python爬虫之分析Ajax请求抓取抓取今日头条街拍美图(七)
python爬虫之分析Ajax请求抓取抓取今日头条街拍美图
一、分析网站
1.进入浏览器,搜索今日头条,在搜索栏搜索街拍,然后选择图集这一栏。
2.按F12打开开发者工具,刷新网页,这时网页回弹到综合这一栏,点击图集,在开发者工具中查看 XHR这个选项卡。
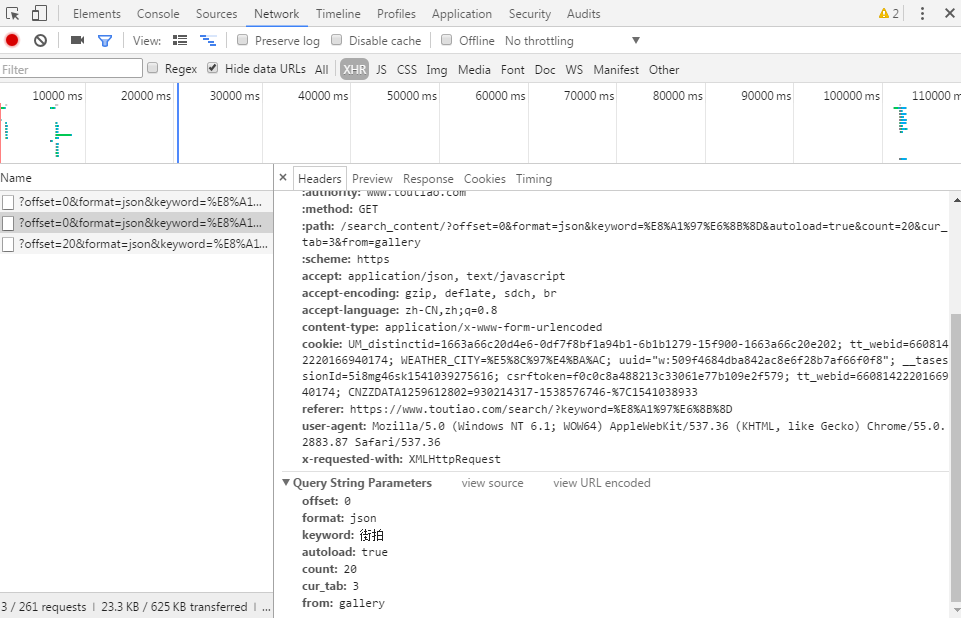
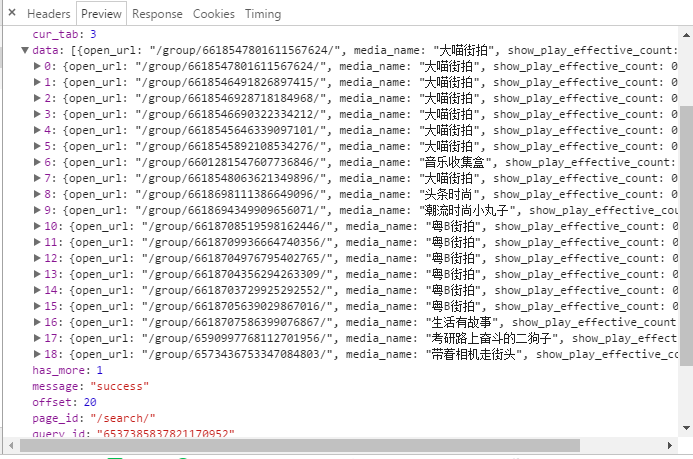
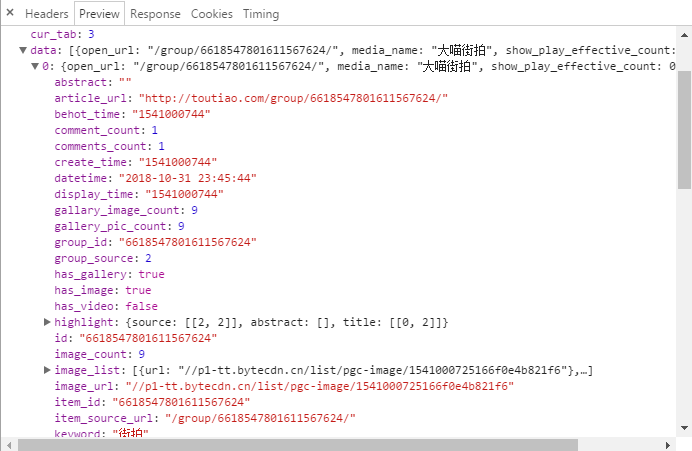
3.具体分析url,请求参数
当我们在请求图集这个页面时,url如下:

请求参数如下:
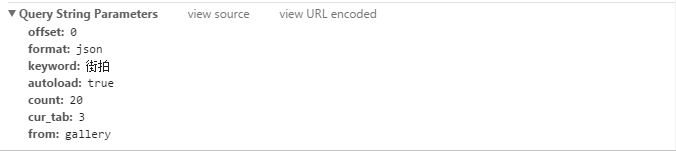
我们可以看到这个url的构成:
前面:https://www.toutiao.com/search_content/?
