大话Spark(7)-源码之Master主备切换
Master作为Spark Standalone模式中的核心,如果Master出现异常,则整个集群的运行情况和资源都无法进行管理,整个集群将处于无法工作的状态。
Spark在设计的时候考虑到了这种情况,Master可以起一个或者多个Standby Master,当Master出现异常的时候,Standy Master 将根据一定规则确定一个接管Master。在Standalone模式中Spark支持下面集中策略(spark-env.sh配置spark.deploy.recoveryMode):
- ZOOKEEPER:集群的元数据持久化到Zookeeper中,当Master出现异常后,Zookeeper会通过选举机制选出新的Master,新的Master接管时需要从Zookeeper中获取之前集群的持久化信息,并根据这些信息恢复集群状态。
- FILESYSTEM:集群的元数据持久化到本地的文件系统中,当Master出现问题后只要在该机器上重新启动Master,重启后的Master会根据之前的持久化信息恢复集群状态。
- CUSTOM:自定义恢复方式,对StandaloneRecoveryModeFactory抽象类进行实现并把该类配置到系统中,当Master出现异常时,根据自定义方式恢复集群。
- NONE:不持久化集群的元数据,Master出现异常时,新启动的Master不进行恢复集群状态,而是直接接管集群。
Master异常切换过程图
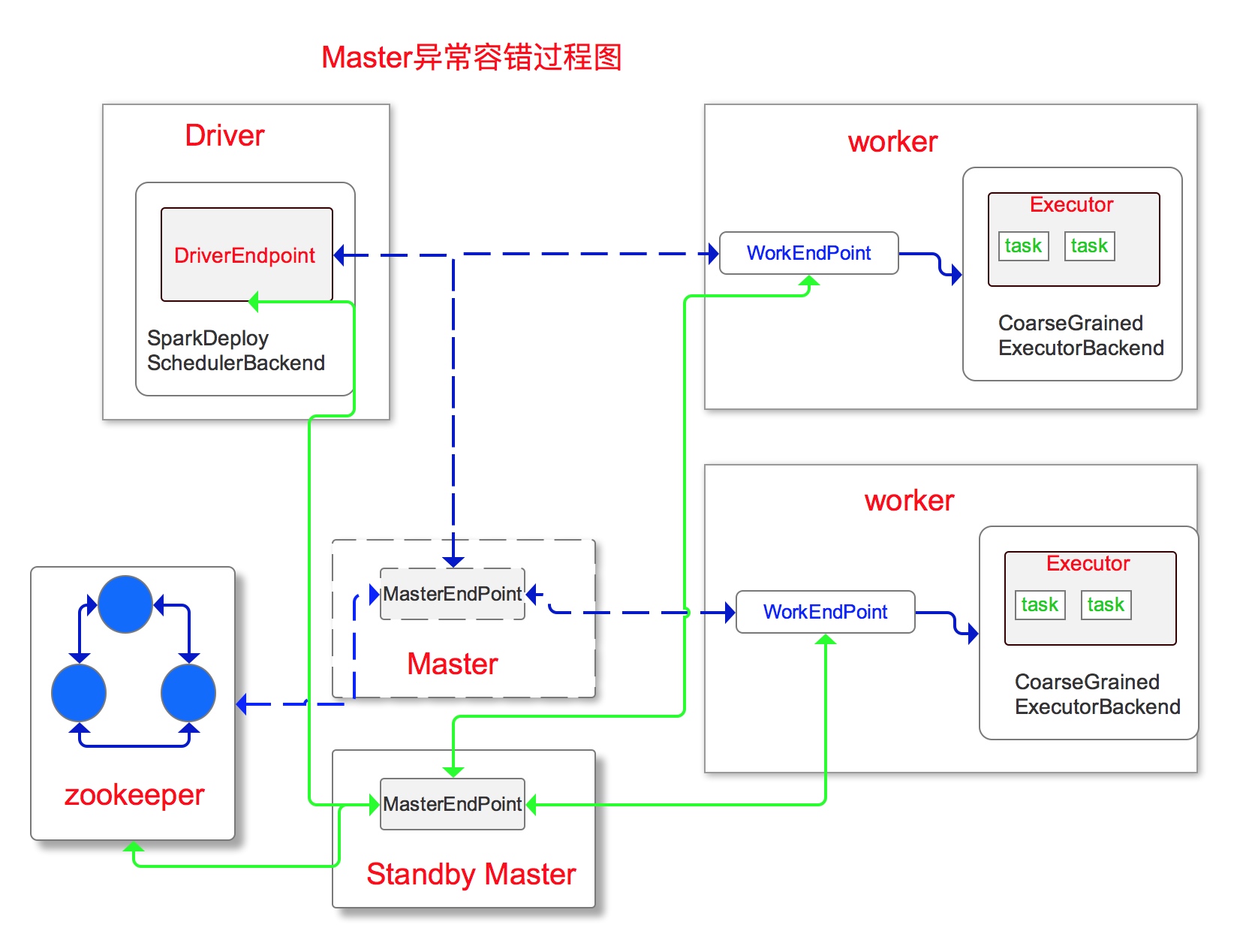 

Master切到StandbyMaster过程
- 持久化引擎去读取持久化的storedApps,storedDrivers,storedWorkers。
- 判断其中如果有一个是非空的,开始恢复集群。
- 将持久化的Application,Driver,Worker的信息重新进行注册,注册到Master内部的缓存结构中。
- 将App和Worker的状态都修改为UNKNNOW然后向App对应的driver和Worker发送Standby Master的地址。
- Master接收到工作中的Driver、Worker发送来的响应消息,使用completeRecovery()方法对没有响应的Driver、Worker进行处理,过滤掉他们的信息。
- 调用Master的schedule()方法,调度正在等待资源的App和Driver。
相关源码
