HBase的完全分布式搭建
一、HBase的安装模式
①单机安装:不依赖于Hadoop的HDFS,配置完即可使用,好处是便于测试,坏处是不具备分布式数据存储的能力。
②伪分布式安装:单台主机模拟真实环境。
③完全分布式安装:多台主机(虚拟机)来搭建
二、搭建准备
①搭建Hadoop+JDK+ZooKeeper(3个zookeeper集群模式,博主其他博文中已安装-------zookeeper集群的搭建(3台虚拟机))
②准备HBase的安装包
③准备三个节点:
192.168.144.130(Hadoop的伪分布式博主其他博文中已安装-------Hadoop之伪分布式安装,JDK+zookeeper+HBase)
192.168.144.132(JDK+zookeeper+HBase)
192.168.144.134(JDK+zookeeper+HBase)
三、搭建步骤
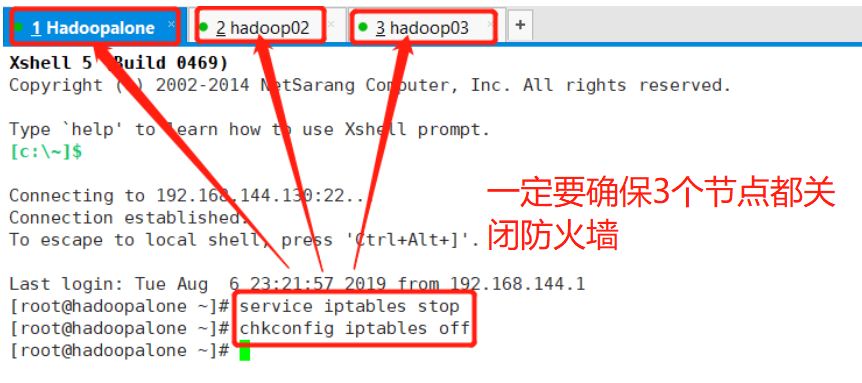
①关闭防火墙、修改主机名、hosts文件映射、免密登录(3个节点都要进行此操作)
关闭防火墙
service iptables stop 临时关闭
chkconfig iptables off 永久关闭
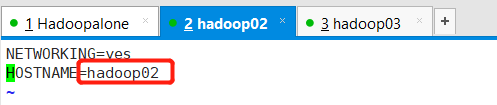
修改主机名
vim /etc/sysconfig/network
NETWORKING=yes
HOSTNAME=hadoopalone //这里表示主机名,依次配置3个节点的名字为hadoopalone,hadoop02,hadoop03
hosts文件映射
vim /etc/hosts
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
192.168.144.133 hadoopalone //配置对应的ip和主机名映射
192.168.144.131 hadoop02
192.168.144.132 hadoop03
免密登录
#ssh-keygen,一路回车即可。
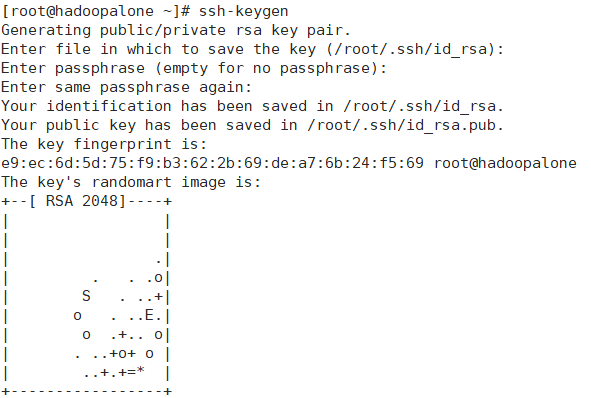
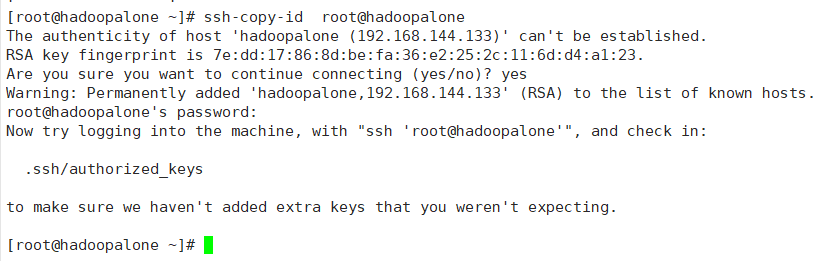
#ssh-copy-id root@hadoopalone(这里依次选择3个节点的主机名)
②获取并解压HBase的安装包
下载地址:http://hbase.apache.org/downloads.html
我这里以0.98.17为例:tar -xvf hbase-xxxxx
③修改配置文件---hbase-env.sh
vim conf/hbase-env.sh(修改完成以后切记:source hbase-env.sh)
#修改JAVA_HOME=XXXX
#修改zookeeper与hbase的协调模式:HBase默认使用自带zookeeper,如果需要使用外部的zookeeper,需要先关闭:export HBASE_MANAGES_ZK=false
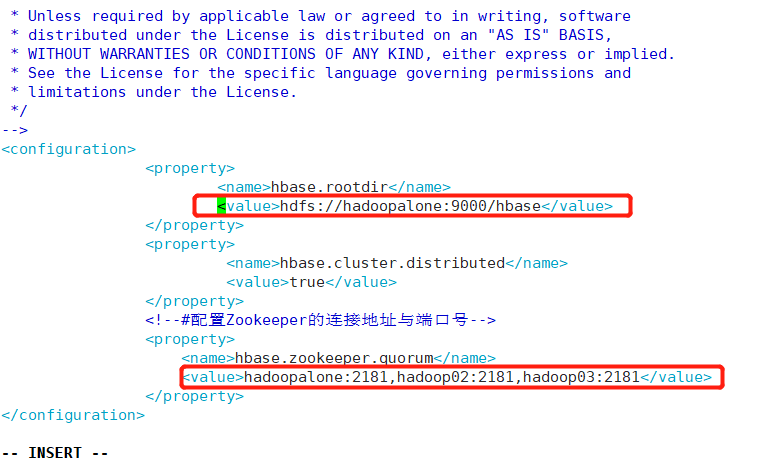
③修改配置文件---hbase-site.xml
配置开启完全分布式模式
<property>
<name>hbase.rootdir</name>
<value>hdfs://hadoopalone:9000/hbase</value>
</property>
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<!--#配置Zookeeper的连接地址与端口号-->
<property>
<name>hbase.zookeeper.quorum</name>
<value>hadoopalone:2181,hadoop02:2181,hadoop03:2181</value>
</property>
④配置region服务器
vim conf/regionservers
每个主机名独占一行
输入以下内容:
hadoopalone
hadoop02
hadoop03
⑤远程拷贝hbase安装包至另外两个节点
⑥依次启动zookeeper、Hadoop、Hbase
四、HBase集群的正式搭建
①关闭防火墙、修改主机名、hosts文件映射、免密登录(3个节点都要进行此操作)
关闭防火墙
修改主机名
vim /etc/sysconfig/network(修改完以后,切记记得重启)
第一个节点主机名为hadoopalone

