Python爬虫初探 - selenium+beautifulsoup4+chromedriver爬取需要登录的网页信息
目标
之前的自动答复机器人需要从一个内部网页上获取的消息用于回复一些问题,但是没有对应的查询api,于是想到了用脚本模拟浏览器访问网站爬取内容返回给用户。详细介绍了第一次探索python爬虫的坑。
准备工作
requests模块向网站发送http请求,BeautifulSoup模块来从静态HTML文本中提取我们想要的数据,更高级的,对于动态加载页面我们需要用webdriver去模拟真实的网页访问,并解析内容。
推荐使用Anaconda 这个科学计算版本,主要是因为它自带一个包管理工具,可以解决有些包安装错误的问题。
- 安装requests(anaconda自带),selenium,beautifulsoup4,方法为
pip install selenium
conda install beautifulsoup4
conda install lxml
使用Python3.5 的童鞋们直接使用pip install beautifulsoup4安装会报错(所以才推荐使用Anaconda版本),安装教程看这里。
你可能需要安装lxml,这是一个解析器,BeautifulSoup可以使用它来解析HTML,然后提取内容。
如果不安装lxml,则BeautifulSoup会使用Python内置的解析器对文档进行解析。之所以使用lxml,是因为它速度快。
参考Python爬虫小白入门(三)BeautifulSoup库
https://www.cnblogs.com/Albert-Lee/p/6232745.html
关于webdriver的搭配网上一些旧帖子都说的是selenium+PhantomJS,但是目前selenium已经不再支持PhantomJS(如果使用了会报错syntax error,坑了很久才知道这个消息),只能使用chrome或者firefox的对应驱动,这里我们使用chromedriver,你也可以使用firefoxdriver。接下来说说chromedriver的安装
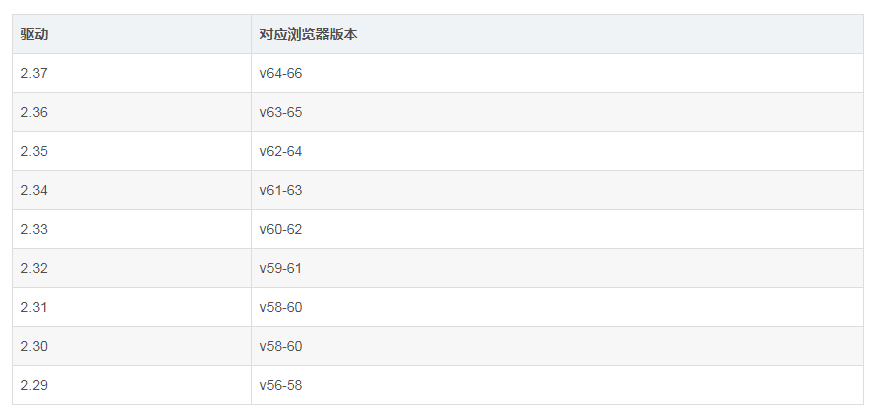
- 从http://chromedriver.storage.googleapis.com/index.html网址中下载与本机chrome浏览器对应的chromedriver驱动程序,chrome版本可以打开浏览器右上角
驱动版本对应参考如下,转自chromedriver与chrome各版本及下载地址
- 将下载的chromedriver解压到chrome安装目录(右键chrome快捷方式查看属性),再将chrome安装目录添加到电脑的Path环境变量中,并手动cmd刷新下path信息,相关操作百度一搜一大堆
开始工作
程序根据用户输入,在一个引导页匹配查找对应的产品网址后缀,添加到url链接的请求参数部分的?product=后面,后续将访问新的网址
import的模块
首先介绍下import的模块
import requests#发起静态url请求
from bs4 import BeautifulSoup#BeautifulSoup解析
import re#正则匹配
from selenium import webdriver#下面是webdriver所需
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.common.desired_capabilities import DesiredCapabilities
import time#动态加载页面需要延时再获取信息
匹配搜索
定义了一个匹配搜索的函数,如果用户输入的字符(’a‘)被包含在搜索列表([’bat‘,’link‘,’you‘])中某项之中(比如‘a’被’bat‘包含),则返回包含的项(‘bat'),搜不到就返回’None‘,使用re正则加快匹配
def branchFinder(userInput, collection):
regex = re.compile(userInput) # Compiles a regex.
