线程专题 -- 线程池,ThreadPoolExecutor
什么是线程池? 为什么要使用它?
线程池是为了避免线程频繁的创建和销毁带来的性能消耗,而建立的一种池化技术,它是把已创建的线程放入“池”中,当有任务来临时就可以重用已有的线程,无需等待创建的过程,这样就可以有效提高程序的响应速度。
线程池的好处:
(1)通过重用线程池中的线程,避免线程频繁的创建和销毁带来的性能消耗,提高程序的响应速度。
(2)便于对线程进行维护和管理,比如定时开始,周期执行,并发数控制等等。
ThreadPoolExecutor
要说线程池的话一定离不开 ThreadPoolExecutor ,在阿里巴巴的《Java开发手册》中是这样规定线程池的:线程池不允许使用Executors去创建,而是通过ThreadPoolExecutor的方式,这样的处理方式让写的读者更加明确线程池的运行规则,规避资源耗尽的风险。
为什么线程池不允许使用Executors去创建?(Executors 返回的线程池对象的弊端?)
1)FixedThreadPool 和 SingleThreadPool:允许的请求队列长度为 Integer.MAX_VALUE,可能会堆积大量的请求,从而导致 OOM。
2)CachedThreadPool 和 ScheduledThreadPool:允许的创建线程数量为 Integer.MAX_VALUE,可能会创建大量的线程,从而导致 OOM。
其实当我们去看Executors的源码会发现,Executors.newFixedThreadPool()、Executors.newSingleThreadExecutor()和 Executors.newCachedThreadPool() 等方法的底层都是通过 ThreadPoolExecutor 实现的。
ThreadPoolExecutor 的参数含义?
ThreadPoolExecutor 的核心参数指的是它在构建时需要传递的参数,其构造方法源码如下:
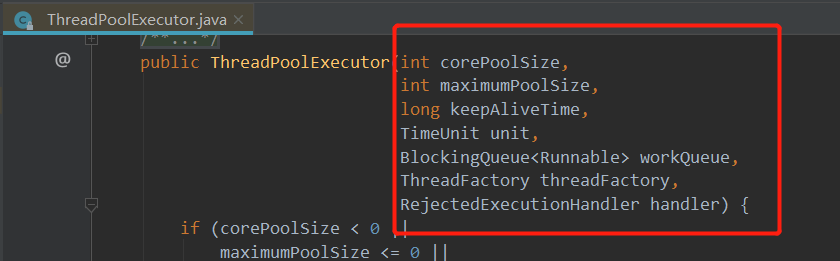
参数介绍
(1)参数corePoolSize,表示线程池的常驻核心线程数。如果设置为0,则表示在没有任何任务时,销毁线程池;如果大于0,即使没有任务时也会保证线程池的线程数量等于此值。但需要注意,此值如果设置的比较小,则会频繁的创建和销毁线程;如果设置的比较大,则会浪费系统资源,所以开发者需要根据自己的实际业务来调整此值。
(2)参数maximumPoolSize,表示线程池在任务最多时,最大可以创建的线程数。官方规定此值必须大于0,也必须大于等于corePoolSize,此值只有在任务比较多,且不能存放在任务队列时,才会用到。
(3)参数keepAliveTime,表示线程的存活时间,当线程池空闲时并且超过了此时间,多余的线程就会销毁,直到线程池中的线程数量销毁的等于corePoolSize为止,如果 maximumPoolSize 等于 corePoolSize,那么线程池在空闲的时候也不会销毁任何线程。
(4)参数unit ,表示存活时间的单位,它是配合 keepAliveTime 参数共同使用的。
(5)参数workQueue ,表示线程池执行的任务队列,当线程池的所有线程都在处理任务时,如果来了新任务就会缓存到此任务队列中排队等待执行。
(6)参数threadFactory ,表示创建新线程时使用的工厂,此参数一般用的比较少,我们通常在创建线程池时不指定此参数,它会使用默认的线程创建工厂的方法来创建线程,源代码如下:
(7)参数RejectedExecutionHandler,表示指定线程池的拒绝策略,当线程池的任务已经在缓存队列workQueue中存储满了之后,并且不能创建新的线程来执行此任务时,就会到此拒绝策略,它属于一种限流保护的机制。
线程工厂源码如下:
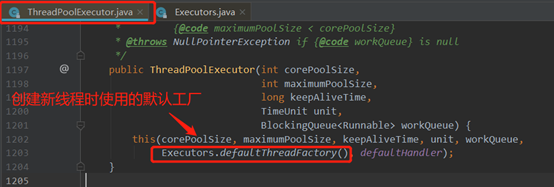
Ctrl点进去Executors.defaultThreadFactory()后

Ctrl点进去new DefaultThreadFactory()
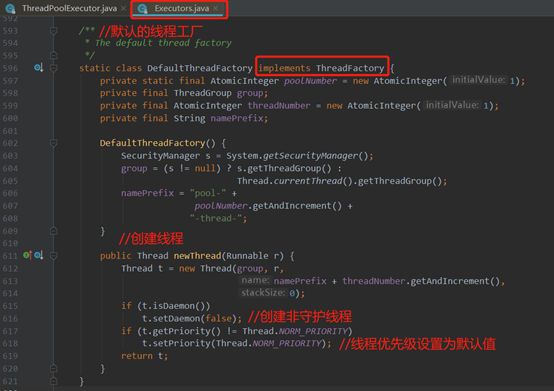
补充说明: 我们也可以自定义一个线程工厂,通过实现 ThreadFactory 接口来完成,这样就可以自定义线程的名称或线程执行的优先级了。
线程池的工作流程?