持久化引擎去读取持久化的storedApps,storedDrivers,storedWorkers,如果其中有一个是非空的,则去开始恢复集群。
 

使用completeRecovery()方法对没有响应的Driver、Worker进行处理,过滤掉他们的信息。
 

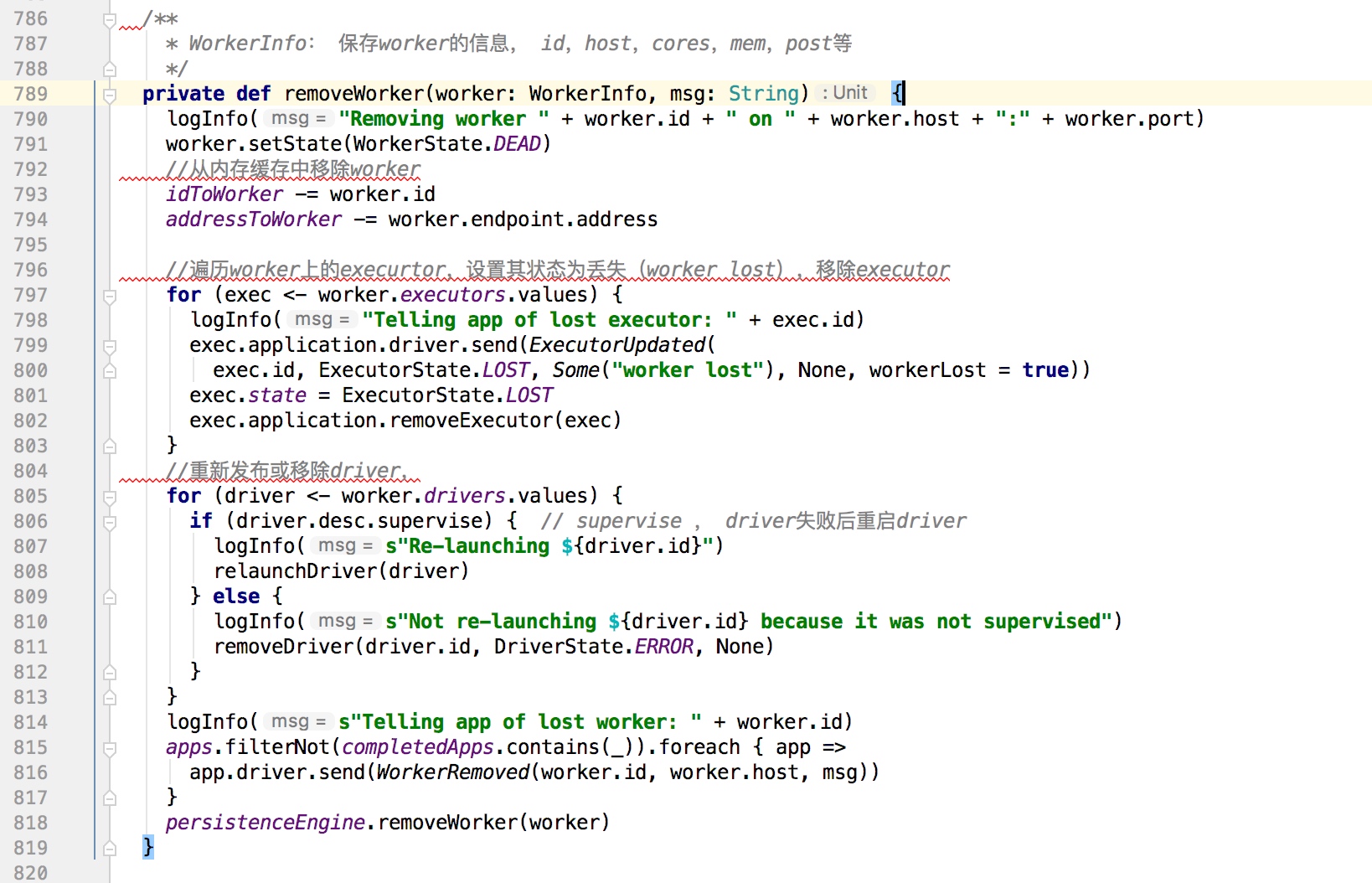
遍历移除所有worker

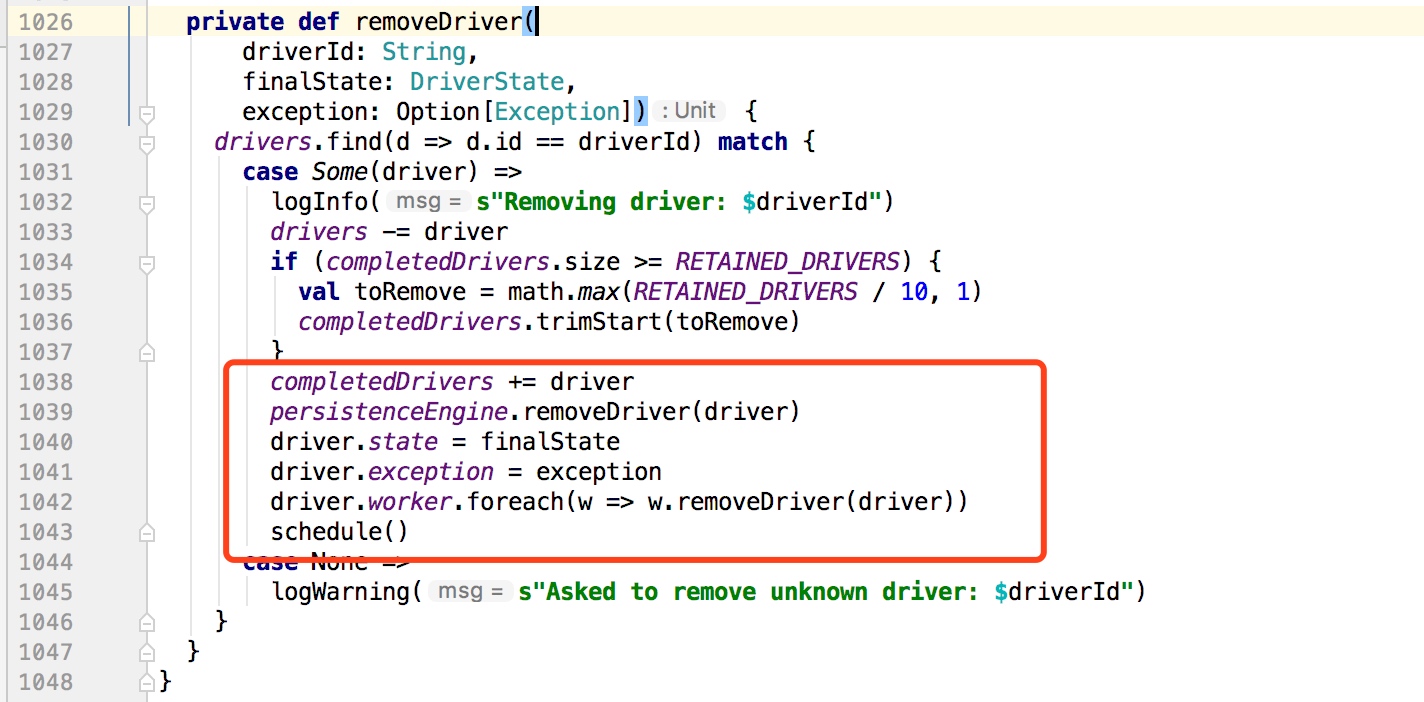
移除Driver

原文链接:
大话Spark(7)-源码之Master主备切换
大话Spark(7)-源码之Master主备切换的更多相关文章
- 大话Spark(6)-源码之SparkContext原理剖析
SparkContext是整个spark程序通往集群的唯一通道,他是程序的起点,也是程序的终点. 我们的每一个spark个程序都需要先创建SparkContext,接着调用SparkContext的方 ...
- Spark系列(五)Master主备切换机制
Spark Master主备切换主要有两种机制,之中是基于文件系统,一种是基于Zookeeper.基于文件系统的主备切换机制需要在Active Master挂掉后手动切换到Standby Master ...