第2个节点主机名为hadoop02
第3个节点主机名为hadoop03
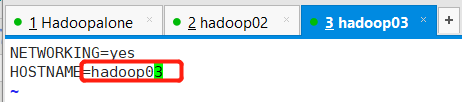
hosts文件ip映射
选择一个节点:vim /etc/hosts

免密登录
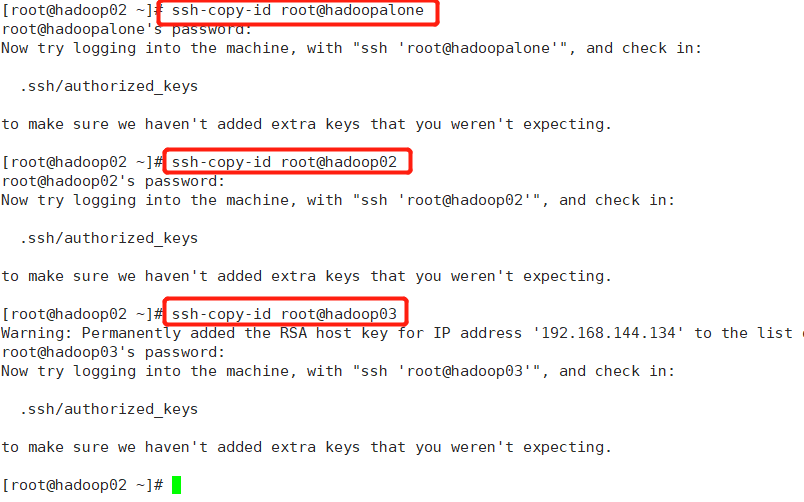
①ssh-keygen,然后一路回车即可。
②ssh-copy-id root@hadoopalone、ssh-copy-id root@hadoop02、ssh-copy-id root@hadoop03
每个节点依次执行以上命令:
②上传zookeeper、hbase安装包至3个节点,并解压
通过rz命令上传
解压:tar -xvf zookeeper.xxxxx tar -xvf hbase-......
每个节点都有hbase和zookeeper