for item in collection:
match = regex.search(item) # Checks if the current item matches the regex.
if match:
return item
return 'None'
如果使用模糊搜索参考http://www.mamicode.com/info-detail-1601799.html
获取并解析静态页面
使用requests.get访问静态页面,使用BeautifulSoup处理页面
url1 = 'https://www.xxxx.com/?&product='
r = requests.get(url1, cookies = cookies, headers = headers)
# with open('main.html', 'wb+') as f:
# f.write(r.content)
soup = BeautifulSoup(r.content, 'lxml') #声明BeautifulSoup对象
findResult = soup.find_all('option') #在页面查找所有的option标签
optionList = []#option所有选项的value参数列表
for i in range(1,len(findResult)):#第一个option是默认selected的选项,为空,所以这里没有添加进列表
optionList.append(findResult[i]['value'])
# print(optionList)
#已获取主界面的value列表
#根据关键字查找对应的branch选项,生成新的访问链接
branch = branchFinder(userInput,optionList)
if (branch == 'None'):
return 'Not Found. Please check your input.' #为了实现return,实际上这些代码整个写在一个函数里
print(branch+'\n')
url2 = url1 + branchFinder(userInput,optionList)#新的访问链接
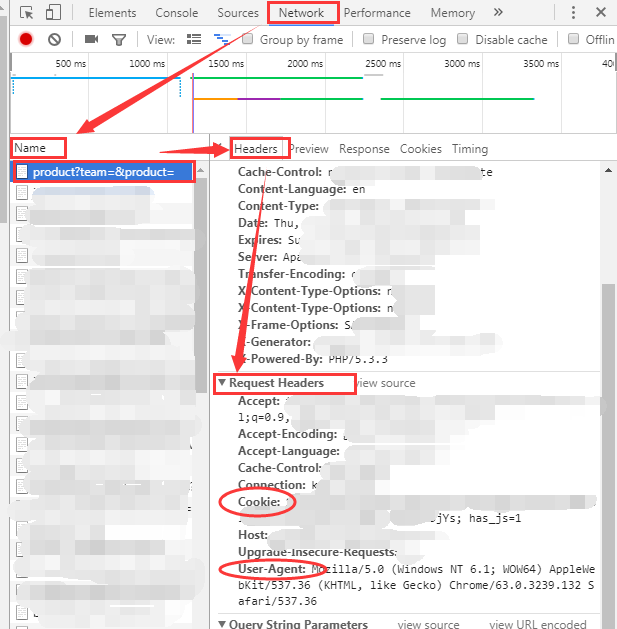
其中headers是你访问页面的浏览器信息,cookies包含了登录信息,用于在网页需要登录的情况下搞定访问权限,示例如下
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36'}
cookies = {'cookie': 'has_js=1; xxxxx=yyyyy'}
查看以上信息的方式为浏览器访问url1的链接,登录后F12打开调试器,按照下图寻找Name的第一个参数,找到椭圆圈出来的cookies和headers,填入上面的示例
关于BeautifulSoup对于网页信息的获取和处理函数参考Python爬虫小白入门(三)BeautifulSoup库,至此我们已经完成了静态爬取网页信息的尝试,当我尝试如法炮制访问url2的时候,使用BeautifulSoup一直获取不到我想要的表格中的数据,查找<table>标签后,里面只有<thead>没有<tbody>,查看requests获取的网页信息才发现根本没有tbody,在浏览器中访问url2,打开F12,发现表格使用的是datatable,因为之前做过使用datatable的项目,所以觉得这里可能是动态加载的tbody中的数据,静态访问是获取不到表格数据的,这就需要动态加载了。
动态加载处理页面
经历了selenium+PhantomJS的失败尝试后,我转而使用selenium+headless chrome,这也是在运行PhantomJS相关代码后编译器提示才知道的。
关于driver对于页面的处理操作非常方便,不仅可以查找,还可以模拟click等功能,详见WebDriver--定位元素的8种方式和【Selenium2+Python】常用操作和webdriver(python)学习笔记一等等
dcap = dict(DesiredCapabilities.PHANTOMJS) #设置useragent,实际上只是使用了phantomjs的参数,各位可以ctrl+鼠标点进去定义查看具体参数
dcap['phantomjs.page.settings.userAgent'] = (headers['User-Agent']) #根据需要设置具体的浏览器信息 chrome_options = Options()
chrome_options.add_argument('--no-sandbox')#解决DevToolsActivePort文件不存在的报错
chrome_options.add_argument('window-size=1920x3000') #指定浏览器分辨率
chrome_options.add_argument('--disable-gpu') #谷歌文档提到需要加上这个属性来规避bug,否则会提示gpu开启失败
chrome_options.add_argument('--hide-scrollbars') #隐藏滚动条, 应对一些特殊页面
chrome_options.add_argument('blink-settings=imagesEnabled=false') #不加载图片, 提升速度
chrome_options.add_argument('--headless') #浏览器不提供可视化页面. linux下如果系统不支持可视化不加这条会启动失败,windows如果不加这条会
