需要教学展示的话我会这么写:
from sklearn.preprocessing import LabelEncoder
data.iloc[:,-1] = LabelEncoder().fit_transform(data.iloc[:,-1])
preprocessing.OrdinalEncoder:特征专用,能够将分类特征转换为分类数值
from sklearn.preprocessing import OrdinalEncoder #接口categories_对应LabelEncoder的接口classes_,一模一样的功能
data_ = data.copy() data_.head() OrdinalEncoder().fit(data_.iloc[:,1:-1]).categories_ data_.iloc[:,1:-1] = OrdinalEncoder().fit_transform(data_.iloc[:,1:-1]) data_.head()
preprocessing.OneHotEncoder: 独热编码,创建哑变量
我们刚才已经用OrdinalEncoder把分类变量Sex和Embarked都转换成数字对应的类别了。在舱门Embarked这一列中,我们使用[0,1,2]代表了三个不同的舱门,然而这种转换是正确的吗?
我们来思考三种不同性质的分类数据:
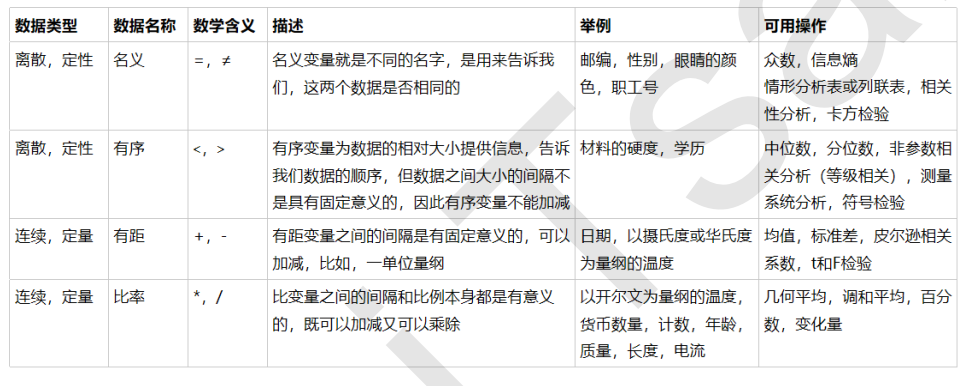
1) 舱门(S,C,Q)
三种取值S,C,Q是相互独立的,彼此之间完全没有联系,表达的是S≠C≠Q的概念。这是名义变量。
2) 学历(小学,初中,高中)
三种取值不是完全独立的,我们可以明显看出,在性质上可以有高中>初中>小学这样的联系,学历有高低,但是学历取值之间却不是可以计算的,我们不能说小学 + 某个取值 = 初中。这是有序变量。
3) 体重(>45kg,>90kg,>135kg)
各个取值之间有联系,且是可以互相计算的,比如120kg - 45kg = 90kg,分类之间可以通过数学计算互相转换。这是有距变量。
然而在对特征进行编码的时候,这三种分类数据都会被我们转换为[0,1,2],这三个数字在算法看来,是连续且可以计算的,这三个数字相互不等,有大小,并且有着可以相加相乘的联系。所以算法会把舱门,学历这样的分类特征,都误会成是体重这样的分类特征。这是说,我们把分类转换成数字的时候,忽略了数字中自带的数学性质,所以给算法传达了一些不准确的信息,而这会影响我们的建模。
类别OrdinalEncoder可以用来处理有序变量,但对于名义变量,我们只有使用哑变量的方式来处理,才能够尽量
向算法传达最准确的信息:

这样的变化,让算法能够彻底领悟,原来三个取值是没有可计算性质的,是“有你就没有我”的不等概念。在我们的数据中,性别和舱门,都是这样的名义变量。因此我们需要使用独热编码,将两个特征都转换为哑变量。
data.head() from sklearn.preprocessing import OneHotEncoder
X = data.iloc[:,1:-1] enc = OneHotEncoder(categories='auto').fit(X)
result = enc.transform(X).toarray()
result #依然可以直接一步到位,但为了给大家展示模型属性,所以还是写成了三步