③修改配置文件---hbase-env.sh
修改java_home

修改hbase和zookeeper的协调模式(修改完:source hbase-env.sh生效)

③修改配置文件---hbase-site.xml
④配置region服务器
vim regionservers

⑤远程拷贝hbase安装包至另外两个节点
确保jdk的安装路径是相同的

⑥依次启动zookeeper、Hadoop、Hbase
启动zookeeper
sh zkServer.sh start启动zookeeper,通过sh zkServer.sh status来查看状态
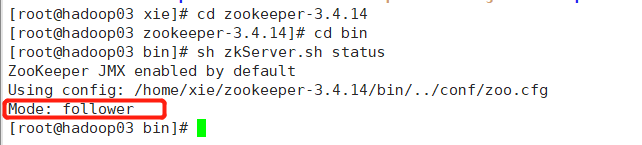
hadoopalone节点zookeeper为:follower
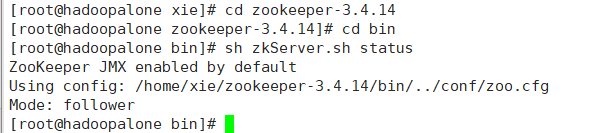
hadoop02节点zookeeper为:leader
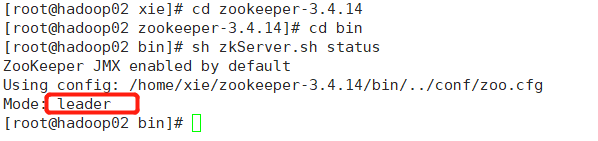
hadoop03节点zookeeper为:follower
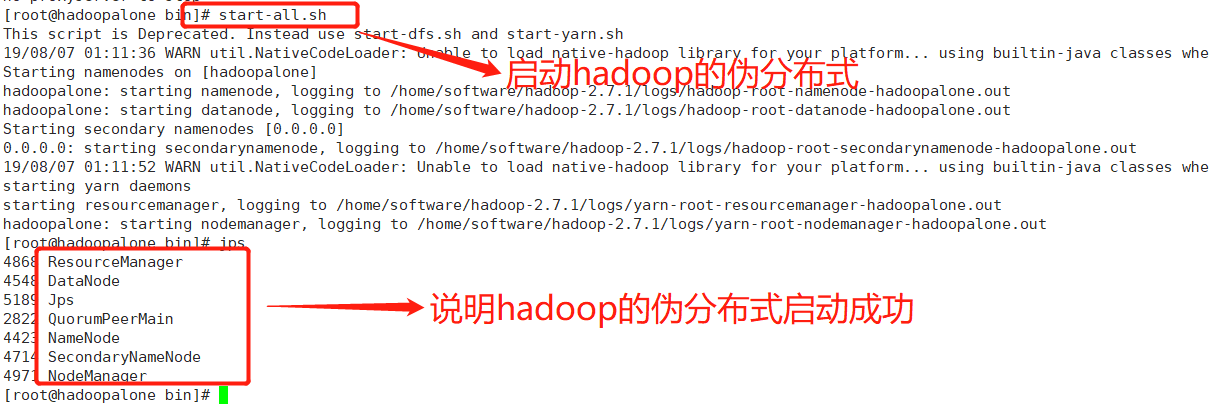
启动Hadoop的伪分布式
之前已经在hadoopalone搭建过hadoop的伪分布式,在hadoopalone节点:start-all.sh启动hadoop
通过jps来查看hadoop的伪分布式进程是否启动成功。
启动HBase
进入Hadoopalone节点的HBase的bin目录:sh start-hbase.sh启动服务端,通过jps来查看是否有HMaster进程。

在另外节点,通过jps来查看,出现以下进程,说明HBase的集群搭建完成。可以在该节点执行:sh start-hbase.sh,会成为HMaster的从。首先启动的HMaster会成为主。

