【mysql】索引 回表 覆盖索引 索引下推
索引类型
索引类型分为主键索引和非主键索引。(一定要牢记,是怎么存储数据的)
- 主键索引的叶子节点存的是整行数据。在 InnoDB 里,主键索引也被称为聚簇索引(clustered index)。
- 非主键索引的叶子节点内容是主键的值。在 InnoDB 里,非主键索引也被称为二级索引(secondary index)。
聚簇索引
聚簇索引默认是主键,如果表中没有定义主键,InnoDB 会选择一个唯一的非空索引代替。如果没有这样的索引,InnoDB 会隐式定义一个主键来作为聚簇索引。
因为B+TREE的原因,最好使用连续的整数字段,更好确定查找访问范围
回表
根据上面的索引结构说明,主键索引和普通索引的查询区别
- 如果语句是 select * from T where ID=500,即主键查询方式,则只需要搜索 ID 这棵 B+ 树;
- 如果语句是 select * from T where k=5,即普通索引查询方式,则需要先搜索 k 索引树,得到 ID 的值为 500,再到 ID 索引树搜索一次。这个过程称为回表。
覆盖索引
如果执行的语句是 select ID from T where k between 3 and 5,这时只需要查 ID 的值,而 ID 的值已经在 k 索引树上了,因此可以直接提供查询结果,不需要回表。也就是说,在这个查询里面,索引 k 已经“覆盖了”我们的查询需求,我们称为覆盖索引。