线程池的工作流程要从它的执行方法 execute() 说起,源码如下:
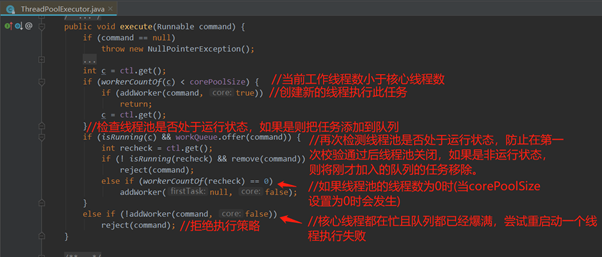
其中 addWorker(Runnable firstTask, boolean core) 方法的参数说明如下:
(1) firstTask,线程应首先运行的任务,如果没有则可以设置为 null。
(2) core,判断是否可以创建线程的阀值(最大值),如果等于 true 则表示使用 corePoolSize 作为阀值,false 则表示使用 maximumPoolSize 作为阀值。
线程池任务执行的主要流程如下:
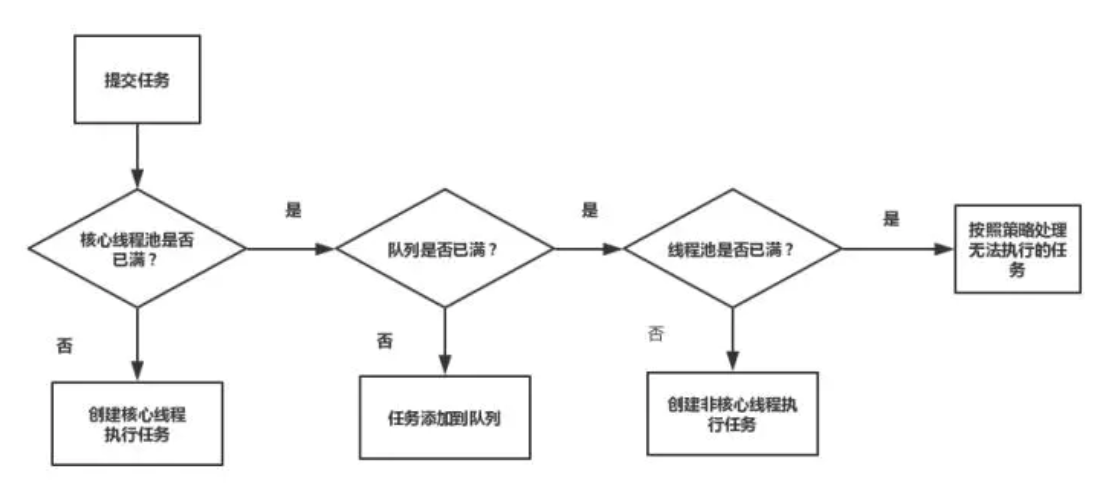
(1) 提交一个任务,线程池里存活的核心线程数小于线程数corePoolSize时,线程池会创建一个核心线程去处理提交的任务。
(2) 如果线程池核心线程数已满,即线程数已经等于corePoolSize,一个新提交的任务,会被放进任务队列workQueue排队等待执行。
(3) 当线程池里面存活的线程数已经等于corePoolSize了,并且任务队列workQueue也满,判断线程数是否达到maximumPoolSize,即最大线程数是否已满,如果没到达,创建一个非核心线程执行提交的任务。
(4) 如果当前的线程数达到了maximumPoolSize,还有新的任务过来的话,直接采用拒绝策略处理。
submit() 和 execute()方法有什么区别?(ThreadPoolExecutor 的执行方法有几种?)