后面:offset=0&format=json&keyword=%E8%A1%97%E6%8B%8D&autoload=true&count=20&cur_tab=3&from=gallery
二、源代码
程序主体
import requests
from urllib.parse import urlencode
from requests.exceptions import RequestException
import json
import re
import os
import pymongo
from hashlib import md5
from bs4 import BeautifulSoup
from multiprocessing import Pool
from config import * #导入mongodb
client = pymongo.MongoClient(MOMGO_URL,connect=False)
#创建数据库对象
db = client[MOMGO_DB] #获取索引页内容
def get_page_index(offset,keyword):
#构造请求参数
data ={
'offset':offset,
'format':'json',
'keyword':keyword,
'autoload':'true',
'count':'20',
'cur_tab':'3',
'from':'gallery',
}
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64; Trident/7.0; rv:11.0) like Gecko'}
#请求url, urlencode()将字典数据转为url请求
url = 'https://www.toutiao.com/search_content/?' + urlencode(data) try:
response = requests.get(url,headers=headers)
if response.status_code ==200:
return response.text
return None
except RequestException:
print('请求页出错')
return None #解析索引网页,获得详细页面url
def parse_page_index(html):
#解析json数据,转为json对象
data = json.loads(html)
#判断data是否存在,存在则返回所有的键名
if data and 'data' in data.keys():
for item in data.get('data'):
#提取article_url,把article_url循环取出来
yield item.get('article_url') #获取详细页面内容
def get_page_detail(url):
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 Safari/537.36 QIHU 360SE'}
try:
response = requests.get(url,headers=headers)
if response.status_code == 200:
return response.text
return None
except RequestException:
print('请求详细页出错')
return None #解析详细页面内容
def parse_page_Detail(html,url):
#生成BeautifulSoup对象,使用lxml解析
soup = BeautifulSoup(html,'lxml')
#匹配标题
title_pattern = re.compile('BASE_DATA.galleryInfo = {.*?title: (.*?),',re.S)
#匹配图片
images_pattern = re.compile('BASE_DATA.galleryInfo = {.*?gallery: JSON.parse\("(.*?)"\)',re.S)
result =re.search(images_pattern,html)
title = re.search(title_pattern,html)
if result:
data =json.loads(result.group(1).replace('\\',''))
#如果sub_images存在,返回所有键名
if data and 'sub_images' in data.keys():
#获取sub_images的所有内容
sub_images = data.get('sub_images')
#获取一组图,构造列表
images = [item.get('url') for item in sub_images]
#下载图片,保存图片
for image in images: down_images(image)
return {
'title':title.group(1),
'url':url,
'images':images
} def save_to_mongo(result):
if db[MOMG_TABLE].insert(result):
print('存储到mongodb成功')
return True
return False #下载图片
def down_images(url):
print('正在下载图片:'+ url)
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 Safari/537.36 QIHU 360SE'}
try:
response = requests.get(url,headers=headers)
if response.status_code == 200:
sava_images(response.content)
return None
except RequestException:
print('请求图片出错')
return None #保存图片
def sava_images(content):
file_path = "{0}/{1}.{2}".format(os.getcwd(),md5(content).hexdigest(),'jpg')
if not os.path.exists(file_path):
with open(str(file_path),'wb') as f:
f.write(content)
f.close() def main(offset):
#获取索引页内容
#传入第一个变量为offset值,第二个为关键字,网页通过滑动,offset值会发生改变
html = get_page_index(offset,KEYWORD)
#解析索引页内容,获取详细页面URL
for url in parse_page_index(html):
#将详细页面内容赋值给html
html = get_page_detail(url)
#如果详细页面内容不为空,则解析详细内容
if html:
result = parse_page_Detail(html,url)
print(result)
if result:
save_to_mongo(result) if __name__=='__main__': groups = [x * 20 for x in range(GROUP_START,GROUP_END + 1)]
#创建进程池
pool=Pool()
#开启多进程
pool,map(main(offset=0), groups)
配置文件
#链接地址
MOMGO_URL='localhost'
#数据库名字
MOMGO_DB='toutiao'
#表名
MOMG_TABLE='toutiao' GROUP_START=1
GROUP_END=20
KEYWORD="街拍"
python爬虫之分析Ajax请求抓取抓取今日头条街拍美图(七)的更多相关文章
- 15-分析Ajax请求并抓取今日头条街拍美图
流程框架: 抓取索引页内容:利用requests请求目标站点,得到索引网页HTML代码,返回结果. 抓取详情页内容:解析返回结果,得到详情页的链接,并进一步抓取详情页的信息. 下载图片与保存数据库:将 ...