索引下推
索引下推是MySQL5.6版本推出的优化手段
默认是开启的,可以通过下面命令关闭
SET optimizer_switch = 'index_condition_pushdown=off';
假如有一下SQL,不通的执行过程,如下图表示
index(name,age)
mysql> select * from tuser where name like '张%' and age=10 and ismale=1;
可以看到,无索引下推是,每次都需要回表查询,而下推的是在先过滤好结果集,回表拿select * 的数据
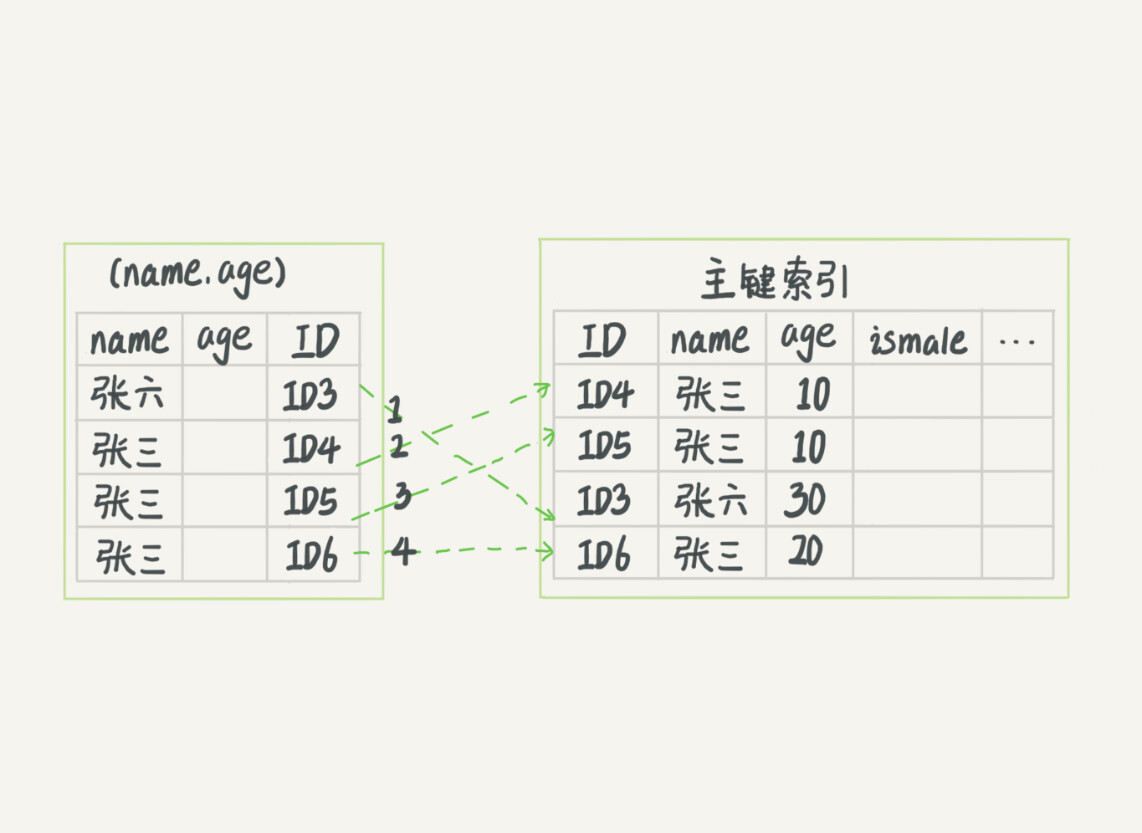
无索引下推
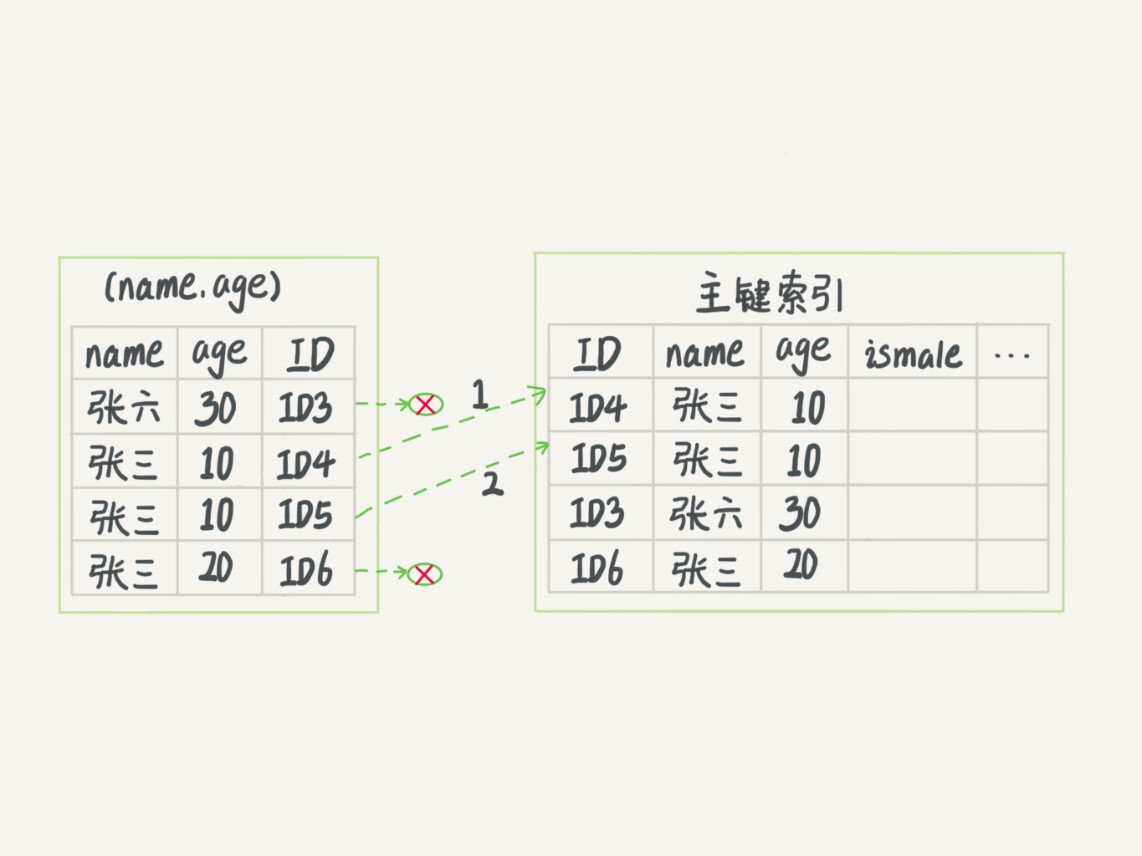
有索引下推
【mysql】索引 回表 覆盖索引 索引下推的更多相关文章
- mysql中的回表查询与索引覆盖
了解一下MySQL中的回表查询与索引覆盖. 回表查询 要说回表查询,先要从InnoDB的索引实现说起.InnoDB有两大类索引,一类是聚集索引(Clustered Index),一类是普通索引(Sec ...
