GAN总结
GAN总结
本篇文章主要是根据GitHub上的GAN代码库[PyTorch-GAN]进行GAN的复习和回顾,对于之前GAN的各种结构的一种简要的概括。
Code
关于评价GAN模型的标准
Inception score。对模型生成的图片做一个抽样,将图片输入一个分类器中(一般是google的inception model),对于每个类别,计算生成图像分布的KL散度的指数平均值,得到每个类别的Inception Score。公式如下:
\(IS = \exp\left(\mathbb{E}_{x \sim p_{\text{data}}(x)} [D_{KL}(p(y|x) || p(y))] \right)\)
其中,\(D_{KL}(p(y|x) || p(y))\)表示生成图像分布和真实图像分布之间的KL散度,\(p(y|x)\)表示给定图像\(x\)生成的类别分布,\(p(y)\)表示真实图像的类别分布。
Fréchet Inception Distance,FID和IS不同的是它需要和真实图像进行对比,而不仅仅是评价生成图像之前的差异。使用真实图像的均值向量和协方差矩阵,以及生成图像的均值向量和协方差矩阵之间的差异,计算FID。公式如下:
\(FID = ||\mu_{\text{real}} - \mu_{\text{gen}}||^2 + \text{Tr}(\Sigma_{\text{real}} + \Sigma_{\text{gen}} - 2(\Sigma_{\text{real}}\Sigma_{\text{gen}})^{1/2})\)
其中,\(\mu_{\text{real}}\)和\(\mu_{\text{gen}}\)分别表示真实图像和生成图像的均值向量,\(\Sigma_{\text{real}}\)和\(\Sigma_{\text{gen}}\)表示它们的协方差矩阵,\(\text{Tr}\)表示迹运算。
ACGAN
acgan的全称是auxiliary classifier gan,辅助分类器gan,是一种有监督的生成对抗网络,其主要思想是在生成器和判别器中加入分类器,使得生成器和判别器都能够学习到数据的类别信息,从而提高生成器和判别器的性能。相比于CGAN直接进行分类loss的反向传播,acgan在生成器和判别器中都加入了分类损失,除了GAN loss,还引入了分类器loss.
生成器(Generator):
\]
生成器接受输入的噪声向量 z 和类别标签 y,并生成伪造的图像 x̃。
判别器(Discriminator):
\]
判别器接受真实图像 x 和对应的类别标签 y,以及生成图像 x̃ 和对应的类别标签 y,并输出概率值表示真实图像或生成图像的可能性。
鉴别器损失函数(Discriminator Loss):
\]
鉴别器的目标是最小化真实图像的误分类概率和最大化生成图像的误分类概率。
生成器损失函数(Generator Loss):
\]
生成器的目标是最大化生成图像被判别为真实图像的概率。
分类器损失函数(Auxiliary Classifier Loss):
\]
ACGAN还具有一个分类器 C,它使用生成图像和真实图像的类别标签进行训练。分类器的目标是最小化生成图像和真实图像之间的类别预测误差。
总体损失函数:
\]
其中,λ 是用于平衡生成器和分类器损失的超参数。
ACGAN模型通过引入类别信息,能够生成具有特定类别属性的图像,并且通过分类器提供了更好的控制和可解释性。
Adversarial Autoencoders
AAE 实在VAE上的变种,回想VAE的架构。
