[Python爬虫] 使用 Beautiful Soup 4 快速爬取所需的网页信息
一、前言
之前使用原生的 Python 库去爬取网页信息,经常要使用正则表达式,笔者记性不是很好,经常经常忘记相关符号及其作用。
后来使用著名的 Scrapy 框架去爬取信息,感觉太笨重了,特别是一个项目开发到一半,要引入爬虫功能,再使用 Scrapy,就不是那么友好了,其本身就是一个 Web Project。
近来使用一个和之前 Java 爬虫特别简单好使的 Jsoup 框架极其类似的 Beautiful Soup
引入也很简单:
# Python 2+
pip install beautifulsoup4
# Python 3+
pip3 install beautifulsoup4- 1
- 2
- 3
- 4
- 5
使用 Python 爬虫体验当然是比 Java 要好,java开发有点 “做作” —— 每一步都极其格式化(面向对象),Python 则运用自如。
二、需求
现在要爬取 CSDN首页 的今日推荐的 文章 标题 及其 链接,
2.1.这是网页目标内容
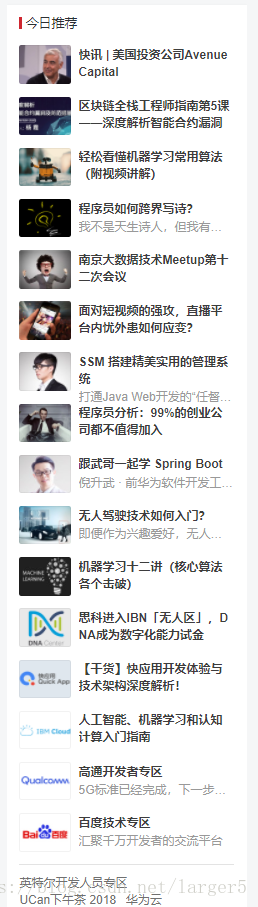
2.2.这是网页目标内容对应的源码

三、实践
你猜需要多少行代码,没错,就这几行,就是这么牛逼。
因力求精简,笔者为此费了几个小时通读官方 API 文档数遍。
3.1.代码
from bs4 import BeautifulSoup
from urllib.request import urlopen
html = urlopen("https://www.csdn.net/").read().decode('utf-8')
soup = BeautifulSoup(html,"html.parser")
titles=soup.select("h3[class='company_name'] a") # CSS 选择器
for title in titles:
print(title.get_text(),title.get('href'))# 标签体、标签属性- 1
- 2
- 3
- 4
- 5
- 6
- 7
3.2.效果

四、小结
参考文献:
Beautiful Soup 中文文档
[Python爬虫] 使用 Beautiful Soup 4 快速爬取所需的网页信息的更多相关文章
- python爬虫之Beautiful Soup基础知识+实例
python爬虫之Beautiful Soup基础知识 Beautiful Soup是一个可以从HTML或XML文件中提取数据的python库.它能通过你喜欢的转换器实现惯用的文档导航,查找,修改文档 ...
- Python爬虫之Beautiful Soup解析库的使用(五)
Python爬虫之Beautiful Soup解析库的使用 Beautiful Soup-介绍 Python第三方库,用于从HTML或XML中提取数据官方:http://www.crummv.com/ ...
- python 爬虫利器 Beautiful Soup
python 爬虫利器 Beautiful Soup Beautiful Soup 是一个可以从HTML或XML文件中提取数据的Python库.它能够通过你喜欢的转换器实现惯用的文档导航,查找,修改文 ...
- Python爬虫教程-13-爬虫使用cookie爬取登录后的页面(人人网)(下)
Python爬虫教程-13-爬虫使用cookie爬取登录后的页面(下) 自动使用cookie的方法,告别手动拷贝cookie http模块包含一些关于cookie的模块,通过他们我们可以自动的使用co ...
- Python爬虫库-Beautiful Soup的使用
Beautiful Soup 是一个可以从HTML或XML文件中提取数据的Python库,简单来说,它能将HTML的标签文件解析成树形结构,然后方便地获取到指定标签的对应属性. 如在上一篇文章通过爬虫 ...
- python爬虫之Beautiful Soup的基本使用
1.简介 简单来说,Beautiful Soup是python的一个库,最主要的功能是从网页抓取数据.官方解释如下: Beautiful Soup提供一些简单的.python式的函数用来处理导航.搜索 ...
- python标准库Beautiful Soup与MongoDb爬喜马拉雅电台的总结
Beautiful Soup标准库是一个可以从HTML/XML文件中提取数据的Python库,它能够通过你喜欢的转换器实现惯用的文档导航,查找,修改文档的方式,Beautiful Soup将会节省数小 ...
- python 爬虫5 Beautiful Soup的用法
1.创建 Beautiful Soup 对象 from bs4 import BeautifulSoup html = """ <html><head& ...
- Python爬虫实战(2):爬取京东商品列表
1,引言 在上一篇<Python爬虫实战:爬取Drupal论坛帖子列表>,爬取了一个用Drupal做的论坛,是静态页面,抓取比较容易,即使直接解析html源文件都可以抓取到需要的内容.相反 ...
随机推荐
- java中 什么是反射?
JAVA反射机制是在运行状态中,对于任意一个实体类,都能够知道这个类的所有属性和方法: 对于任意一个对象,都能够调用它的任意方法和属性:这种动态获取信息以及动态调用对象方法的功能称为java语言的反射 ...
- 浅谈JSONP 的本质工作原理
json 是一种数据格式jsonp 是一种数据调用的方式. 你可以简单的理解为 带callback的json就是jsonp 话说我们访问一个页面的时候 需要像另一个网站获取部分信息, 这就是所谓的跨域 ...
- linux 安装nginx -查看 linux的环境变量
我发现在linux上面安装linux很简单 在CentOS release 6.5 上面先看一下操作系统的版本: lsb_release -a 直接执行 yum install nginx 系统自动的 ...
- redis安装与介绍
安装 一般推荐次新版的最后一个发行版.https://redis.io/download 先安装gcc, yum install gcc tar xzf redis-3.2.3.tar.gz cd r ...
- github又提交不了代码了..... X_X
如下: 我们使用git提交代码过程中,突然就登录不上了 原因是 用户名被更改了:git@gitlab.0easy.com 是你的用户名 造成的原因是: 我们clone代码过程中选择了SSH的地址 解决 ...
- 安卓P2P开源项目
https://github.com/LinYaoTian/P2PChat 一个基于局域网的 Android P2P 聊天系统 https://github.com/ddssingsong/webrt ...
- Tomcat日志监控工具——Probe
今天遇到项目运行过程中需要查看用户访问日志,log4j.properties配置好,将log日志输出到tomcat的log文件夹下,但不可能每次都去服务器上拉取log文件查看,网上找了下,发现一个日志 ...
- 有关Linux
关于nginx https://www.cnblogs.com/jingmoxukong/p/5945200.html 停止命令 sudo systemctl stop nginx.service
- Day7作业:选课系统
这周的作业有点糙,迁就看吧,给大家点思路: readme: 需要安装模块: prettytable 测试帐号: 1.后台管理:admin/admin 只设定了这个后台管理帐号,没有写到数据库中 2.学 ...
- Linux使用shell解压tar.Z格式文件
建设当前目录下有一个名为test.tar.Z的文件. 使用如下指令可以将其解压,并将解压后的所有文件放置在当前目录下: zcat test.tar.Z | tar -xvf - 如果想要将解压缩的文件 ...