- MySQL数据库回表与索引
目录 回表的概念 1.stu_info表案例 2.查看刚刚建立的表结构 3.插入测试数据 4.分析过程 5.执行计划 回表的概念 先得出结论,根据下面的实验.如果我要获得['liu','25']这条记 ...
- MySQL查看 InnoDB表中每个索引的高度
我们都知道MySQL里,索引通常用B+树来实现的.B+树的叶子结点才具体保存数据(聚簇索引保存的是行数据:普通索引是主键,如有需要得回表),非叶子结点都是用来索引叶子结点的.假设索引高度为h,那么每次 ...
- oracle TABLE ACCESS BY INDEX ROWID 你不知道的索引回表-开发系列(三)
1 引言 近期系统常常提示一个sql查询时间过长的问题,看了一下就是一个每天依照时间戳统计前一天量的sql. 表总的数据量为53483065. 语句例如以下: select count(x.seria ...
- mysql 闪回表工具
use HTTP::Date qw(time2iso str2time time2iso time2isoz); use POSIX; my $SDATE = strftime("%Y-%m ...
- MySQL优化:如何避免回表查询?什么是索引覆盖? (转)
数据库表结构: create table user ( id int primary key, name varchar(20), sex varchar(5), index(name) )engin ...
- mysql:如何利用覆盖索引避免回表优化查询
说到覆盖索引之前,先要了解它的数据结构:B+树. 先建个表演示(为了简单,id按顺序建): id name 1 aa 3 kl 5 op 8 aa 10 kk 11 kl 14 jk 16 ml 17 ...
- mysql覆盖索引与回表
mysql覆盖索引与回表 Harri2012关注 62019.07.28 11:14:15字数 1,292阅读 77,322 select id,name where name='shenjian' ...
- (MYSQL)回表查询原理,利用联合索引实现索引覆盖
一.什么是回表查询? 这先要从InnoDB的索引实现说起,InnoDB有两大类索引: 聚集索引(clustered index) 普通索引(secondary index) InnoDB聚集索引和普通 ...
随机推荐
- Python 第一天学习记录
- .NET Core 3.x之下的配置框架
一.配置框架的核心类库 首先我们使用.NET Core的配置框架需要安装额外的NuGet扩展包,下面是列举最常用的几个扩展包以及所对应的配置功能 NuGet Package Description M ...
- weex 和 appcan 的个人理解
appcan是浏览器技术,前端代码运行在webview上,而weex是原生引擎渲染,说白了就是把H5翻译成原生. weex的官网上说,在开发weex页面就像开发普通网页一样,在渲染weex页面时和原生 ...
- JavaScript对象(三)
序列化对象: 对象序列化:对象的状态转化为字符串,也可以将字符串还原为对象.方法:JSON.stringify(),用来序列化,JSON.parse(),用来还原对象. JSON(JavaScript ...
- Nginx之负载均衡配置(一)
前文我们聊了下nginx作为反向代理服务器,代理后端动态应用服务器的配置,回顾请参考https://www.cnblogs.com/qiuhom-1874/p/12430543.html:今天我们来聊 ...
- 本地Hadoop集群搭建
什么是Hadoop? Hadoop是一个开源的Apache项目,通常用来进行大数据处理. Hadoop集群的架构: master节点维护分布式文件系统的所有信息,并负责调度资源分配,在Hadoop集群 ...
- Protocol buffers编写风格指南
原文链接:https://developers.google.com/protocol-buffers/docs/style Style Guide 本文说明了.proto文件的编写风格指南.遵循这些 ...
- 使用StreamHttpResponse和FileResponse下载文件的注意事项及文件私有化
为什么需要编写下载视图方法? 你或许知道,我们上传的文件默认放在media文件夹中的,且Django会为每个上传的静态文件分配一个静态url.在模板中,你可以使用{{ mymodel.file.url ...
- burpsuit之Spider、Scanner、Intruder模块
1.spider模块 1.spider模块介绍 被动爬网:(被动爬网获得的链接是手动爬网的时候返回页面的信息中分析发现超链接) 对于爬网的时候遇到HTML表单如何操作: 需要表单身份认证时如何操作(默 ...
- drf认证组件(介绍)、权限组件(介绍)、jwt认证、签发、jwt框架使用
目录 一.注册接口 urls.py views.py serializers.py 二.登录接口 三.用户中心接口(权限校验) urls.py views.py serializers.py 四.图书 ...