启动浏览器GUI,并且不会返回句柄,只会等待操作,后面的代码不会执行了
chrome_options.binary_location = r"C:/Program Files (x86)/Google/Chrome/Application/chrome.exe" #手动指定使用的浏览器位置 # driver=webdriver.Chrome(chrome_options=chrome_options)
# driver.get('https://www.baidu.com')
# print('hao123' in driver.page_source)
driver = webdriver.Chrome(chrome_options=chrome_options,desired_capabilities=dcap)#封装浏览器信息
# driver = webdriver.Chrome(desired_capabilities=dcap)
driver.get(url2)# 访问链接
# 添加cookies,注意和之前的格式不一样,之前cookies的格式是xxxxx=yyyyy,这里name对应的是=之前的xxxxx,value对应的是yyyyy
driver.add_cookie({'name' : 'xxxxx', 'value' : 'yyyyy'})
driver.refresh()#重新加载以登录
driver.implicitly_wait(1)#等待1s加载数据,需要根据感觉调整时长,如果1s不够就要增加时间,详情参考后面的for循环等待加载数据
time.sleep(0.1)
#显示Product summary界面
print('Product summary.\n')
#点击最新的Build链接
driver.find_element_by_tag_name("tbody").find_element_by_tag_name("a").click()#可以顺蔓摸瓜查找一个标签下的其他标签,不论是一个标签还是标签集
#已进入Build Viewer界面
print('Build Viewer.\n')
#点击Tests
driver.find_element_by_id('').click()#根据id查找并点击
print(driver.find_element_by_class_name('table-responsive').text)#打印应该是空的,因为还没获取到数据
result = ''
for i in range(20):#循环加载20s,获取表格数据,由于find也需要时间,实际上加载不止20s
driver.implicitly_wait(1)#等待加载数据
result = driver.find_element_by_class_name('table-responsive').text
if(result == ''):#循环加载数据,直到非空
print( 'Waiting '+ str(i+1) + 's...')
else:
break driver.quit()#退出浏览器
- 最开始我driver.implicitly_wait(1)加载的时间很短,但是也能获取到页面内容,因为我是设置的断点调试的!所以等待加载的时间比我设置的长多了!退出debug模式直接run的时候,有时候设置为5s仍然获取不到数据,发现这个坑的时候简直惊呼!不过还好我们可以使用循环等待来判断什么时候加载数据完毕。
- 之前没有设置headless,使用cmd尝试可以打开chrome浏览器GUI,但是使用vscode打不开GUI,才知道需要管理员权限,于是使用管理员方式打开vscode即可
输出结果
aiodnwebg DevTools listening on ws://127.0.0.1:12133/devtools/browser/xxxx
Product summary. Build Viewer. Waiting 1s...
Waiting 2s...
Waiting 3s...
ID Job
123 aaa
245 bbb
完整代码
import requests
from bs4 import BeautifulSoup
import re
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.common.desired_capabilities import DesiredCapabilities
import time ###################User Input##########################
userInput = '=====your input======' headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36'} cookies = {'cookie': 'has_js=1; xxxxx=yyyyy'}
###################User Input########################## def branchFinder(userInput, collection):
regex = re.compile(userInput) # Compiles a regex.
for item in collection:
match = regex.search(item) # Checks if the current item matches the regex.