VAE分为Encoder和Decoder,Encoder将输入的数据映射到潜在空间(将训练数据的分布映射为一个多维高斯分布 ),Decoder将潜在空间的向量映射到原始数据空间,VAE的目标是最小化重构误差和潜在空间的正则项,从而使得潜在空间的向量能够更好的表示原始数据。
VAE的损失函数主要来自两个方面:
- 重构损失,数据经过Encoder和Decoder的重构误差。
- KL散度,数据经过Encoder映射到潜在空间的向量分布与高斯分布的差异,这个loss强制潜空间的分布符合高斯分布。
AAE就针对第二点提出了一个新的想法,使用GAN来代替KL散度。它通过训练一个额外的判别器来强制潜在空间的向量分布符合高斯分布,判别器会分辨Encoder输出的latent Embedding是否符合特定分布。然后按照GAN的范式来交替更新Encoder、Decoder和判别器。
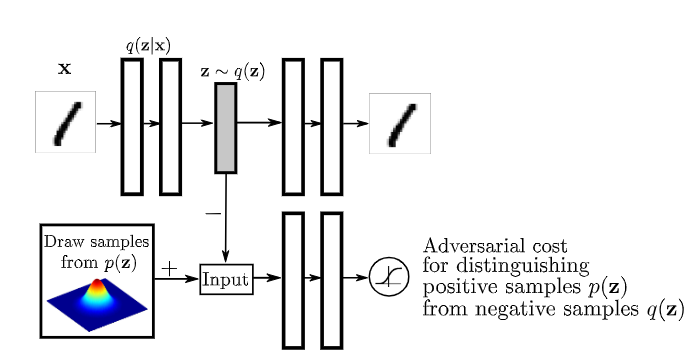
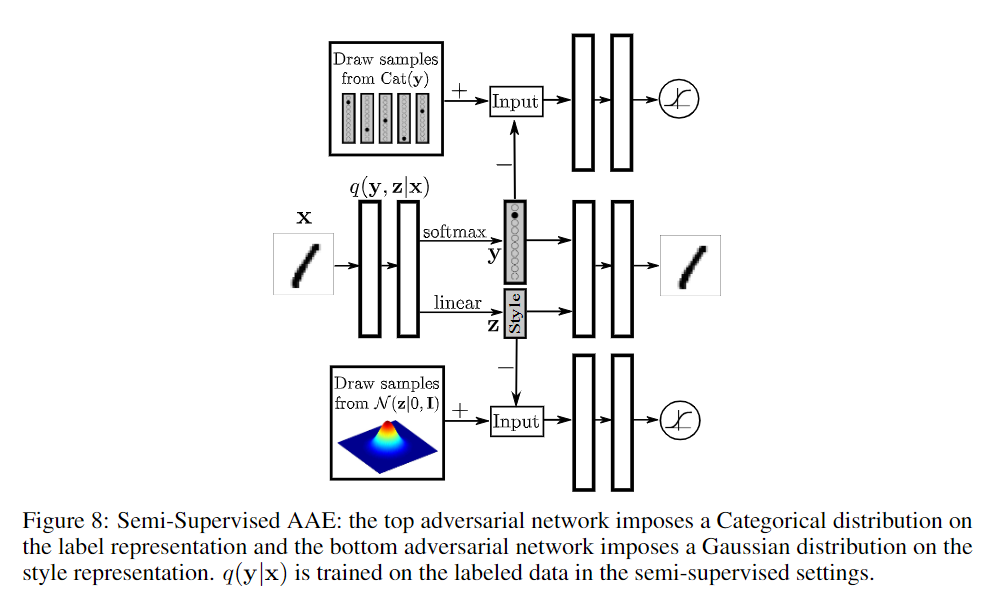
上述是用于重构的AAE,用于VAE的一些技术也可以用于AAE,例如添加分类信息、使用半监督学习、无监督学习等,下面给出半监督学习和无监督学习的架构,看图应该就可以理解了。
引入分类信息
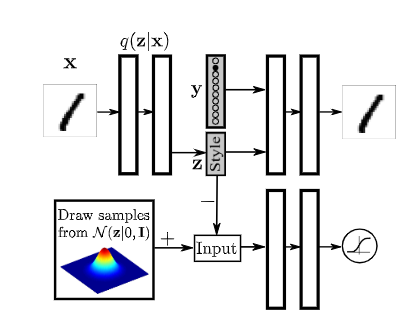
引入半监督
WGAN
WGAN(Wasserstein Generative Adversarial Networks)是一种生成对抗网络模型,其具有以下创新点:
使用Wasserstein距离代替传统的JS散度:WGAN引入了Wasserstein距离作为衡量真实分布与生成分布之间差异的指标。相比于传统的JS散度,Wasserstein距离具有更好的数值稳定性和连续性,能够提供更可靠的梯度信号,从而使训练过程更加稳定。
判别器的权重剪裁:为了满足Wasserstein距离的要求,WGAN通过对判别器的权重进行剪裁,将权重限制在一个预定义的范围内。这种权重剪裁机制有助于避免梯度消失或爆炸问题,并促使判别器学习到更加平滑且良好的输出。
去除了传统GAN中的sigmoid函数和log损失函数:WGAN不使用sigmoid函数作为判别器的最后一层激活函数,也不使用二元交叉熵损失函数。取而代之的是,判别器只需线性输出,同时使用Wasserstein距离作为损失函数。这种改变避免了训练过程中的梯度消失问题,提高了训练的稳定性。
基于梯度惩罚的正则化方法:为了满足Wasserstein距离的Lipschitz连续性要求,WGAN引入了梯度惩罚的正则化方法。该方法通过对判别器在真实图像和生成图像之间的采样点上计算的梯度进行惩罚,来推动判别器的参数满足Lipschitz条件。
这些创新点使得WGAN能够更好地解决传统GAN中存在的训练不稳定、模式崩溃等问题,并提供了一种理论上更可靠的损失函数及训练策略。WGAN的引入对生成对抗网络的发展具有重要意义。
他还有具有一些变种,例如WGAN-GP,WGAN-DIV,WGAN-LP等,这些变种都是在WGAN的基础上进行改进,例如WGAN-GP是在WGAN的基础上引入了梯度惩罚,WGAN-DIV是在WGAN的基础上引入了KL散度,WGAN-LP是在WGAN的基础上引入了Lp范数。
WGAN:对于每一个中间参数的梯度都进行剪裁,使得梯度的范数不超过一个固定的常数c,这样就可以保证判别器满足Lipschitz连续性。
WGAN-GP:在WGAN上修改了梯度惩罚的方式,相比于直接计算loss相对于图片的loss,这篇论文将生成的FakeImg和真实Img按照一定的比例混合,然后计算梯度惩罚。