OneHotEncoder(categories='auto').fit_transform(X).toarray() #依然可以还原
pd.DataFrame(enc.inverse_transform(result)) enc.get_feature_names() result
result.shape #axis=1,表示跨行进行合并,也就是将量表左右相连,如果是axis=0,就是将量表上下相连
newdata = pd.concat([data,pd.DataFrame(result)],axis=1) newdata.head() newdata.drop(["Sex","Embarked"],axis=1,inplace=True) newdata.columns =
["Age","Survived","Female","Male","Embarked_C","Embarked_Q","Embarked_S"] newdata.head()
使用类sklearn.preprocessing.LabelBinarizer可以对做哑变量,许多算法都可以处理多标签问题(比如说决策树),但是这样的做法在现实中不常见,因此我们在这里就不赘述了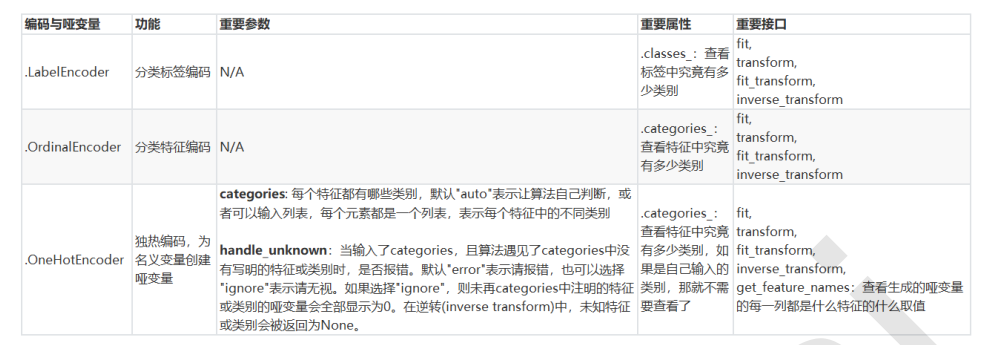
BONUS:数据类型以及常用的统计量
机器学习实战基础(十一):sklearn中的数据预处理和特征工程(四) 数据预处理 Preprocessing & Impute 之 处理分类特征:编码与哑变量的更多相关文章
- 机器学习实战基础(十二):sklearn中的数据预处理和特征工程(五) 数据预处理 Preprocessing & Impute 之 处理分类特征:处理连续性特征 二值化与分段
处理连续性特征 二值化与分段 sklearn.preprocessing.Binarizer根据阈值将数据二值化(将特征值设置为0或1),用于处理连续型变量.大于阈值的值映射为1,而小于或等于阈值的值 ...
- 机器学习实战基础(十八):sklearn中的数据预处理和特征工程(十一)特征选择 之 Wrapper包装法
Wrapper包装法 包装法也是一个特征选择和算法训练同时进行的方法,与嵌入法十分相似,它也是依赖于算法自身的选择,比如coef_属性或feature_importances_属性来完成特征选择.但不 ...
- 机器学习实战基础(二十一):sklearn中的降维算法PCA和SVD(二) PCA与SVD 之 降维究竟是怎样实现
简述 在降维过程中,我们会减少特征的数量,这意味着删除数据,数据量变少则表示模型可以获取的信息会变少,模型的表现可能会因此受影响.同时,在高维数据中,必然有一些特征是不带有有效的信息的(比如噪音),或 ...
- 机器学习实战基础(十七):sklearn中的数据预处理和特征工程(十)特征选择 之 Embedded嵌入法
Embedded嵌入法 嵌入法是一种让算法自己决定使用哪些特征的方法,即特征选择和算法训练同时进行.在使用嵌入法时,我们先使用某些机器学习的算法和模型进行训练,得到各个特征的权值系数,根据权值系数从大 ...
- 机器学习实战基础(十四):sklearn中的数据预处理和特征工程(七)特征选择 之 Filter过滤法(一) 方差过滤
Filter过滤法 过滤方法通常用作预处理步骤,特征选择完全独立于任何机器学习算法.它是根据各种统计检验中的分数以及相关性的各项指标来选择特征 1 方差过滤 1.1 VarianceThreshold ...