if match:
return item
return 'None' def getResult(userInput):
url1 = 'https://www.xxx.com/?&product=' r = requests.get(url1, cookies = cookies, headers = headers)
# with open('main.html', 'wb+') as f:
# f.write(r.content) soup = BeautifulSoup(r.content, 'lxml') #声明BeautifulSoup对象
findResult = soup.find_all('option') #查找option标签
optionList = []
for i in range(1,len(findResult)):
optionList.append(findResult[i]['value'])
# print(optionList)
#已获取主界面的value列表 #根据关键字查找对应的branch,生成新的访问链接
branch = branchFinder(userInput,optionList)
if (branch == 'None'):
return 'Not Found. Please check your input.'
print(branch+'\n')
url2 = url1 + branchFinder(userInput,optionList)
dcap = dict(DesiredCapabilities.PHANTOMJS) #设置useragent
dcap['phantomjs.page.settings.userAgent'] = (headers['User-Agent']) #根据需要设置具体的浏览器信息 chrome_options = Options()
chrome_options.add_argument('--no-sandbox')#解决DevToolsActivePort文件不存在的报错
chrome_options.add_argument('window-size=1920x3000') #指定浏览器分辨率
chrome_options.add_argument('--disable-gpu') #谷歌文档提到需要加上这个属性来规避bug
chrome_options.add_argument('--hide-scrollbars') #隐藏滚动条, 应对一些特殊页面
chrome_options.add_argument('blink-settings=imagesEnabled=false') #不加载图片, 提升速度
chrome_options.add_argument('--headless') #浏览器不提供可视化页面. linux下如果系统不支持可视化不加这条会启动失败
chrome_options.binary_location = r"C:/Program Files (x86)/Google/Chrome/Application/chrome.exe" #手动指定使用的浏览器位置 # driver=webdriver.Chrome(chrome_options=chrome_options)
# driver.get('https://www.baidu.com')
# print('hao123' in driver.page_source)
driver = webdriver.Chrome(chrome_options=chrome_options,desired_capabilities=dcap)#封装浏览器信息
# driver = webdriver.Chrome(desired_capabilities=dcap)
driver.get(url2) driver.add_cookie({'name' : 'xxxxx', 'value' : 'yyyyy'})
driver.refresh()#重新加载以登录
driver.implicitly_wait(1)#等待加载数据
time.sleep(0.1)
#显示Product summary界面
print('Product summary.\n')
#点击最新的Build链接
driver.find_element_by_tag_name("tbody").find_element_by_tag_name("a").click()
#已进入Build Viewer界面
print('Build Viewer.\n')
#点击Tests
driver.find_element_by_id('').click()
print(driver.find_element_by_class_name('table-responsive').text)
result = ''
for i in range(20):
driver.implicitly_wait(1)#等待加载数据
result = driver.find_element_by_class_name('table-responsive').text
if(result == ''):
print( 'Waiting '+ str(i+1) + 's...')
else:
break
driver.quit()
return result finalResult = getResult(userInput)
print(finalResult)
后记
一个下午做完这些,才知道有个东西叫Scrapy,= =之后试一试

Python爬虫初探 - selenium+beautifulsoup4+chromedriver爬取需要登录的网页信息的更多相关文章
- Python爬虫——使用 lxml 解析器爬取汽车之家二手车信息
本次爬虫的目标是汽车之家的二手车销售信息,范围是全国,不过很可惜,汽车之家只显示100页信息,每页48条,也就是说最多只能够爬取4800条信息. 由于这次爬虫的主要目的是使用lxml解析器,所以在信息 ...
- Python爬虫系列-Selenium+Chrome/PhantomJS爬取淘宝美食
1.搜索关键字 利用Selenium驱动浏览器搜索关键字,得到查询后的商品列表 2.分析页码并翻页 得到商品页码数,模拟翻页,得到后续页面的商品列表 3.分析提取商品内容 利用PyQuery分析源码, ...
- 一起学爬虫——使用selenium和pyquery爬取京东商品列表
layout: article title: 一起学爬虫--使用selenium和pyquery爬取京东商品列表 mathjax: true --- 今天一起学起使用selenium和pyquery爬 ...
- [Python爬虫] 使用 Beautiful Soup 4 快速爬取所需的网页信息
[Python爬虫] 使用 Beautiful Soup 4 快速爬取所需的网页信息 2018-07-21 23:53:02 larger5 阅读数 4123更多 分类专栏: 网络爬虫 版权声明: ...