- Python Spider 抓取今日头条街拍美图
""" 抓取今日头条街拍美图 """ import os import time import requests from hashlib ...
- 分析Ajax请求并抓取今日头条街拍美图
项目说明 本项目以今日头条为例,通过分析Ajax请求来抓取网页数据. 有些网页请求得到的HTML代码里面并没有我们在浏览器中看到的内容.这是因为这些信息是通过Ajax加载并且通过JavaScript渲 ...
- 【Python3网络爬虫开发实战】 分析Ajax爬取今日头条街拍美图
前言本文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理.作者:haoxuan10 本节中,我们以今日头条为例来尝试通过分析Ajax请求 ...
- 【Python3网络爬虫开发实战】6.4-分析Ajax爬取今日头条街拍美图【华为云技术分享】
[摘要] 本节中,我们以今日头条为例来尝试通过分析Ajax请求来抓取网页数据的方法.这次要抓取的目标是今日头条的街拍美图,抓取完成之后,将每组图片分文件夹下载到本地并保存下来. 1. 准备工作 在本节 ...
- 转:【Python3网络爬虫开发实战】6.4-分析Ajax爬取今日头条街拍美图
[摘要] 本节中,我们以今日头条为例来尝试通过分析Ajax请求来抓取网页数据的方法.这次要抓取的目标是今日头条的街拍美图,抓取完成之后,将每组图片分文件夹下载到本地并保存下来. 1. 准备工作 在本节 ...
- 爬虫(八):分析Ajax请求抓取今日头条街拍美图
(1):分析网页 分析ajax的请求网址,和需要的参数.通过不断向下拉动滚动条,发现请求的参数中offset一直在变化,所以每次请求通过offset来控制新的ajax请求. (2)上代码 a.通过aj ...
- 2.分析Ajax请求并抓取今日头条街拍美图
import requests from urllib.parse import urlencode # 引入异常类 from requests.exceptions import RequestEx ...
- 分析 ajax 请求并抓取今日头条街拍美图
首先分析街拍图集的网页请求头部: 在 preview 选项卡我们可以找到 json 文件,分析 data 选项,找到我们要找到的图集地址 article_url: 选中其中一张图片,分析 json 请 ...
随机推荐
- Linux下创建C函数库
http://blog.163.com/hitperson@126/blog/static/130245975201151552938133 http://blog.sina.com.cn/s/blo ...
- 列式数据库~clickhouse 副本集架构的搭建
clickhouse 搭建副本集 一 原理: 1 依赖ZK,ZK的基础上,ZK存储数据库元数据 2 使用复制表引擎创建复制表,包括ZK路径和副本名,相同ZK路径的表可以相互复制 3 复制表本身拥 ...
- Android的网络通信机制
1. Socket接口 不常用 2.HttpURLConnection接口 3. HttpClient接口 http://blog.csdn.net/ccc20134/article/details/ ...
- C语言中malloc函数返回值是否需要类型强制转换问题
1. 在C语言中, 如果调用的函数没有函数原型, 则其返回值将默认为 int 型. 考虑调用malloc函数时忘记了 #include <stdlib.h>的情况 此时malloc函数返回 ...
- WPF开发中的多线程的问题
今天帮助同事做了一个WPF版的多线程demo,分享给大家. 要实现的问题就是非主线程thread1 去后台不停的取新数据,当有新数据的时候就会展示到前台. 我给他做的demo实现一个按秒的计数器,随着 ...
- javascript中cookie常用操作
//写cookies function setCookie(c_name, value, expiredays){ var exdate=new Date(); exdate.setTime(exda ...
- BZOJ 3498: PA2009 Cakes 一类经典的三元环计数问题
首先引入一个最常见的经典三元环问题. #include <bits/stdc++.h> using namespace std; const int maxn = 100005; vect ...
- OCM_第一天课程:OCM课程环境搭建
注:本文为原著(其内容来自 腾科教育培训课堂).阅读本文注意事项如下: 1:所有文章的转载请标注本文出处. 2:本文非本人不得用于商业用途.违者将承当相应法律责任. 3:该系列文章目录列表: 一:&l ...
- TLiteSQLMonitor 使用方法
- (四)CXF处理JavaBean以及复合类型
前面讲的是处理简单类型,今天这里来讲下CXF处理JavaBean以及复合类型,比如集合: 这里实例是客户端传一个JavaBean,服务器端返回集合类型: 在原来的项目实例基础上,我们先创建一个实体类U ...