主要看思路:区域数据去重 + JavaScript一次性展示几万条数据实例代码
近期做1功能,Gis地图 基于百度地图api , 会遇到的问题的,
如后台接口给的数据很多,大几千上万的,如果拿了数据直接渲染dom ,这滋味爽爽的。
再遇上 客户端浏览器悲催的,这卡顿就来了...
前端大量数据渲染的一个弊端。
想到的处理方式:
1. 数据的去重合并
基于当前可是屏幕范围,拿到baidu对应的 经维度区域,baidu api 里有 getBounds 和 getZoom 方法
var viewArea = map.getBounds(); // 可视区域
var mapScale = map.getZoom(); // 地图放大缩小比例
对应后台接口返回数据,要拿基于这个可是区域的维度范围进行返回,
如果回来有万以上,在页面上展示这么多也没实际意义,
前端需要自己进行数据过滤,基于放大缩小比例, 屏幕上返回数据偏差不大的要进行去重 (这个算法就先不细说了)
最先想到的是 2组数据循环对比去重,怎么看都不太对啊,这要数据多了??? 不用想,绝对要挂的节奏....
-------------------------------
和架构师聊了,给了个建议,效率上好很多, 看下图:
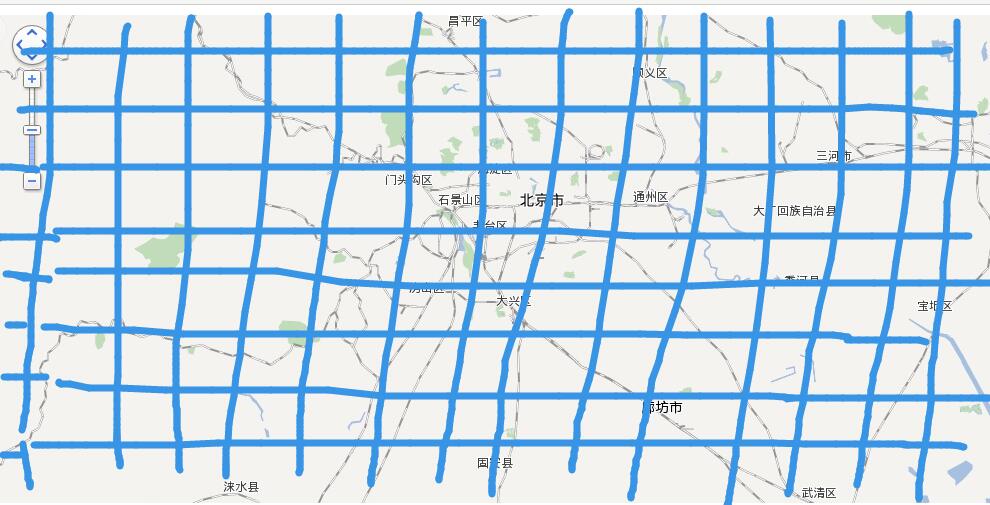
给的思路:
1. 基于区域画格子,算出格子对应的经纬度,构造1个二维数组的数据;
2. 拿到后台返回的数据,循环时,算出在二位数组中对应的位置,如状态为无就认为该条数据有效,更改对应二位数组数据的状态, 如已经有状态了数量丢弃,对应的状态数量+1;
处理出有效的数据......扯的有点远了
2. 数据的分片渲染展示
如果有效数据还是很多,假如有大几千几万的,一次展示全也是苦哈哈的;
处理方式其实也不复杂, 把数据照一定数量进行分块,定时异步展示出;
如有6000条数据, 可照1000条拆成6组, 先拿1组展示,循环定时展示出其他....
思路基本上是这样
更多细节也可参考看到的一文章, 里面有个保持数据插入的次序不错,可作参考
JavaScript一次性展示几万条数据实例代码: http://www.php.cn/js-tutorial-360591.html
主要看思路:区域数据去重 + JavaScript一次性展示几万条数据实例代码的更多相关文章
- JavaScript如何一次性展示几万条数据
有一位同事跟大家说他在网上看到一道面试题:“如果后台传给前端几万条数据,前端怎么渲染到页面上?”,如何回答? 于是办公室沸腾了, 同事们讨论开了, 你一言我一语说出自己的方案. 有的说直接循环遍历生成 ...
- 最短时间(几秒内)利用C#往SQLserver数据库一次性插入10万条数据
用途说明: 公司要求做一个数据导入程序,要求将Excel数据,大批量的导入到数据库中,尽量少的访问数据库,高性能的对数据库进行存储.于是在网上进行查找,发现了一个比较好的解决方案,就是采用SqlBul ...