- Python爬虫学习三------requests+BeautifulSoup爬取简单网页
第一次第一次用MarkDown来写博客,先试试效果吧! 昨天2018俄罗斯世界杯拉开了大幕,作为一个伪球迷,当然也得为世界杯做出一点贡献啦. 于是今天就编写了一个爬虫程序将腾讯新闻下世界杯专题的相关新 ...
- 爬虫学习(二)--爬取360应用市场app信息
欢迎加入python学习交流群 667279387 爬虫学习 爬虫学习(一)-爬取电影天堂下载链接 爬虫学习(二)–爬取360应用市场app信息 代码环境:windows10, python 3.5 ...
- Python爬虫开源项目代码,爬取微信、淘宝、豆瓣、知乎、新浪微博、QQ、去哪网等 代码整理
作者:SFLYQ 今天为大家整理了32个Python爬虫项目.整理的原因是,爬虫入门简单快速,也非常适合新入门的小伙伴培养信心.所有链接指向GitHub,祝大家玩的愉快 1.WechatSogou [ ...
- 23个Python爬虫开源项目代码:爬取微信、淘宝、豆瓣、知乎、微博等
来源:全球人工智能 作者:SFLYQ 今天为大家整理了23个Python爬虫项目.整理的原因是,爬虫入门简单快速,也非常适合新入门的小伙伴培养信心.所有链接指向GitHub,祝大家玩的愉快 1.Wec ...
- 【python爬虫】一个简单的爬取百家号文章的小爬虫
需求 用"老龄智能"在百度百家号中搜索文章,爬取文章内容和相关信息. 观察网页 红色框框的地方可以选择资讯来源,我这里选择的是百家号,因为百家号聚合了来自多个平台的新闻报道.首先看 ...
随机推荐
- 在Windows 10中更改网络连接优先级
查看接口列表 (也可使用 如下) 选择网络连接,然后单击右侧的箭头以更改网络连接优先级. 可以参考之前的部分 链接在此 更改单个wi-fi连接顺序可以使用如下
- 我的QT5学习之路(三)——模板库、工具类和控件(下)
一.前言 作为第三篇的最后一部分,我们来看一下Qt的控件,谈到控件,就会让人想到界面的美观性和易操作性,进而想到开发的便捷性.作为windows界面开发的MFC曾经是盛行了多少年,但是其弊端也随着其他 ...
- 苹果编程语言Swift简介
Swift是什么? Swift是苹果于WWDC 2014发布的编程语言,The Swift Programming Language的原话: Swift is a new programming la ...
- page_address()函数分析--如何通过page取得虚拟地址
由于X86平台上面,内存是划分为低端内存和高端内存的,所以在两个区域内的page查找对应的虚拟地址是不一样的. 一. x86上关于page_address()函数的定义 在include/linux/ ...
- SpringMVC找不到对应的页面
确认springmvc配置文件视图解析器配置正确. <!-- 视图解析器 --> <bean class="org.springframework.web.servlet. ...
- Python 学习笔记(十四)Python类(一)
基本概念 问题空间:问题空间是问题解决者对一个问题所达到的全部认识状态,它是由问题解决者利用问题所包含的信息和已贮存的信息主动的地构成的. 初始状态:一开始时的不完全的信息或令人不满意的状况: 目标状 ...
- 小程序发微信红包后端Nodejs实现
前提条件 1.有一个微信开放平台 https://open.weixin.qq.com/ 2.有一个微信公众平台 https://mp.weixin.qq.com 并且开通微信支付 3.有一个微信小 ...
- 解决Windows下编辑脚本上传到Linux后遇到^M的方法
Windows下编辑脚本上传到Linux后遇到^M,导致脚本无法执行,原因是因为Linux与Windows对 "回车键" 编码不同 解决方法如下: 在使用UE->文件-> ...
- Linq 和 SQL的左连接、右连接、内链接
在我们工作中表连接是很常用的,但常用的有这三种连接方式:左连接.右连接.内链接 在本章节中讲的是1.如何在Linq中使用左连接,右连接,内连接. 2.三种连接之间的特点在哪? 3.Linq的三种连接语 ...
- Python 基础 模块
python 中模块和保定 概念 如果将代码分才投入多个py 文件,好处: 同一个变量名也互不影响. python 模块导入 要使用一个模块,我们必须先导入该模块.python 使用import ...