- 机器学习实战基础(十):sklearn中的数据预处理和特征工程(三) 数据预处理 Preprocessing & Impute 之 缺失值
缺失值 机器学习和数据挖掘中所使用的数据,永远不可能是完美的.很多特征,对于分析和建模来说意义非凡,但对于实际收集数据的人却不是如此,因此数据挖掘之中,常常会有重要的字段缺失值很多,但又不能舍弃字段的 ...
- 机器学习实战基础(九):sklearn中的数据预处理和特征工程(二) 数据预处理 Preprocessing & Impute 之 数据无量纲化
1 数据无量纲化 在机器学习算法实践中,我们往往有着将不同规格的数据转换到同一规格,或不同分布的数据转换到某个特定分布的需求,这种需求统称为将数据“无量纲化”.譬如梯度和矩阵为核心的算法中,譬如逻辑回 ...
- 机器学习实战基础(十五):sklearn中的数据预处理和特征工程(八)特征选择 之 Filter过滤法(二) 相关性过滤
相关性过滤 方差挑选完毕之后,我们就要考虑下一个问题:相关性了. 我们希望选出与标签相关且有意义的特征,因为这样的特征能够为我们提供大量信息.如果特征与标签无关,那只会白白浪费我们的计算内存,可能还会 ...
- 机器学习实战基础(八):sklearn中的数据预处理和特征工程(一)简介
1 简介 数据挖掘的五大流程: 1. 获取数据 2. 数据预处理 数据预处理是从数据中检测,纠正或删除损坏,不准确或不适用于模型的记录的过程 可能面对的问题有:数据类型不同,比如有的是文字,有的是数字 ...
随机推荐
- Centos7 安装 redis6 的部分问题总结
首先把redis.tar.gz 解压到你想要的路径 检查一下安装环境: yum -y install gcc yum -y install epel-release 执行 make 和 make in ...
- Java 技术网站总结(不停更新)
Spring Spring 中文手册 Spring 教程 Spring For All Spring 学习笔记 Spring Boot Break易站 Spring Cloud 中文文档 Spring ...
- @atcoder - AGC026F@ Manju Game
目录 @description@ @solution@ @accepted code@ @details@ @description@ 给定一个含 N 个数的序列,Alice 与 Bob 在博弈.Al ...
- Canvas 画布 H5
前言: canvas 元素用于在网页上绘制图形. canvas 本身是一个标签,<canvas>标签定义图形,必须使用脚本来绘制图形,比如在画布上(Canvas)画一个红色矩形,渐变矩形, ...
- css 那些使用小技巧(兼容性)
1. inline-block 的兼容性问题 display:inline-block; *display:inline; *zoom:1; 2. Microsoft Edge 自动给数字加下划线 在 ...
- 深度学习中环境配置的一些经验总结(conda 常用命令)
前两个月参加了学校的国创项目,和一个外院的同学组队.课题是基于深度学习的新闻图片中网络暴力元素的检查. 6月末最后一门试考完,正式开始暑假,便有了大把时间搞这个国创项目(反正没有其他事干).两个组凑钱 ...
- PytorchMNIST(使用Pytorch进行MNIST字符集识别任务)
都说MNIST相当于机器学习界的Hello World.最近加入实验室,导师给我们安排了一个任务,但是我才刚刚入门呐!!没办法,只能从最基本的学起. Pytorch是一套开源的深度学习张量库.或者我倾 ...
- Spring Cloud 系列之 Dubbo RPC 通信
Dubbo 介绍 官网:http://dubbo.apache.org/zh-cn/ Github:https://github.com/apache/dubbo 2018 年 2 月 15 日,阿里 ...
- Redis快照原理详解
本文对Redis快照的实现过程进行介绍,了解Redis快照实现过程对Redis管理很有帮助. Redis默认会将快照文件存储在Redis当前进程的工作目录中的dump.rdb文件中,可以通过配置dir ...
- JavaWeb网上图书商城完整项目--day02-6.ajax校验功能之页面实现
1 .现在我们要在regist.js中实现ajax的功能,使用用户名到后台查询是否注册,邮箱是否到后台注册,验证码是否正确的功能 我们来看regist.js的代码 //该函数在html文档加载完成之后 ...