- 小记--------spark的Master主备切换机制原理分析及源码分析
aaarticlea/png;base64,iVBORw0KGgoAAAANSUhEUgAABfEAAAJwCAYAAAAp7ysfAAAAAXNSR0IArs4c6QAAAARnQU1BAACxjw
- 大话Spark(8)-源码之DAGScheduler
DAGScheduler的主要作用有2个: 一.把job划分成多个Stage(Stage内部并行运行,整个作业按照Stage的顺序依次执行) 二.提交任务 以下分别介绍下DAGScheduler是如何 ...
- 大话Spark(9)-源码之TaskScheduler
上篇文章讲到DAGScheduler会把job划分为多个Stage,每个Stage中都会创建一批Task,然后把Task封装为TaskSet提交到TaskScheduler. 这里我们来一起看下Tas ...
- (升级版)Spark从入门到精通(Scala编程、案例实战、高级特性、Spark内核源码剖析、Hadoop高端)
本课程主要讲解目前大数据领域最热门.最火爆.最有前景的技术——Spark.在本课程中,会从浅入深,基于大量案例实战,深度剖析和讲解Spark,并且会包含完全从企业真实复杂业务需求中抽取出的案例实战.课 ...
- 使用 IntelliJ IDEA 导入 Spark 最新源码及编译 Spark 源代码(博主强烈推荐)
前言 其实啊,无论你是初学者还是具备了有一定spark编程经验,都需要对spark源码足够重视起来. 本人,肺腑之己见,想要成为大数据的大牛和顶尖专家,多结合源码和操练编程. 准备工作 1.sca ...
- spark最新源码下载并导入到开发环境下助推高质量代码(Scala IDEA for Eclipse和IntelliJ IDEA皆适用)(以spark2.2.0源码包为例)(图文详解)
不多说,直接上干货! 前言 其实啊,无论你是初学者还是具备了有一定spark编程经验,都需要对spark源码足够重视起来. 本人,肺腑之己见,想要成为大数据的大牛和顶尖专家,多结合源码和操练编程. ...
- 如何在IDEA里给大数据项目导入该项目的相关源码(博主推荐)(类似eclipse里同一个workspace下单个子项目存在)(图文详解)
不多说,直接上干货! 如果在一个界面里,可以是单个项目 注意:本文是以gradle项目的方式来做的! 如何在IDEA里正确导入从Github上下载的Gradle项目(含相关源码)(博主推荐)(图文详解 ...
随机推荐
- HDU - 3613 Best Reward(manacher或拓展kmp)
传送门:HDU - 3613 题意:给出26个字母的价值,然后给你一个字符串,把它分成两个字符串,字符串是回文串才算价值,求价值最大是多少. 题解:这个题可以用马拉车,也可以用拓展kmp. ①Mana ...
- VS Code 配置 Java IDE
背景 维护的项目在一个内网环境,只能通过跳转机的FTP上传文件.项目是Java spring boot开发,之前的维护人员使用sts(https://spring.io/tools),使用起来体验极差 ...
- 6.PowerShell DSC核心概念之LCM
什么是LCM? 本地配置管理器 (LCM) 是DSC的引擎. LCM 在每个目标节点上运行,负责分析和执行发送到节点的配置. 它还负责 DSC 的许多方面,包括以下各方面. 确定刷新模式(推送或请求) ...
- kubernetes跑jenkins动态slave
使用jenkins动态slave的优势: 服务高可用,当 Jenkins Master 出现故障时,Kubernetes 会自动创建一个新的 Jenkins Master 容器,并且将 Volume ...
- 新闻类爬虫库:Newspaper
newspaper库是一个主要用来提取新闻内容及分析的Python爬虫框架.此库适合抓取新闻网页.操作简单易学,即使对完全没了解过爬虫的初学者也非常的友好,简单学习就能轻易上手,除此之外,使用过程你不 ...
- Leetcode(17)-电话号码的字母组合
给定一个仅包含数字 2-9 的字符串,返回所有它能表示的字母组合. 给出数字到字母的映射如下(与电话按键相同).注意 1 不对应任何字母. 示例: 输入:"23" 输出:[&quo ...
- C# 类 (1)
通常每个类都会单独定义在自己的文件里,方便区分 Class 里面定义了 变量 属性 方法 实例化这个Class,得到一个对象,然后可以使用这个对象的变量 属性和方法 属性 Properties 像是一 ...
- HDU 4866 Shooting(主席树)题解
题意:在一个射击游戏里面,游戏者可以选择地面上[1,X]的一个点射击,并且可以在这个点垂直向上射击最近的K个目标,每个目标有一个价值,价值等于它到地面的距离.游戏中有N个目标,每个目标从L覆盖到R,距 ...
- how to check website offline status in js
how to check website offline status in js https://developer.mozilla.org/en-US/docs/Web/API/Navigator ...
- iPad pro & 显示器
iPad pro 显示器 iPad Pro 如何当做外接屏幕使用 XDisplay https://www.splashtop.com/wiredxdisplay https://play.googl ...