WGAN-DIV:相比于裁剪梯度,这篇论文换成了梯度正则化,求loss相对于图片的梯度,并将它的L2范数添加进loss。
Improved Techniques for Training GANs
这篇文章主要是用来改进GAN训练的稳定性、多样性和图像质量的。
它提出了多种方法:
- Feature Matching:要求生成的图像在判别器的中间层的输出也要尽量一致,添加了一个额外的loss,使得生成的图像在判别器的中间层的输出也要尽量一致
\]
- minibatch discrimination:在判别器的中间层加入了minibatch discrimination,就是要求一份Batch内部产生的图像的差异性要尽量大,这样可以避免模式崩溃的问题。
- Historical Averaging:\(||\boldsymbol{\theta}-\frac1t\sum_{i=1}^t\boldsymbol{\theta}[i]||^2\),要求更新的参数需要记住之前的经验,而不是完全的更新,这个灵感是从博弈论中学习到的,博弈论中的一个重要的概念就是Nash Equilibrium,就是要求每一个人都要记住之前的经验,而不是完全的更新,这样才能够达到一个平衡的状态。
- One-sided label smoothing,就是将真实的标签设置为0.9或者更小,而不是1,这样可以避免让模型过于自信,这个时候loss也会该改变。
- Vitual batch normalization.这个小trick基本没啥用
- Inception Score。IS就是在这一片论文中提出的。
Pix2Pix:Image-to-Image Translation with Conditional Adversarial Networks
之前做图像翻译,类似于图像分割,语义分割之类的都是使用Unet,然后再翻译之后的图像做MSEloss,pix2pix则将GAN的方法用在了这种方向上。pix2pix将unet得到的图像和真实图像一起放入判别器中,,使用GAN的范式来对生成器Unet进行训练。
它的主要创新点就是下面的loss:
GAN loss如下
x是真实图像,y是真实图像的标签,z是噪声,G是生成器,D是判别器
\]
再加上L1 loss
\]
最终得到的loss
\]
在pix2pix中还采用了patchGAN的discriminator,它的创新点在于与其判定整张图片是是否是真实的,不如判定一张图片的一小块是不是真实的,这样可以使得判别器更加细致,更加关注图片的细节。
cycleGAN:Unpaired Image-to-Image Translation using Cycle-Consistent Adversarial Networks
GAN总结的更多相关文章
- (转) How to Train a GAN? Tips and tricks to make GANs work
How to Train a GAN? Tips and tricks to make GANs work 转自:https://github.com/soumith/ganhacks While r ...
- 不要怂,就是GAN (生成式对抗网络) (一)
前面我们用 TensorFlow 写了简单的 cifar10 分类的代码,得到还不错的结果,下面我们来研究一下生成式对抗网络 GAN,并且用 TensorFlow 代码实现. 自从 Ian Goodf ...
- GAN
GAN(Generative Adversarial Nets),产生式对抗网络 存在问题: 1.无法表示数据分布 2.速度 3.resolution太小,大了无语义信息 4.无reference 5 ...