- QTreeView处理大量数据(使用1000万条数据,每次都只是部分刷新)
如何使QTreeView快速显示1000万条数据,并且内存占用量少呢?这个问题困扰我很久,在网上找了好多相关资料,都没有找到合理的解决方案,今天在这里把我的解决方案提供给朋友们,供大家相互学习. 我开 ...
- 性能优化:虚拟列表,如何渲染10万条数据的dom,页面同时不卡顿
列表大概有2万条数据,又不让做成分页,如果页面直接渲染2万条数据,在一些低配电脑上可能会照成页面卡死,基于这个需求,我们来手写一个虚拟列表 思路 列表中固定只显示少量的数据,比如60条 在列表滚动的时 ...
- 极限挑战—C#+ODP 100万条数据导入Oracle数据库仅用不到1秒
链接地址:http://www.cnblogs.com/armyfai/p/4646213.html 要:在这里我们将看到的是C#中利用ODP实现在Oracle数据库中瞬间导入百万级数据,这对快速批量 ...
- (转)Python网络爬虫实战:世纪佳缘爬取近6万条数据
又是一年双十一了,不知道从什么时候开始,双十一从“光棍节”变成了“双十一购物狂欢节”,最后一个属于单身狗的节日也成功被攻陷,成为了情侣们送礼物秀恩爱的节日. 翻着安静到死寂的聊天列表,我忽然惊醒,不行 ...
- 绝对干货,教你4分钟插入1000万条数据到mysql数据库表,快快进来
我用到的数据库为,mysql数据库5.7版本的 1.首先自己准备好数据库表 其实我在插入1000万条数据的时候遇到了一些问题,现在先来解决他们,一开始我插入100万条数据时候报错,控制台的信息如下: ...
- Qt中提高sqlite的读写速度(使用事务一次性写入100万条数据)
SQLite数据库本质上来讲就是一个磁盘上的文件,所以一切的数据库操作其实都会转化为对文件的操作,而频繁的文件操作将会是一个很好时的过程,会极大地影响数据库存取的速度.例如:向数据库中插入100万条数 ...
- 使用hibernate在5秒内插入11万条数据,你觉得可能吗?
需求是这样的,需要查询某几个表的数据,然后插入到另外一个表. 一看到需求,很多人都会用hibernate去把这些数据都查询出来,然后放到list中, 然后再用for循环之类的进行遍历,一条一条的取出数 ...
随机推荐
- c/c++ int,float,short 大小端转换函数
unsigned int(uint32_t)大小端转换函数 unsigned int BLEndianUint32(unsigned int value) { return ((value & ...
- 【性能测试】:关于测试F5负载均衡的问题
在压测过程中,前置分发机的请求分发策略有多种,轮询,随机,DNS均衡,最小连接数等 问题出现的前提:因测试的一个系统对用户安全性校验较强,例如做交易之前,需要验证用户安全信息等 问题出现的现象:当lo ...
- 【Vue】环境搭建、项目创建及运行
一.软件下载 1. 进入官网https://nodejs.org/en/下周node.js,傻瓜式安装步骤(一直下一步就好) 2. 进入官网http://www.dcloud.io/下载并安装编辑器H ...
- 新创建的数据库,执行db2look时,遇到package db2lkfun.bnd bind failed
在新创建的数据库中,执行db2look的时候,存在这样的问题 db2v97i1@oc0644314035 ~]$ db2look -d sample -e -l -o db2look.ddl -- N ...
- spring boot快速入门 3: controller的使用
模版引擎的使用: 第一步:在POM文件添加配置 <!-- 模版引擎 --> <dependency> <groupId>org.springframework.bo ...
- [问题解决]gradle编译失败系统找不到指定的文件
[问题解决]gradle编译失败系统找不到指定的文件 问题描述 Error:C:\Users\diql.gradle\caches\2.14.1\scripts-remapped\settings_9 ...
- Javac源码解读-书目录
1.Javac编译器 (1)Javac编译器介绍(主要介绍如何从java源代码到class的一个转换过程) (2)Javac的源码(说明其中哪个功能由哪个主要的类来完成) (3)Javac支持的命令及 ...
- 很乱,临时保存,自定义v-model
<!DOCTYPE html> <html> <head> <meta charset="utf-8"> <meta name ...
- erlang尾递归练习
1 %%计算链表长度尾递归实现 2 lez(N) -> lez(N, 0). 3 4 lez([], Acc) -> Acc; 5 lez([_ | T], Acc) -> lez( ...
- git删除远程主机没有的tag
可以先删除所有本地tag,然后再拉取远程上的tag git tag -l | xargs git tag -d git fetch --tags 其他方法以及查询tag的命令请见:Remove loc ...