execute() 和 submit() 都是用来执行线程池任务的,它们最主要的区别是,submit() 方法可以接收线程池执行的返回值,而 execute() 不能接收返回值。
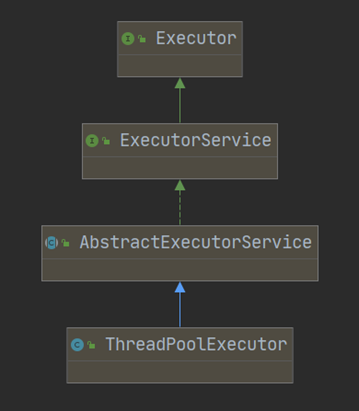
submit()方法可以配合Futrue来接收线程执行的返回值。它们的另一个区别是execute()方法属于Executor接口的方法,而 submit() 方法则是属于 ExecutorService 接口的方法,它们的继承关系如下图所示:
什么是线程的拒绝策略?
当线程池中的任务队列已经被存满,再有任务添加时会先判断当前线程池中的线程数是否大于等于线程池的最大值,如果是,则会触发线程池的拒绝策略。
Java自带的拒绝策略有4种:
(1) AbortPolicy,终止策略,线程池会抛出异常并终止执行,它是默认的拒绝策略;
(2) CallerRunsPolicy,把任务交给当前线程来执行;
(3) DiscardPolicy,忽略此任务(最新的任务);
(4) DiscardOldestPolicy,忽略最早的任务(最先加入队列的任务)。
拒绝策略AbortPolicy示例
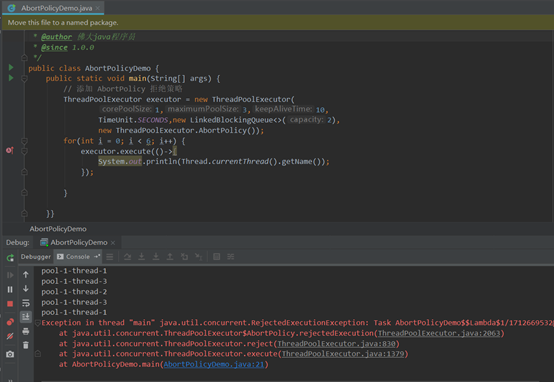
可以看出当第6个任务来的时候,线程池则执行了AbortPolicy拒绝策略,抛出了异常。因为队列最多存储2个任务,最大可以创建3个线程来执行任务(2+3=5),所以当第 6 个任务来的时候,此线程池就“忙”不过来了。
常见面试题
(1) 什么是线程池? 为什么要使用它?
(2) ThreadPoolExecutor的执行方法有几种?它们有什么区别?
(3) 什么是线程的拒绝策略?
(4) 拒绝策略的分类有哪些?
(5) 如何自定义拒绝策略?
(6) ThreadPoolExecutor 能不能实现扩展?如何实现扩展?
参考/好文:
拉钩教育 -- 详解 ThreadPoolExecutor 的参数含义及源码执行流程?
-- https://kaiwu.lagou.com/course/courseInfo.htm?courseId=59#/detail/pc?id=1764
线程、多线程与线程池总结
-- https://www.jianshu.com/p/b8197dd2934c
Java线程池解析
-- https://juejin.im/post/5d1882b1f265da1ba84aa676#heading-7
线程专题 -- 线程池,ThreadPoolExecutor的更多相关文章
- Android中的线程池 ThreadPoolExecutor
线程池的优点: 重用线程池中的线程,避免因为线程的创建和销毁带来的性能消耗 能有效的控制线程的最大并发数,避免大量的线程之间因抢占系统资源而导致的阻塞现象 能够对线程进行简单的管理,并提供定时执行以及 ...
- 硬核干货:4W字从源码上分析JUC线程池ThreadPoolExecutor的实现原理
前提 很早之前就打算看一次JUC线程池ThreadPoolExecutor的源码实现,由于近段时间比较忙,一直没有时间整理出源码分析的文章.之前在分析扩展线程池实现可回调的Future时候曾经提到并发 ...
