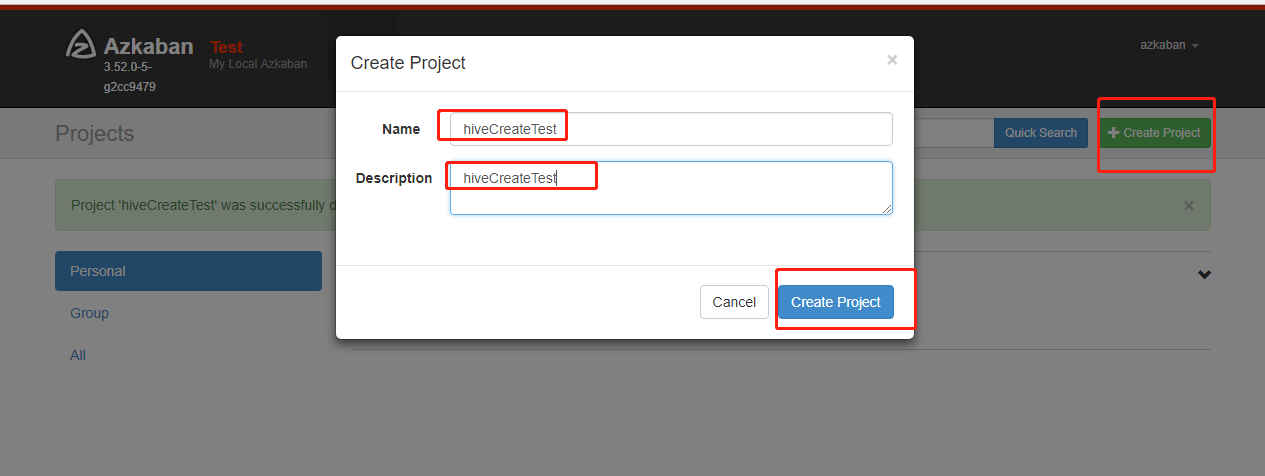
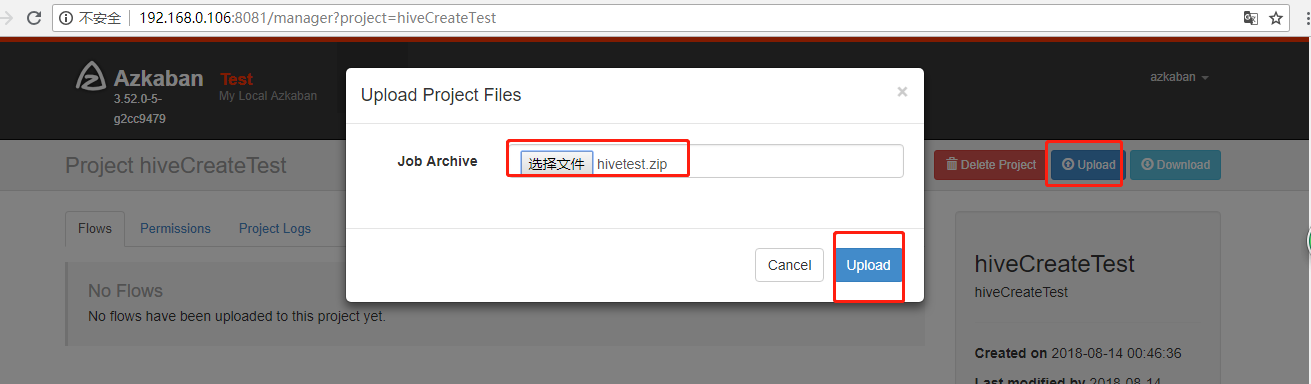
azkaban 执行hive语句
#hivef.job
type=command
command=hive -f test.sql
#test.sql
use default;
drop table aztest;
create table aztest(id int,name string) row format delimited fields terminated by ",";
load data inpath '/home/lxl/b.txt' into table aztest;
create table azres as select * from aztest;

.png)


.png)

.png)
.png)

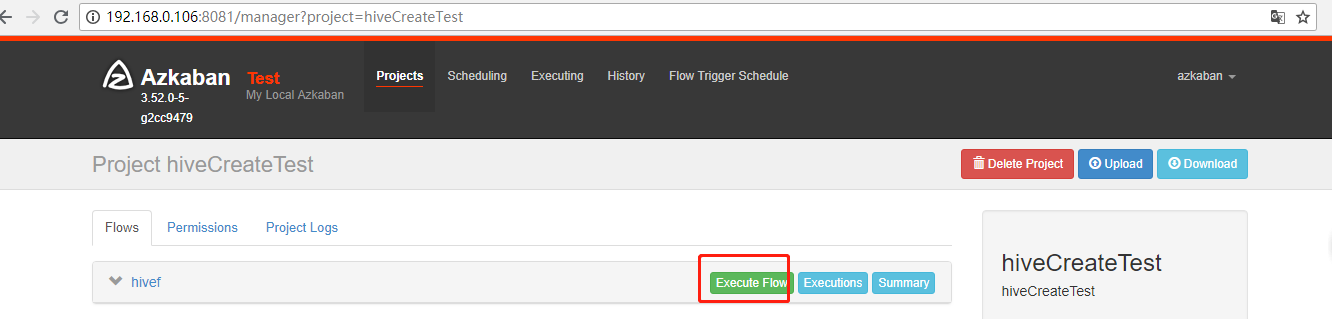

11.执行后显示如下:



.png)
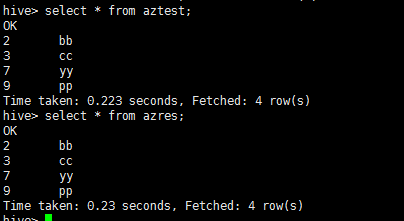
.png)
#hivef.job
type=command
command=sudo -u hdfs hive -f test.sql
#test.sql
use default;
drop table aztest;
create table aztest(id int,name string) row format delimited fields terminated by ",";
load data inpath '/home/lxl/b.txt' into table aztest;
create table azres as select * from aztest;
azkaban 执行hive语句的更多相关文章
- 使用java连接hive,并执行hive语句详解
安装hadoop 和 hive我就不多说了,网上太多文章 自己看去 首先,在机器上打开hiveservice hive --service hiveserver -p 50000 & 打开50 ...
- 使用Hive或Impala执行SQL语句,对存储在HBase中的数据操作
CSSDesk body { background-color: #2574b0; } /*! zybuluo */ article,aside,details,figcaption,figure,f ...
- 使用Hive或Impala执行SQL语句,对存储在Elasticsearch中的数据操作(二)
CSSDesk body { background-color: #2574b0; } /*! zybuluo */ article,aside,details,figcaption,figure,f ...
- 使用Hive或Impala执行SQL语句,对存储在Elasticsearch中的数据操作
http://www.cnblogs.com/wgp13x/p/4934521.html 内容一样,样式好的版本. 使用Hive或Impala执行SQL语句,对存储在Elasticsearch中的数据 ...
- hive高阶1--sql和hive语句执行顺序、explain查看执行计划、group by生成MR
hive语句执行顺序 msyql语句执行顺序 代码写的顺序: select ... from... where.... group by... having... order by.. 或者 from ...
- Hadoop生态圈-Azkaban实现hive脚本执行
Hadoop生态圈-Azkaban实现hive脚本执行 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 本篇博客中在HDFS分布式系统取的数据,而这个数据的是有之前我通过MapRed ...
- shell中执行hive命令错误:delimited by end-of-file (wanted `EOF')
错误信息: warning: here-document at line 58 delimited by end-of-file (wanted `EOF') 业务场景,使用hive对数据进行批量清洗 ...
- 通过学生-课程关系表,熟悉hive语句
通过学生-课程关系表,熟悉hive语句 1.在hive中创建以下三个表. create table student(Sno int,Sname string,Sex string,Sage int, ...
- 工作中常见的hive语句总结
hive的启动: 1.启动hadoop2.开启 metastore 在开启 hiveserver2服务nohup hive --service metastore >> log.out 2 ...
随机推荐
- 跨源资源共享(CORS)概念、实现(用Spring)、起源介绍
本文内容引用自: https://howtodoinjava.com/spring5/webmvc/spring-mvc-cors-configuration/ https://developer.m ...
- <a>链接添加样式问题
<a>链接是内联元素,必须设置成块元素block,才能有 width 和 height,不过你可以又定义display:block再定义成 display:inline 这样可以避免在IE ...
- 学习笔记TF044:TF.Contrib组件、统计分布、Layer、性能分析器tfprof
TF.Contrib,开源社区贡献,新功能,内外部测试,根据反馈意见改进性能,改善API友好度,API稳定后,移到TensorFlow核心模块.生产代码,以最新官方教程和API指南参考. 统计分布.T ...
- 【SpringBoot】SpringBoot2.0响应式编程
========================15.高级篇幅之SpringBoot2.0响应式编程 ================================ 1.SprinBoot2.x响应 ...
- Centos6.8通过yum安装mysql5.7 centos7.5适用
1.安装mysql的yum源 a.下载配置mysql的yum源的rpm包 根据上面3张图片中的操作下载下来的rpm文件可以通过如下命令获取: wget https://dev.mysql.com/ge ...
- 廖雪峰Java7处理日期和时间-3java.time的API-2ZonedDateTime
ZonedDatetime = LocalDateTime + ZoneId ZonedDateTime:带时区的日期和时间 ZoneId:新的API定义的时区对象(取代几句的java.util.Ti ...
- Failed to resolve: common Open File 导入项目问题
Failed to resolve: common Open File Warning:Configuration 'compile' is obsolete and has been replac ...
- note 3 变量与简单I/O
变量(Variable) 用于引用(绑定对象的标识符) 语法 变量名=对象(数值.表达式等) 增量赋值运算符 count = count + 1 简写 count += 1 标识符(Identifie ...
- 导出Excel实现 (ASP.NET C# 代码部分)
背景: 实现导出Excel功能. 技术: ASP.NET , 采用`Aspose.Cells`第三方组件, C# 实现通用部分. 根据前台Ext Grid完成导入Excel中文列与实际存储列的对应关 ...
- jdbc链接数据库的url两种写法
首先看下面两个jdbc的url 一:jdbc.url=jdbc:oracle:thin:@100.2.194.200:1521/abc二:jdbc.url=jdbc:oracle:thin:@100. ...