至此HBase的集群已经搭建完成,如果有问题,我们评论讨论一下,谢谢。
HBase的完全分布式搭建的更多相关文章
- Hadoop生态圈-hbase介绍-完全分布式搭建
Hadoop生态圈-hbase介绍-完全分布式搭建 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任.
- hbase单机环境的搭建和完全分布式Hbase集群安装配置
HBase 是一个开源的非关系(NoSQL)的可伸缩性分布式数据库.它是面向列的,并适合于存储超大型松散数据.HBase适合于实时,随机对Big数据进行读写操作的业务环境. @hbase单机环境的搭建 ...
- Hbase的伪分布式安装
Hbase安装模式介绍 单机模式 1> Hbase不使用HDFS,仅使用本地文件系统 2> ZooKeeper与Hbase运行在同一个JVM中 分布式模式– 伪分布式模式1> 所有进 ...
- Hadoop+HBase+Spark+Hive环境搭建
杨赟快跑 简书作者 2018-09-24 10:24 打开App 摘要:大数据门槛较高,仅仅环境的搭建可能就要耗费我们大量的精力,本文总结了作者是如何搭建大数据环境的(单机版和集群版),希望能帮助学弟 ...
- HBase HA的分布式集群部署(适合3、5节点)
本博文的主要内容有: .HBase的分布模式(3.5节点)安装 .HBase的分布模式(3.5节点)的启动 .HBase HA的分布式集群的安装 .HBase HA的分布式集群的启动 .H ...
- Hadoop生态圈-hbase介绍-伪分布式安装
Hadoop生态圈-hbase介绍-伪分布式安装 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.HBase简介 HBase是一个分布式的,持久的,强一致性的存储系统,具有近似最 ...
- HBase集群的搭建
HBase集群的搭建(在<HBase伪分布式安装>基础上搭建) 1 集群结构,主节点(hmaster)是hadoop0,从节点(region server)是hadoop1和hadoop2 ...
- 大数据-HBase HA集群搭建
1.下载对应版本的Hbase,在我们搭建的集群环境中选用的是hbase-1.4.6 将下载完成的hbase压缩包放到对应的目录下,此处我们的目录为/opt/workspace/ 2.对已经有的压缩包进 ...
- Hbase0.98.0完全分布式搭建---【使用外部zookeeper】
Hbase是一个分布式的实时数据库,他可以基于hadoop的hdfs,S3等分布式存储系统.而且使用zookeeper来通信(查询元数据和获取数据所在位置等功能) 本文的Hbase使用的是hadoop ...
随机推荐
- 关于spring boot集成MQTT
安装 说到mqtt,首先肯定要安装了,安装什么的地址:http://activemq.apache.org/ap...我本地是Windows的环境,所以装的是Windows版本,这里是第一个注意的地方 ...
- 解决jmeter 24h长时间压测-o生成报告文件达到几个g以及以上的问题
问题描述:jmeter执行稳定性测试时,因时间过长,导致jtl文件过大,生成html报告过程报内存溢出错误(增加内存配置也不能解决) 使用 jmeter -n -t test.jmx -l ...
- POJ 1330(LCA/倍增法模板)
链接:http://poj.org/problem?id=1330 题意:q次询问求两个点u,v的LCA 思路:LCA模板题,首先找一下树的根,然后dfs预处理求LCA(u,v) AC代码: #inc ...
- 关于Win32串口
因为近段时间接触Hid相对来说多一些,由此忽略了串口中获取cbInQue这个重要的东西,下面是错误代码 // Win32SerialPortLib.cpp : 定义 DLL 应用程序的导出函数. // ...
- mysql之case..when ..then..else..end as..用法
1.示例1 查询1: SELECT CASE main_xm_sam31 WHEN '02' THEN 2 ELSE 1 END AS SPDJ FROM SR_MAIN_BG A WHERE A.P ...
- php核心技术与最佳实践--- oop
<?php /** * Created by PhpStorm. * User: cl * Date: 2019/8/12 * Time: 7:08 */ /*oop*/ class Perso ...
- B1027 打印沙漏
题目链接:https://pintia.cn/problem-sets/994805260223102976/problems/994805294251491328 1027 打印沙漏 (20 分) ...
- 20191225_Python构造函数知识以及相关注意事项
Python构造函数格式为__init__() 注:下划线为两个而不是一个 可以有无参构造 instance: class city: def printout(self,first,second): ...
- Jarvis OJ - Baby's Crack - Writeup
Jarvis OJ - Baby's Crack - Writeup M4x原创,欢迎转载,转载请表明出处 这是我第一次用爆破的方法做reverse,值得记录一下 题目: 文件下载 分析: 下载后解压 ...
- 关于JavaScript中0、空字符串、'0'是true还是false的总结
最近被问到关于js中空字符串是true还是false得问题,一时间没想起来,现在在chrome的console面板上输出代码测试一下. "" == false 结果是true ...