- java 线程池ThreadPoolExecutor 如何与 AsyncTask() 组合使用。
转载请声明出处谢谢!http://www.cnblogs.com/linguanh/ 这里主要使用Executors中的4种静态创建线程池实例方法中的 newFixedThreadPool()来举例讲 ...
- java线程池ThreadPoolExecutor使用简介
一.简介线程池类为 java.util.concurrent.ThreadPoolExecutor,常用构造方法为:ThreadPoolExecutor(int corePoolSize, int m ...
- java线程池ThreadPoolExecutor理解
Java通过Executors提供四种线程池,分别为:newCachedThreadPool创建一个可缓存线程池,如果线程池长度超过处理需要,可灵活回收空闲线程,若无可回收,则新建线程.newFixe ...
- 线程池ThreadPoolExecutor、Executors参数详解与源代码分析
欢迎探讨,如有错误敬请指正 如需转载,请注明出处 http://www.cnblogs.com/nullzx/ 1. ThreadPoolExecutor数据成员 Private final Atom ...
- 线程池ThreadPoolExecutor
线程池类为 java.util.concurrent.ThreadPoolExecutor,常用构造方法为: ThreadPoolExecutor(int corePoolSize, int maxi ...
- 关于线程池ThreadPoolExecutor使用总结
本文引用自: http://blog.chinaunix.net/uid-20577907-id-3519578.html 一.简介 线程池类为 java.util.concurrent.Thread ...
- [转] 引用 Java自带的线程池ThreadPoolExecutor详细介绍说明和实例应用
PS: Spring ThreadPoolTaskExecutor vs Java Executorservice cachedthreadpool 引用 [轰隆隆] 的 Java自带的线程池Thre ...
随机推荐
- pandas 标签映射成数值的几种方法
1. preprocessing.LabelEncoder() import pandas as pd from sklearn import preprocessing le = preproces ...
- Jmeter(7)参数化csv data set config
接口测试同一变量或同一组变量不同值时,可通过csv data set config配置数据 1.创建文本文件,写入参数值,一个或一组值为一行,保存为.csv文件 2.创建测试计划,配置元件添加csv ...
- K8S安装Kubesphere
准备工作 安装Helm curl -L https://git.io/get_helm.sh | bash 创建账户 cat > heml-rbac.yaml << EOF apiV ...
- Docker(四):Docker安装Redis
查找Redis镜像 镜像仓库 https://hub.docker.com/ 下拉镜像 docker pull redis 查看镜像 docker images 创建Redis容器 运行Redis镜像 ...
- springmvc使用路径变量后再进行页面跳转会出现路径错误问题
学习<Servlet.JSP和SpringMVC学习指南>遇到的一个问题,记录下. 项目代码 现象 @RequestMapping(value = "/book_edit/{id ...
- [水题日常]Luogu1462 通往奥格瑞玛的道路
QwQ马上高二啦不能颓啦-知乎上听说写博客的效果挺好的,来试一下好啦~ 题目链接<< 题目描述 在艾泽拉斯,有n个城市.编号为1,2,3,...,n. 城市之间有m条双向的公路,连接着两个 ...
- [水题日常]UVA11181 条件概率(Probability|Given)
话说好久没写blog了 好好学概率论的第一天,这题一开始完全不会写,列出个条件概率的公式就傻了,后来看着lrj老师的书附带的代码学着写的- 因为我比较弱智 一些比较简单的东西也顺便写具体点或者是按照书 ...
- 第八章 SMS--短信服务
今天咱们接着 上一篇 第七章 Rocketmq–消息驱动 继续写 SpringCloud Alibaba全家桶 -> 第八章 SMS–短信服务,废话不多说,开干 8.1 短信服务介绍 短信服务( ...
- Thymeleaf是个什么东东?
Thymeleaf是面向Web和独立环境的现代服务器端Java模板引擎,能够处理HTML,XML,JavaScript,CSS甚至纯文本. Thymeleaf的主要目标是提供一个优雅和高度可维护的创建 ...
- 真香!Python十大常用文件操作,轻松办公
日常对于批量处理文件的需求非常多,用Python写脚本可以非常方便地实现,但在这过程中难免会和文件打交道,第一次做会有很多文件的操作无从下手,只能找度娘. 本篇文章整理了10个Python中最常用到的 ...