- 不要怂,就是GAN (生成式对抗网络) (二)
前面我们了解了 GAN 的原理,下面我们就来用 TensorFlow 搭建 GAN(严格说来是 DCGAN,如无特别说明,本系列文章所说的 GAN 均指 DCGAN),如前面所说,GAN 分为有约束条 ...
- 不要怂,就是GAN (生成式对抗网络) (四):训练和测试 GAN
在 /home/your_name/TensorFlow/DCGAN/ 下新建文件 train.py,同时新建文件夹 logs 和文件夹 samples,前者用来保存训练过程中的日志和模型,后者用来保 ...
- 用GAN生成二维样本的小例子
同步自我的知乎专栏:https://zhuanlan.zhihu.com/p/27343585 本文完整代码地址:Generative Adversarial Networks (GANs) with ...
- 提高驾驶技术:用GAN去除(爱情)动作片中的马赛克和衣服
同步自我的知乎专栏:https://zhuanlan.zhihu.com/p/27199954 作为一名久经片场的老司机,早就想写一些探讨驾驶技术的文章.这篇就介绍利用生成式对抗网络(GAN)的两个基 ...
- 学习笔记GAN003:GAN、DCGAN、CGAN、InfoGAN
GAN应用集中在图像生成,NLP.Robt Learning也有拓展.类似于NLP中的Actor-Critic. https://arxiv.org/pdf/1610.01945.pdf . Gen ...
- 用MXNet实现mnist的生成对抗网络(GAN)
用MXNet实现mnist的生成对抗网络(GAN) 生成式对抗网络(Generative Adversarial Network,简称GAN)由一个生成网络与一个判别网络组成.生成网络从潜在空间(la ...
- 从一篇ICLR'2017被拒论文谈起:行走在GAN的Latent Space
同步自我的知乎专栏文章:https://zhuanlan.zhihu.com/p/32135185 从Slerp说起 ICLR'2017的投稿里,有一篇很有意思但被拒掉的投稿<Sampling ...
随机推荐
- Spring的三种依赖注入的方式
1.什么是依赖注入 依赖注入(Dependency Injection,简称DI),是IOC的一种别称,用来减少对象间的依赖关系. 提起依赖注入,就少不了IOC. IOC(Inversion of C ...
- java中的即时编译(JIT)简介
Java发展这么多年一直长青,很大一部分得益于开发人员长期对其坚持不懈的优化:写得更少,跑得更快!JIT就是其中一项十分重要的优化. JIT全程Java Intime Compiler,即Java即时 ...
- yb课堂 实战之路由拦截和订单模块 《四十二》
前置守护 路由拦截功能开发 文档:https://router.vuejs.org/zh/guide/advanced/navigation-guards.html router里面配置需要登陆的路由 ...
- yb课堂 实战之Mybatis打通Mysql数据库 《二》
配置mybatis连接Mysql数据库 server.port=8081 # ========================数据库相关配置===================== spring.d ...
- HTB- Archetype
端口扫描 nmap -sV -sT 10.129.1.1 smbclint smbclient -L 10.129.149.214 获取密码 smbclient //10.129.149.214/ba ...
- css浅谈Flex布局
1.打开Flex布局 .box{ display: flex; } 2.容器的属性 flex-direction flex-wrap flex-flow justify-content align-i ...
- 薅 AWS 羊毛的船新方式,以 ChatBot 为例
还在担心一年免费服务器到期后该怎么办?(Solo社区 投稿) 网上绝大多数薅 AWS 羊毛的教程都是在教大家如何申请创建一年免费的 VPS,太 OUT 了!就问一个问题,一年到期了那咋办? 其实,除了 ...
- 深度学习论文翻译解析(二十三):Segment Angthing
论文标题:Segment Angthing 论文作者: Alexander Kirillov Eric Mintun Nikhila Ravi Hanzi Mao... 论文地址:2304.02 ...
- .NET开源、简单、实用的数据库文档生成工具
前言 今天大姚给大家分享一款.NET开源(MIT License).免费.简单.实用的数据库文档(字典)生成工具,该工具支持CHM.Word.Excel.PDF.Html.XML.Markdown等多 ...
- oeasy教您玩转vim - 14 - # 行头行尾
行头行尾 回忆上节课内容 我们这次了解了 大词 和 小词 小词 就是我们常规意义的词 被 =." 等标点分开的词 大词 里面包括了 =." 等标点 只能被空格.tab.换行分割 W ...